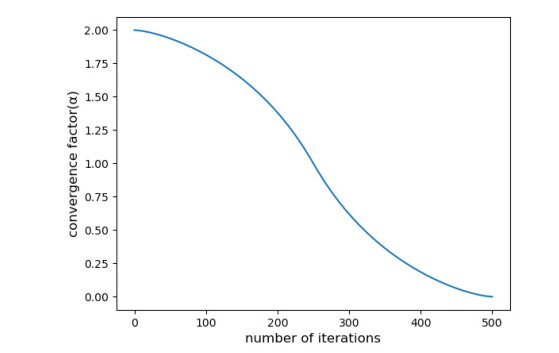
The grey wolf optimization algorithm (GWO) is a new metaheuristic algorithm. The GWO has the advantages of simple structure, few parameters to adjust, and high efficiency, and has been applied in various optimization problems. However, the orginal GWO search process is guided entirely by the best three wolves, resulting in low population diversity, susceptibility to local optima, slow convergence rate, and imbalance in development and exploration. In order to address these shortcomings, this paper proposes an adaptive dynamic self-learning grey wolf optimization algorithm (ASGWO). First, the convergence factor was segmented and nonlinearized to balance the global search and local search of the algorithm and improve the convergence rate. Second, the wolves in the original GWO approach the leader in a straight line, which is too simple and ignores a lot of information on the path. Therefore, a dynamic logarithmic spiral that nonlinearly decreases with the number of iterations was introduced to expand the search range of the algorithm in the early stage and enhance local development in the later stage. Then, the fixed step size in the original GWO can lead to algorithm oscillations and an inability to escape local optima. A dynamic self-learning step size was designed to help the algorithm escape from local optima and prevent oscillations by reasonably learning the current evolution success rate and iteration count. Finally, the original GWO has low population diversity, which makes the algorithm highly susceptible to becoming trapped in local optima. A novel position update strategy was proposed, using the global optimum and randomly generated positions as learning samples, and dynamically controlling the influence of learning samples to increase population diversity and avoid premature convergence of the algorithm. Through comparison with traditional algorithms, such as GWO, PSO, WOA, and the new variant algorithms EOGWO and SOGWO on 23 classical test functions, ASGWO can effectively improve the convergence accuracy and convergence speed, and has a strong ability to escape from local optima. In addition, ASGWO also has good performance in engineering problems (gear train problem, ressure vessel problem, car crashworthiness problem) and feature selection.
Citation: Yijie Zhang, Yuhang Cai. Adaptive dynamic self-learning grey wolf optimization algorithm for solving global optimization problems and engineering problems[J]. Mathematical Biosciences and Engineering, 2024, 21(3): 3910-3943. doi: 10.3934/mbe.2024174
The grey wolf optimization algorithm (GWO) is a new metaheuristic algorithm. The GWO has the advantages of simple structure, few parameters to adjust, and high efficiency, and has been applied in various optimization problems. However, the orginal GWO search process is guided entirely by the best three wolves, resulting in low population diversity, susceptibility to local optima, slow convergence rate, and imbalance in development and exploration. In order to address these shortcomings, this paper proposes an adaptive dynamic self-learning grey wolf optimization algorithm (ASGWO). First, the convergence factor was segmented and nonlinearized to balance the global search and local search of the algorithm and improve the convergence rate. Second, the wolves in the original GWO approach the leader in a straight line, which is too simple and ignores a lot of information on the path. Therefore, a dynamic logarithmic spiral that nonlinearly decreases with the number of iterations was introduced to expand the search range of the algorithm in the early stage and enhance local development in the later stage. Then, the fixed step size in the original GWO can lead to algorithm oscillations and an inability to escape local optima. A dynamic self-learning step size was designed to help the algorithm escape from local optima and prevent oscillations by reasonably learning the current evolution success rate and iteration count. Finally, the original GWO has low population diversity, which makes the algorithm highly susceptible to becoming trapped in local optima. A novel position update strategy was proposed, using the global optimum and randomly generated positions as learning samples, and dynamically controlling the influence of learning samples to increase population diversity and avoid premature convergence of the algorithm. Through comparison with traditional algorithms, such as GWO, PSO, WOA, and the new variant algorithms EOGWO and SOGWO on 23 classical test functions, ASGWO can effectively improve the convergence accuracy and convergence speed, and has a strong ability to escape from local optima. In addition, ASGWO also has good performance in engineering problems (gear train problem, ressure vessel problem, car crashworthiness problem) and feature selection.

| [1] | F. Jiang, L. Wang, L. Bai, An adaptive evolutionary whale optimization algorithm, in 2021 33rd Chinese Control and Decision Conference (CCDC), (2021), 4610–4614. https://doi.org/10.1109/CCDC52312.2021.9601898 |
| [2] | J. Kennedy, R. Eberhart, Particle swarm optimization, in Proceedings of ICNN'95-international conference on neural networks, 4 (1995), 1942–1948. https://doi.org/10.1109/ICNN.1995.488968 |
| [3] |
S. Mirjalili, A. Lewis, The whale optimization algorithm, Adv. Eng. Software, 95 (2016), 51–67. https://doi.org/10.1016/j.advengsoft.2016.01.008 doi: 10.1016/j.advengsoft.2016.01.008

|
| [4] |
S. Mirjalili, The ant lion optimizer, Adv. Eng. Software, 83 (2015), 80–98. https://doi.org/10.1016/j.advengsoft.2015.01.010 doi: 10.1016/j.advengsoft.2015.01.010
|
| [5] |
S. Mirjalili, S. M. Mirjalili, A. Lewis, Grey wolf optimizer, Adv. Eng. Software, 69 (2014), 46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007 doi: 10.1016/j.advengsoft.2013.12.007
|
| [6] |
G. M. Komaki, V. Kayvanfar, Grey Wolf Optimizer algorithm for the two-stage assembly flow shop scheduling problem with release time, J. Comput. Sci., 8 (2015), 109–120. https://doi.org/10.1016/j.jocs.2015.03.011 doi: 10.1016/j.jocs.2015.03.011
|
| [7] |
J. Liu, J. Yang, H. Liu, X. Tian, M. Gao, An improved ant colony algorithm for robot path planning, Soft Comput., 21 (2017), 5829–5839. https://doi.org/10.1007/s00500-016-2161-7 doi: 10.1007/s00500-016-2161-7
|
| [8] |
M. H. Sulaiman, Z. Mustaffa, M. R. Mohamed, O. Aliman, Using the gray wolf optimizer for solving optimal reactive power dispatch problem, Appl. Soft Comput., 32 (2015), 286–292. https://doi.org/10.1016/j.asoc.2015.03.041 doi: 10.1016/j.asoc.2015.03.041
|
| [9] |
R. E. Precup, R. C. David, E. M. Petriu, Grey wolf optimizer algorithm-based tuning of fuzzy control systems with reduced parametric sensitivity, IEEE Trans. Ind. Electron., 64 (2016), 527–534. https://doi.org/10.1109/tie.2016.2607698 doi: 10.1109/tie.2016.2607698
|
| [10] |
A. K. M. Khairuzzaman, S. Chaudhury, Multilevel thresholding using grey wolf optimizer for image segmentation, Expert Syst. Appl., 86 (2017), 64–76. https://doi.org/10.1016/j.eswa.2017.04.029 doi: 10.1016/j.eswa.2017.04.029
|
| [11] | R. E. Precup, R. C. David, R. C. Roman, A. I. Szedlak-Stinean, E. M. Petriu, Optimal tuning of interval type-2 fuzzy controllers for nonlinear servo systems using Slime Mould Algorithm Int. J. Syst. Sci., 54 (2023), 2941–2956. https://doi.org/10.1080/00207721.2021.1927236 |
| [12] |
S. Saremi, S. Z. Mirjalili, S. M. Mirjalili, Evolutionary population dynamics and grey wolf optimizer, Neural Comput. Appl., 26 (2015), 1257–1263. https://doi.org/10.1007/s00521-014-1806-7 doi: 10.1007/s00521-014-1806-7
|
| [13] |
C. A. Bojan-Dragos, R. E. Precup, S. Preitl, R. C. Roman, E. L. Hedrea, A. I. Szedlak-Stinean, GWO-based optimal tuning of type-1 and type-2 fuzzy controllers for electromagnetic actuated clutch systems, IFAC-PapersOnLine, 54 (2021), 189–194. https://doi.org/10.1016/j.ifacol.2021.10.032 doi: 10.1016/j.ifacol.2021.10.032
|
| [14] |
S. Wang, Y. Fan, S. Jin, P. Takyi-Aninakwa, C. Fernandez, Improved anti-noise adaptive long short-term memory neural network modeling for the robust remaining useful life prediction of lithium-ion batteries, Reliab. Eng. Syst. Saf., 230 (2023), 108920. https://doi.org/10.1016/j.ress.2022.108920 doi: 10.1016/j.ress.2022.108920
|
| [15] |
S. Wang, F. Wu, P. Takyi-Aninakwa, C. Fernandez, D. I. Stroe, Q. Huang, Improved singular filtering-Gaussian process regression-long short-term memory model for whole-life-cycle remaining capacity estimation of lithium-ion batteries adaptive to fast aging and multi-current variations, Energy, 284 (2023), 128677. https://doi.org/10.1016/j.energy.2023.128677 doi: 10.1016/j.energy.2023.128677
|
| [16] | S. Gottam, S. J. Nanda, R. K. Maddila, A CNN-LSTM model trained with grey wolf optimizer for prediction of household power consumption, in 2021 IEEE International Symposium on Smart Electronic Systems (iSES), (2021), 355–360. https://doi.org/10.1109/iSES52644.2021.00089 |
| [17] |
W. Long, J. Jiao, X. Liang, M. Tang, An exploration-enhanced grey wolf optimizer to solve high-dimensional numerical optimization, Eng. Appl. Artif. Intell., 68 (2018), 63–80. https://doi.org/10.1016/j.engappai.2017.10.024 doi: 10.1016/j.engappai.2017.10.024
|
| [18] |
Z. J. Teng, J. L. Lv, L. W. Guo, An improved hybrid grey wolf optimization algorithm, Soft Comput., 23 (2019), 6617–6631. https://doi.org/10.1007/s00500-018-3310-y doi: 10.1007/s00500-018-3310-y
|
| [19] | A. Kishor, P. K. Singh, Empirical study of grey wolf optimizer, in Proceedings of Fifth International Conference on Soft Computing for Problem solving, (2016), 1037–1049. |
| [20] |
M. Pradhan, P. K. Roy, T. Pal, Oppositional based grey wolf optimization algorithm for economic dispatch problem of power system, Ain Shams Eng. J., 9 (2018), 2015–2025. https://doi.org/10.1016/j.asej.2016.08.023 doi: 10.1016/j.asej.2016.08.023
|
| [21] |
L. Rodriguez, O. Castillo, J. Soria, P. Melin, F. Valdez, C. I. Gonzalez, A fuzzy hierarchical operator in the grey wolf optimizer algorithm, Appl. Soft Comput., 57 (2017), 315–328. https://doi.org/10.1016/j.asoc.2017.03.048 doi: 10.1016/j.asoc.2017.03.048
|
| [22] |
J. Xu, F. Yan, O. G. Ala, L. Su, F. Li, Chaotic dynamic weight grey wolf optimizer for numerical function optimization, J. Intell. Fuzzy Syst., 37 (2019), 2367–2384. https://doi.org/10.3233/jifs-182706 doi: 10.3233/jifs-182706
|
| [23] |
E. Rashedi, H. Nezamabadi-Pour, S. Saryazdi, GSA: a gravitational search algorithm, Inf. Sci., 179 (2009), 2232–2248. https://doi.org/10.1016/j.ins.2009.03.004 doi: 10.1016/j.ins.2009.03.004
|
| [24] |
S. Dhargupta, M. Ghosh, S. Mirjalili, R. Sarkar, Selective opposition based grey wolf optimization, Expert Syst. Appl., 151 (2020), 113389. https://doi.org/10.1016/j.eswa.2020.113389 doi: 10.1016/j.eswa.2020.113389
|
| [25] |
S. Zhang, Q. Luo, Y. Zhou, Hybrid grey wolf optimizer using elite opposition-based learning strategy and simplex method, Int. J. Comput. Intell. Appl., 16 (2017), 1750012. https://doi.org/10.1007/s13042-022-01537-3 doi: 10.1007/s13042-022-01537-3
|
| [26] |
M. A. Navarro, D. Oliva, A. Ramos-Michel, D. Zaldivar, B. Morales-Castaneda, M. Perez-Cisneros, An improved multi-population whale optimization algorithm, Int. J. Mach. Learn. Cybern., 13 (2022), 2447–2478. https://doi.org/10.1007/s13042-022-01537-3 doi: 10.1007/s13042-022-01537-3
|
| [27] |
S. M. Bozorgi, S. Yazdani, IWOA: An improved whale optimization algorithm for optimization problems, J. Comput. Des. Eng., 6 (2019), 243–259. https://doi.org/10.1016/j.jcde.2019.02.002 doi: 10.1016/j.jcde.2019.02.002
|
| [28] | S. A. Rather, N. Sharma, GSA-BBO hybridization algorithm, Int. J. Adv. Res. Sci. Eng., 6 (2017), 596–608. |
| [29] |
V. Muthiah-Nakarajan, M. M. Noel, Galactic swarm optimization: a new global optimization metaheuristic inspired by galactic motion, Appl. Soft Comput., 38 (2016), 771–787. https://doi.org/10.1016/j.asoc.2015.10.034 doi: 10.1016/j.asoc.2015.10.034
|
| [30] |
D. Karaboga, B. Basturk, A powerful and efficient algorithm for numerical function optimization: artificial bee colony (ABC) algorithm, J. Glob. Optim., 39 (2007), 459–471. https://doi.org/10.1007/s10898-007-9149-x doi: 10.1007/s10898-007-9149-x
|
| [31] | E. Cuevas, M. Gonzalez, D. Zaldivar, M. Perez-Cisneros, G. Garcia, An algorithm for global optimization inspired by collective animal behavior, Discrete Dyn. Nat. Soc., 2012 (2012). https://doi.org/10.1155/2012/638275 |
| [32] | X. S. Yang, S. Deb, Cuckoo search via Lévy flights, in 2009 World congress on nature & biologically inspired computing (NaBIC), (2009), 210–214. https://doi.org/10.1109/NABIC.2009.5393690 |
| [33] |
M. A. Diaz-Cortes, E. Cuevas, J. Galvez, O. Camarena, A new metaheuristic optimization methodology based on fuzzy logic, Appl. Soft Comput., 61 (2017), 549–569. https://doi.org/10.1016/j.asoc.2017.08.038 doi: 10.1016/j.asoc.2017.08.038
|
| [34] |
S. Mirjalili, Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm, Knowl. Based Syst., 89 (2015), 228–249. https://doi.org/10.1016/j.knosys.2015.07.006 doi: 10.1016/j.knosys.2015.07.006
|
| [35] |
E. Mezura-Montes, C. A. Coello Coello, An empirical study about the usefulness of evolution strategies to solve constrained optimization problems, Int. J. Gener. Syst., 37 (2008), 443–473. https://doi.org/10.1080/03081070701303470 doi: 10.1080/03081070701303470
|
| [36] |
S. Gupta, K. Deep, H. Moayedi, L. K. Foong, A. Assad, Sine cosine grey wolf optimizer to solve engineering design problems, Eng. Comput., 37 (2021), 3123–3149. https://doi.org/10.1007/s00366-020-00996-y doi: 10.1007/s00366-020-00996-y
|
| [37] | N. Mittal, U. Singh, B. S. Sohi, Modified grey wolf optimizer for global engineering optimization, Appl. Comput. Intell. Soft Comput., 2016 (2016). https://doi.org/10.1155/2016/7950348 |
| [38] |
F. Yan, X. Xu, J. Xu, Grey Wolf Optimizer With a Novel Weighted Distance for Global Optimization, IEEE Access, 8 (2020), 120173–120197. https://doi.org/10.1109/ACCESS.2020.3005182 doi: 10.1109/ACCESS.2020.3005182
|
| [39] |
R. Zheng, H. M. Jia, L. Abualigah, Q. X. Liu, S. Wang, An improved remora optimization algorithm with autonomous foraging mechanism for global optimization problems, Math. Biosci. Eng., 19 (2022), 3994–4037. https://doi.org/10.3934/mbe.2022184 doi: 10.3934/mbe.2022184
|
| [40] |
S. Li, H. Chen, M. Wang, A. A. Heidari, S. Mirjalili, Slime mould algorithm: a new method for stochastic optimization, Future Gener. Comput. Syst, 111 (2020), 300–323. https://doi.org/10.1016/j.future.2020.03.055 doi: 10.1016/j.future.2020.03.055
|
| [41] |
E. H. Houssein, N. Neggaz, M. E. Hosney, W. M. Mohamed, M. Hassaballah, Enhanced Harris hawks optimization with genetic operators for selection chemical descriptors and compounds activities, Neural Comput. Appl., 33 (2021), 13601–13618. https://doi.org/10.1007/s00521-021-05991-y doi: 10.1007/s00521-021-05991-y
|
| [42] |
W. Long, J. Jiao, X. Liang, S. Cai, M. Xu, A random opposition-based learning grey wolf optimizer, IEEE Access, 7 (2019), 113810–113825. https://doi.org/10.1109/ACCESS.2019.2934994 doi: 10.1109/ACCESS.2019.2934994
|
| [43] |
S. Wang, K. Sun, W. Zhang, H. Jia, Multilevel thresholding using a modified ant lion optimizer with opposition-based learning for color image segmentation, Math. Biosci. Eng., 18 (2021), 3092–3143. https://doi.org/10.3934/mbe.2021155 doi: 10.3934/mbe.2021155
|
| [44] |
U. KILIC, E. S. ESSIZ, M. K. KELES, Binary anarchic society optimization for feature selection, Romanian J. Inf. Sci. Technol., 26 (2023), 351–364. https://doi.org/10.1080/00207721.2021.1927236 doi: 10.1080/00207721.2021.1927236
|









Figures(11) / Tables(17)

Yijie Zhang, Yuhang Cai. Adaptive dynamic self-learning grey wolf optimization algorithm for solving global optimization problems and engineering problems[J]. Mathematical Biosciences and Engineering, 2024, 21(3): 3910-3943. doi: 10.3934/mbe.2024174







 DownLoad:
DownLoad: