This paper investigates iterative learning control for Caputo fractional-order systems with one-sided Lipschitz nonlinearity. Both open- and closed-loop P-type learning algorithms are proposed to achieve perfect tracking for the desired trajectory, and their convergence conditions are established. It is shown that the algorithms can make the output tracking error converge to zero along the iteration axis. A simulation example illustrates the application of the theoretical findings, and shows the effectiveness of the proposed approach.
Citation: Hanjiang Wu, Jie Huang, Kehan Wu, António M. Lopes, Liping Chen. Precise tracking control via iterative learning for one-sided Lipschitz Caputo fractional-order systems[J]. Mathematical Biosciences and Engineering, 2024, 21(2): 3095-3109. doi: 10.3934/mbe.2024137
This paper investigates iterative learning control for Caputo fractional-order systems with one-sided Lipschitz nonlinearity. Both open- and closed-loop P-type learning algorithms are proposed to achieve perfect tracking for the desired trajectory, and their convergence conditions are established. It is shown that the algorithms can make the output tracking error converge to zero along the iteration axis. A simulation example illustrates the application of the theoretical findings, and shows the effectiveness of the proposed approach.

| [1] |
A. Maachou, R. Malti, P. Melchior, J. L. Battagliaand, A. Oustaloup, Nonlinear thermal system identification using fractional Volterra series, Control Eng. Pract., 29 (2014), 50–60. https://doi.org/10.1016/j.conengprac.2014.02.023 doi: 10.1016/j.conengprac.2014.02.023

|
| [2] |
P. E. Jacob, S. M. M. Alavi, A. Mahdi, S. J. Payne, D. A. Howey, Bayesian inference in non-Markovian state-space models with applications to battery fractional-order systems, IEEE Trans. Control Syst. Technol., 26 (2018), 497–506. https://doi.org/10.1109/TCST.2017.2672402 doi: 10.1109/TCST.2017.2672402
|
| [3] |
G. Tsirimokou, C. Psychalinos, A. S. Elwakil, K. N. Salama, Electronically tunable fully integrated fractional-order resonator, IEEE Trans. Circuits Syst. II Express Briefs, 65 (2018), 166–170. https://doi.org/10.1109/TCSII.2017.2684710 doi: 10.1109/TCSII.2017.2684710
|
| [4] |
E. S. A. Shahri, A. Alfi, J. A. T. Machado, Lyapunov method for the stability analysis of uncertain fractional-order systems under input saturation, Appl. Math. Modell., 81 (2020), 663–672. https://doi.org/10.1016/j.apm.2020.01.013 doi: 10.1016/j.apm.2020.01.013
|
| [5] |
C. Hou, X. Liu, H. Wang, Adaptive fault tolerant control for a class of uncertain fractional-order systems based on disturbance observer, Int. J. Robust Nonlinear Control, 30 (2020), 3436–3450. https://doi.org/10.1002/rnc.4950 doi: 10.1002/rnc.4950
|
| [6] |
S. Kamal, R. K. Sharma, T. N. Dinh, H. MS, B. Bandyopadhyay, Sliding mode control of uncertain fractional-order systems: A reaching phase free approach, Asian J. Control, 23 (2021), 199–208. https://doi.org/10.1002/asjc.2223 doi: 10.1002/asjc.2223
|
| [7] | J. X. Xu, Y. Tan, Linear and Nonlinear Iterative Learning Control, Springer-Verlag, Berlin, 2003. https://doi.org/10.1007/3-540-44845-4 |
| [8] | Y. Q. Chen, K. L. Moore, On D$^\alpha$-type iterative learning control, in Proceedings of the 40th IEEE Conference on Decision and Control, IEEE, (2001), 4451–4456. https://doi.org/10.1109/CDC.2001.980903 |
| [9] | Y. Li, H. S. Ahn, Y. Q. Chen, Iterative learning control of a class of fractional order nonlinear systems, in Proceedings of the 2010 IEEE International Symposium on Intelligent Control, IEEE, (2010), 779–782. https://doi.org/10.1109/ISIC.2010.5612935 |
| [10] |
Y. H. Lan, Iterative learning control with initial state learning for fractional order nonlinear systems, Comput. Math. Appl., 64 (2012), 3210–3216. https://doi.org/10.1016/j.camwa.2012.03.086 doi: 10.1016/j.camwa.2012.03.086
|
| [11] |
Y. Li, W. Jiang, Fractional order nonlinear systems with delay initerative learning control, Appl. Math. Comput., 257 (2015), 546–552. https://doi.org/10.1016/j.amc.2015.01.014 doi: 10.1016/j.amc.2015.01.014
|
| [12] |
L. Li, Lebesgue-p norm convergence of fractional-order PID-type iterative learning control for linear systems, Asian J. Control, 20 (2018), 483–494. https://doi.org/10.1002/asjc.1561 doi: 10.1002/asjc.1561
|
| [13] |
S. Liu, J. R. Wang, Fractional order iterative learning control with randomly varying trial lengths, J. Franklin Inst., 354 (2017), 967–992. https://doi.org/10.1016/j.jfranklin.2016.11.004 doi: 10.1016/j.jfranklin.2016.11.004
|
| [14] |
D. Luo, J. R. Wang, D. Shen, PD$^\alpha$-type distributed learning control for nonlinear fractional-order multiagent systems, Math. Methods Appl. Sci., 42 (2019), 4543–4553. https://doi.org/10.1002/mma.5677 doi: 10.1002/mma.5677
|
| [15] |
D. Luo, J. R. Wang, D. Shen, Iterative learning control for locally Lipschitz nonlinear fractional-order multi-agent systems, J. Franklin Inst., 357 (2020), 6671–6693. https://doi.org/10.1016/j.jfranklin.2020.04.032 doi: 10.1016/j.jfranklin.2020.04.032
|
| [16] |
J. Zhang, D. Meng, Convergence analysis of saturated iterative learning control systems with locally Lipschitz nonlinearities, IEEE Trans. Neural Networks Learn. Syst., 31 (2020), 4025–4035. https://doi.org/10.1109/TNNLS.2019.2951752 doi: 10.1109/TNNLS.2019.2951752
|
| [17] |
D. Meng, K. L. Moore, Contraction mapping-based robust convergence of iterative learning control with uncertain, locally-Lipschitz nonlinearity, IEEE Trans. Syst. Man Cybern.: Syst., 50 (2020), 442–454. https://doi.org/10.1109/TSMC.2017.2780131 doi: 10.1109/TSMC.2017.2780131
|
| [18] |
S. He, H. Fang, M. Zhang, F. Liu, Z. Ding, Adaptive optimal control for a class of nonlinear systems: the online policy iteration approach, IEEE Trans. Neural Networks Learn. Syst., 31 (2020), 549–558. https://doi.org/10.1109/TNNLS.2019.2905715 doi: 10.1109/TNNLS.2019.2905715
|
| [19] |
H. Fang, M. Zhang, S. He, X. Luan, F. Liu, Z. Ding, Solving the zero-sum control problem for tidal turbine system: an online reinforcement learning approach, IEEE Trans. Cybern., 53 (2023), 7635–7647. https://doi.org/10.1109/TCYB.2022.3186886 doi: 10.1109/TCYB.2022.3186886
|
| [20] |
S. Raghavan, J. K. Hedrick, Observer design for a class of nonlinear systems, Int. J. Control, 59 (1994), 515–528. https://doi.org/10.1080/00207179408923090 doi: 10.1080/00207179408923090
|
| [21] |
W. Yu, P. DeLellis, G. Chen, M. di Bernardo, J. Kurths, Distributed adaptive control of synchronization in complex networks, IEEE Trans. Autom. Control, 57 (2012), 2153–2158. https://doi.org/10.1109/TAC.2012.2183190 doi: 10.1109/TAC.2012.2183190
|
| [22] |
M. Hussain, M. Rehan, C. K. Ahn, M. Tufail, Robust antiwindup for one-sided Lipschitz systems subject to input saturation and applications, IEEE Trans. Ind. Electron., 65 (2018), 9706–9716. https://doi.org/10.1109/TIE.2018.2815950 doi: 10.1109/TIE.2018.2815950
|
| [23] |
G. Hu, Observers for one-sided Lipschitz non-linear systems, IMA J. Math. Control Inf., 23 (2006), 395–401. https://doi.org/10.1093/imamci/dni068 doi: 10.1093/imamci/dni068
|
| [24] |
M. Xu, G. Hu, Y. Zhao, Reduced-order observer for one-sided Lipschitz nonlinear systems, IMA J. Math. Control Inf., 26 (2009), 299–317. https://doi.org/10.1093/imamci/dnp017 doi: 10.1093/imamci/dnp017
|
| [25] |
Y. Zhao, J. Tao, N. Z. Shi, A note on observer design for one-sided Lipschitz nonlinear systems, Syst. Control Lett., 59 (2010), 66–71. https://doi.org/10.1016/j.sysconle.2009.11.009 doi: 10.1016/j.sysconle.2009.11.009
|
| [26] | M. Abbaszadeh, H. Marquez, Nonlinear observer design for one-sided Lipschitz systems, in Proceedings of the 2010 American Control Conference, IEEE, (2010), 5284–5289. https://doi.org/10.1109/ACC.2010.5530715 |
| [27] |
W. Zhang, H. Su, H. Wang, Z. Han, Full-order and reduced-order observers for one-sided lipschitz nonlinear systems using Riccati equations, Commun. Nonlinear Sci. Numer. Simul., 17 (2012), 4968–4977. https://doi.org/10.1016/j.cnsns.2012.05.027 doi: 10.1016/j.cnsns.2012.05.027
|
| [28] |
W. Zhang, H. Su, F. Zhu, S. P. Bhattacharyya, Improved exponential observer design for one-sided Lipschitz nonlinear systems, Int. J. Robust Nonlinear Control, 26 (2016), 3958–3973. https://doi.org/10.1002/rnc.3543 doi: 10.1002/rnc.3543
|
| [29] |
X. Cai, H. Gao, L. Liu, W. Zhang, Control design for one-sided Lipschitz nonlinear differential inclusions, ISA Trans., 53 (2014), 298–304. https://doi.org/10.1016/j.isatra.2013.12.005 doi: 10.1016/j.isatra.2013.12.005
|
| [30] |
W. Saad, A. Sellami, G. Garcia, $H_\infty$ control for uncertain one-sided Lipschitz nonlinear systems in finite frequency domain, Int. J. Robust Nonlinear Control, 30 (2020), 5712–5727. https://doi.org/10.1002/rnc.5101 doi: 10.1002/rnc.5101
|
| [31] |
J. Ren, J. Sun, J. Fu, Finite-time event-triggered sliding mode control for one-sided Lipschitz nonlinear systems with uncertainties, Nonlinear Dyn., 103 (2021), 865–882. https://doi.org/10.1007/s11071-020-06096-2 doi: 10.1007/s11071-020-06096-2
|
| [32] |
R. Agha, M. Rehan, C. K. Ahn, G. Mustafa, S. Ahmad, Adaptive distributed consensus control of one-sided Lipschitz nonlinear multiagents, IEEE Trans. Syst. Man Cybern.: Syst., 49 (2019), 568–578. https://doi.org/10.1109/TSMC.2017.2764521 doi: 10.1109/TSMC.2017.2764521
|
| [33] |
M. A. Razaq, M. Rehan, M. Tufail, C. K. Ahn, Multiple Lyapunov functions approach for consensus of one-sided Lipschitz multi-agents over switching topologies and input saturation, IEEE Trans. Circuits Syst. II Express Briefs, 67 (2020), 3267–3271. https://doi.org/10.1109/TCSII.2020.2986009 doi: 10.1109/TCSII.2020.2986009
|
| [34] |
P. Gu, S. Tian, Analysis of iterative learning control for one-sided Lipschitz nonlinear singular systems, J. Franklin Inst., 356 (2019), 196–208. https://doi.org/10.1016/j.jfranklin.2018.10.014 doi: 10.1016/j.jfranklin.2018.10.014
|
| [35] |
P. Gu, S. Tian, D-type iterative learning control for one-sided Lipschitz nonlinear systems, Int. J. Robust Nonlinear Control, 29 (2019), 2546–2560. https://doi.org/10.1002/rnc.4511 doi: 10.1002/rnc.4511
|
| [36] |
P. Gu, S. Tian, P-type iterative learning control with initial state learning for one-sided Lipschitz nonlinear systems, Int. J. Control Autom. Syst., 17 (2019), 2203–2210. https://doi.org/10.1007/s12555-018-0891-2 doi: 10.1007/s12555-018-0891-2
|
| [37] | I. Podlubny, Fractional Differential Equations, Academic Press, New York, 1999. |
| [38] |
M. A. Duarte-Mermoud, N. Aguila-Camacho, J. A. Gallegos, R. Castro-Linares, Using general quadratic Lyapunov functions to prove Lyapunov uniform stability for fractional order systems, Commun. Nonlinear Sci. Numer. Simul., 22 (2015), 650–659. https://doi.org/10.1016/j.cnsns.2014.10.008 doi: 10.1016/j.cnsns.2014.10.008
|
| [39] |
Y. H. Lan, Y. Zhou, Non-fragile observer-based robust control for a class of fractional-order nonlinear systems, Syst. Control Lett., 62 (2013), 1143–1150. https://doi.org/10.1016/j.sysconle.2013.09.007 doi: 10.1016/j.sysconle.2013.09.007
|
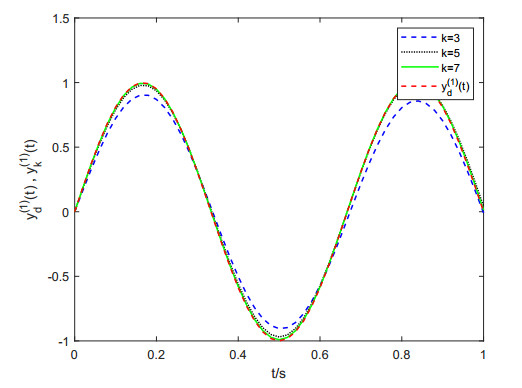





Figures(6)

Hanjiang Wu, Jie Huang, Kehan Wu, António M. Lopes, Liping Chen. Precise tracking control via iterative learning for one-sided Lipschitz Caputo fractional-order systems[J]. Mathematical Biosciences and Engineering, 2024, 21(2): 3095-3109. doi: 10.3934/mbe.2024137







 DownLoad:
DownLoad: