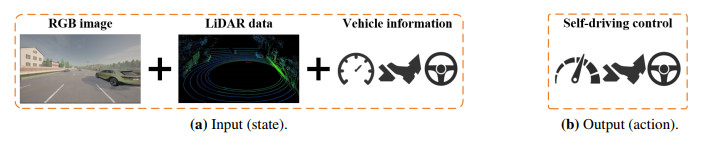
Due to the complexity of the driving environment and the dynamics of the behavior of traffic participants, self-driving in dense traffic flow is very challenging. Traditional methods usually rely on predefined rules, which are difficult to adapt to various driving scenarios. Deep reinforcement learning (DRL) shows advantages over rule-based methods in complex self-driving environments, demonstrating the great potential of intelligent decision-making. However, one of the problems of DRL is the inefficiency of exploration; typically, it requires a lot of trial and error to learn the optimal policy, which leads to its slow learning rate and makes it difficult for the agent to learn well-performing decision-making policies in self-driving scenarios. Inspired by the outstanding performance of supervised learning in classification tasks, we propose a self-driving intelligent control method that combines human driving experience and adaptive sampling supervised actor-critic algorithm. Unlike traditional DRL, we modified the learning process of the policy network by combining supervised learning and DRL and adding human driving experience to the learning samples to better guide the self-driving vehicle to learn the optimal policy through human driving experience and real-time human guidance. In addition, in order to make the agent learn more efficiently, we introduced real-time human guidance in its learning process, and an adaptive balanced sampling method was designed for improving the sampling performance. We also designed the reward function in detail for different evaluation indexes such as traffic efficiency, which further guides the agent to learn the self-driving intelligent control policy in a better way. The experimental results show that the method is able to control vehicles in complex traffic environments for self-driving tasks and exhibits better performance than other DRL methods.
Citation: Jin Zhang, Nan Ma, Zhixuan Wu, Cheng Wang, Yongqiang Yao. Intelligent control of self-driving vehicles based on adaptive sampling supervised actor-critic and human driving experience[J]. Mathematical Biosciences and Engineering, 2024, 21(5): 6077-6096. doi: 10.3934/mbe.2024267
Due to the complexity of the driving environment and the dynamics of the behavior of traffic participants, self-driving in dense traffic flow is very challenging. Traditional methods usually rely on predefined rules, which are difficult to adapt to various driving scenarios. Deep reinforcement learning (DRL) shows advantages over rule-based methods in complex self-driving environments, demonstrating the great potential of intelligent decision-making. However, one of the problems of DRL is the inefficiency of exploration; typically, it requires a lot of trial and error to learn the optimal policy, which leads to its slow learning rate and makes it difficult for the agent to learn well-performing decision-making policies in self-driving scenarios. Inspired by the outstanding performance of supervised learning in classification tasks, we propose a self-driving intelligent control method that combines human driving experience and adaptive sampling supervised actor-critic algorithm. Unlike traditional DRL, we modified the learning process of the policy network by combining supervised learning and DRL and adding human driving experience to the learning samples to better guide the self-driving vehicle to learn the optimal policy through human driving experience and real-time human guidance. In addition, in order to make the agent learn more efficiently, we introduced real-time human guidance in its learning process, and an adaptive balanced sampling method was designed for improving the sampling performance. We also designed the reward function in detail for different evaluation indexes such as traffic efficiency, which further guides the agent to learn the self-driving intelligent control policy in a better way. The experimental results show that the method is able to control vehicles in complex traffic environments for self-driving tasks and exhibits better performance than other DRL methods.

| [1] |
B. R. Kiran, I. Sobh, V. Talpaert, P. Mannion, A. A. A. Sallab, S. Yogamani, et al., Deep reinforcement learning for autonomous driving: A survey, IEEE Trans. Intell. Transp. Syst., 23 (2022), 4909–4926. https://doi.org/10.1109/TITS.2021.3054625 doi: 10.1109/TITS.2021.3054625

|
| [2] | J. Chen, B. Yuan, M. Tomizuka, Model-free deep reinforcement learning for urban autonomous driving, in 2019 IEEE intelligent transportation systems conference (ITSC), (2019), 2765–2771. https://doi.org/10.1109/ITSC.2019.8917306 |
| [3] |
M. Panzer, B. Bender, Deep reinforcement learning in production systems: a systematic literature review, Int. J. Prod. Res., 60 (2022), 4316–4341. https://doi.org/10.1080/00207543.2021.1973138 doi: 10.1080/00207543.2021.1973138
|
| [4] |
N. Ma, Y. Gao, J. Li, D. Li, Interactive cognition in self-driving, Sci. Sin. Inf., 48 (2018), 1083–1096. https://doi.org/10.1360/N112018-00028 doi: 10.1360/N112018-00028
|
| [5] |
H. Shi, D. Chen, N. Zheng, X. Wang, Y. Zhou, B. Ran, A deep reinforcement learning based distributed control strategy for connected automated vehicles in mixed traffic platoon, Transp. Res. Part C: Emerging Technol., 148 (2023), 104019. https://doi.org/10.1016/j.trc.2023.104019 doi: 10.1016/j.trc.2023.104019
|
| [6] | Y. Zhao, K. Wu, Z. Xu, Z. Che, Q. Lu, J. Tang, et al., Cadre: A cascade deep reinforcement learning framework for vision-based autonomous urban driving, preprint, arXiv:2202.08557. |
| [7] |
S. Feng, H. Sun, X. Yan, H. Zhu, Z. Zou, S. Shen, et al., Dense reinforcement learning for safety validation of autonomous vehicles, Nature, 615 (2023), 620–627. https://doi.org/10.1038/s41586-023-05732-2 doi: 10.1038/s41586-023-05732-2
|
| [8] |
S. B. Prathiba, G. Raja, K. Dev, N. Kumar, M. Guizani, A hybrid deep reinforcement learning for autonomous vehicles smart-platooning, IEEE Trans. Veh. Technol., 70 (2021), 13340–13350. https://doi.org/10.1109/TVT.2021.3122257 doi: 10.1109/TVT.2021.3122257
|
| [9] |
Y. Yao, N. Ma, C. Wang, Z. Wu, C. Xu, J. Zhang, Research and implementation of variable-domain fuzzy pid intelligent control method based on q-learning for self-driving in complex scenarios, Math. Biosci. Eng., 20 (2023), 6016–6029. https://doi.org/10.3934/mbe.2023260 doi: 10.3934/mbe.2023260
|
| [10] |
Z. Cao, S. Xu, X. Jiao, H. Peng, D. Yang, Trustworthy safety improvement for autonomous driving using reinforcement learning, Transp. Res. part C: Emerging Technol., 138 (2022), 103656. https://doi.org/10.1016/j.trc.2022.103656 doi: 10.1016/j.trc.2022.103656
|
| [11] | D. Rempe, J. Philion, L. J. Guibas, S. Fidler, O. Litany, Generating useful accident-prone driving scenarios via a learned traffic prior, preprint, arXiv:2112.05077. |
| [12] |
G. Li, Y. Yang, S. Li, X. Qu, N. Lyu, S. E. Li, Decision making of autonomous vehicles in lane change scenarios: Deep reinforcement learning approaches with risk awareness, Transp. Res. part C: Emerging Technol., 134 (2022), 103452. https://doi.org/10.1016/j.trc.2021.103452 doi: 10.1016/j.trc.2021.103452
|
| [13] | P. Bhattacharyya, C. Huang, K. Czarnecki, Ssl-lanes: Self-supervised learning for motion forecasting in autonomous driving, preprint, arXiv:2206.14116. |
| [14] |
Y. Du, J. Chen, C. Zhao, C. Liu, F. Liao, C. Chan, Comfortable and energy-efficient speed control of autonomous vehicles on rough pavements using deep reinforcement learning, Transp. Res. Part C: Emerging Technol., 134 (2022), 103489. https://doi.org/10.1016/j.trc.2021.103489 doi: 10.1016/j.trc.2021.103489
|
| [15] |
B. Zou, J. Peng, S. Li, Y. Li, J. Yan, H. Yang, Comparative study of the dynamic programming-based and rule-based operation strategies for grid-connected pv-battery systems of office buildings, Appl. Energy, 305 (2022), 117875. https://doi.org/10.1016/j.apenergy.2021.117875 doi: 10.1016/j.apenergy.2021.117875
|
| [16] |
B. Du, B. Lin, C. Zhang, B. Dong, W. Zhang, Safe deep reinforcement learning-based adaptive control for usv interception mission, Ocean Eng., 246 (2022), 110477. https://doi.org/10.1016/j.oceaneng.2021.110477 doi: 10.1016/j.oceaneng.2021.110477
|
| [17] |
P. R. Wurman, S. Barrett, K. Kawamoto, J. MacGlashan, K. Subramanian, T. J. Walsh, et al., Outracing champion gran turismo drivers with deep reinforcement learning, Nature, 602 (2022), 223–228. https://doi.org/10.1038/s41586-021-04357-7 doi: 10.1038/s41586-021-04357-7
|
| [18] |
J. Duan, D. Shi, R. Diao, H. Li, Z. Wang, B. Zhang, et al., Deep-reinforcement-learning-based autonomous voltage control for power grid operations, IEEE Trans. Power Syst., 35 (2020), 814–817. https://doi.org/10.1109/TPWRS.2019.2941134 doi: 10.1109/TPWRS.2019.2941134
|
| [19] |
S. Aradi, Survey of deep reinforcement learning for motion planning of autonomous vehicles, IEEE Trans. Intell. Transp. Syst., 23 (2022), 740–759. https://doi.org/10.1109/TITS.2020.3024655 doi: 10.1109/TITS.2020.3024655
|
| [20] |
H. An, J. Jung, Decision-making system for lane change using deep reinforcement learning in connected and automated driving, Electronics, 8 (2019), 543. https://doi.org/10.3390/electronics8050543 doi: 10.3390/electronics8050543
|
| [21] |
Y. Du, J. Chen, C. Zhao, F. Liao, M. Zhu, A hierarchical framework for improving ride comfort of autonomous vehicles via deep reinforcement learning with external knowledge, Comput.-Aided Civ. Infrastruct. Eng., 38 (2023), 1059–1078. https://doi.org/10.1111/mice.12934 doi: 10.1111/mice.12934
|
| [22] |
K. Jo, Y. Jo, J. K. Suhr, H. G. Jung, M. Sunwoo, Precise localization of an autonomous car based on probabilistic noise models of road surface marker features using multiple cameras, IEEE Trans. Intell. Transp. Syst., 16 (2015), 3377–3392. https://doi.org/10.1109/TITS.2015.2450738 doi: 10.1109/TITS.2015.2450738
|
| [23] |
B. Okumura, M. R. James, Y. Kanzawa, M. Derry, K. Sakai, T. Nishi, et al., Challenges in perception and decision making for intelligent automotive vehicles: A case study, IEEE Trans. Intell. Veh., 1 (2016), 20–32. https://doi.org/10.1109/TIV.2016.2551545 doi: 10.1109/TIV.2016.2551545
|
| [24] | R. Guidolini, L. G. Scart, L. F. R. Jesus, V. B. Cardoso, C. Badue, T. Oliveira-Santos, Handling pedestrians in crosswalks using deep neural networks in the iara autonomous car, in 2018 International Joint Conference on Neural Networks (IJCNN), (2018), 1–8. https://doi.org/10.1109/IJCNN.2018.8489397 |
| [25] | A. Sadat, M. Ren, A. Pokrovsky, Y. Lin, E. Yumer, R. Urtasun, Jointly learnable behavior and trajectory planning for self-driving vehicles, preprint, arXiv:1910.04586. |
| [26] |
A. Bacha, C. Bauman, R. Faruque, M. Fleming, C. Terwelp, C. Reinholtz, et al., Odin: Team victortango's entry in the darpa urban challenge, J. Field Rob., 25 (2008), 467–492. https://doi.org/10.1002/rob.20248 doi: 10.1002/rob.20248
|
| [27] |
R. Kala, K. Warwick, Multi-level planning for semi-autonomous vehicles in traffic scenarios based on separation maximization, J. Intell. Rob. Syst., 72 (2013), 559–590. https://doi.org/10.1007/s10846-013-9817-7 doi: 10.1007/s10846-013-9817-7
|
| [28] |
X. Li, Z. Sun, D. Cao, Z. He, Q. Zhu, Real-time trajectory planning for autonomous urban driving: Framework, algorithms, and verifications, IEEE/ASME Trans. Mechatron., 21 (2016), 740–753. https://doi.org/10.1109/TMECH.2015.2493980 doi: 10.1109/TMECH.2015.2493980
|
| [29] |
S. Xie, J. Hu, P. Bhowmick, Z. Ding, F. Arvin, Distributed motion planning for safe autonomous vehicle overtaking via artificial potential field, IEEE Trans. Intell. Transp. Syst., 23 (2022), 21531–21547. https://doi.org/10.1109/TITS.2022.3189741 doi: 10.1109/TITS.2022.3189741
|
| [30] | A. E. Sallab, M. Abdou, E. Perot, S. Yogamani, Deep reinforcement learning framework for autonomous driving, preprint, arXiv:1704.02532. |
| [31] | A. E. Sallab, M. Abdou, E. Perot, S. Yogamani, End-to-end deep reinforcement learning for lane keeping assist, preprint, arXiv:1612.04340. |
| [32] | H. Chae, C. M. Kang, B. Kim, J. Kim, C. C. Chung, J. W. Choi, Autonomous braking system via deep reinforcement learning, in 2017 IEEE 20th International conference on intelligent transportation systems (ITSC), (2017), 1–6. https://doi.org/10.1109/ITSC.2017.8317839 |
| [33] |
M. Zhu, Y. Wang, Z. Pu, J. Hu, X. Wang, R. Ke, Safe, efficient, and comfortable velocity control based on reinforcement learning for autonomous driving, Transp. Res. Part C: Emerging Technol., 117 (2020), 102662. https://doi.org/10.1016/j.trc.2020.102662 doi: 10.1016/j.trc.2020.102662
|
| [34] | M. Jaritz, R. De Charette, M. Toromanoff, E. Perot, F. Nashashibi, End-to-end race driving with deep reinforcement learning, in 2018 IEEE international conference on robotics and automation (ICRA), (2018), 2070–2075. https://doi.org/10.1109/ICRA.2018.8460934 |
| [35] |
L. Qian, X. Xu, Y. Zeng, J. Huang, Deep, consistent behavioral decision making with planning features for autonomous vehicles, Electronics, 8 (2019), 1492. https://doi.org/10.3390/electronics8121492 doi: 10.3390/electronics8121492
|
| [36] | N. K. Ure, M. U. Yavas, A. Alizadeh, C. Kurtulus, Enhancing situational awareness and performance of adaptive cruise control through model predictive control and deep reinforcement learning, in 2019 IEEE Intelligent Vehicles Symposium (IV), (2019), 626–631. https://doi.org/10.1109/IVS.2019.8813905 |
| [37] | S. Feng, X. Yan, H. Sun, Y. Feng, H. X. Liu, Intelligent driving intelligence test for autonomous vehicles with naturalistic and adversarial environment, Nature Commun., 748 (2021). https://doi.org/10.1038/s41467-021-21007-8 |
| [38] |
S. Minaee, N. Kalchbrenner, E. Cambria, N. Nikzad, M. Chenaghlu, J. Gao, Deep learning-based text classification: A comprehensive review, ACM Comput. Surv., 54 (2021), 1–40. https://doi.org/10.1145/3439726 doi: 10.1145/3439726
|
| [39] |
G. Li, S. Lin, S. Li, X. Qu, Learning automated driving in complex intersection scenarios based on camera sensors: A deep reinforcement learning approach, IEEE Sens. J., 22 (2022), 4687–4696. https://doi.org/10.1109/JSEN.2022.3146307 doi: 10.1109/JSEN.2022.3146307
|






Figures(7) / Tables(4)

Jin Zhang, Nan Ma, Zhixuan Wu, Cheng Wang, Yongqiang Yao. Intelligent control of self-driving vehicles based on adaptive sampling supervised actor-critic and human driving experience[J]. Mathematical Biosciences and Engineering, 2024, 21(5): 6077-6096. doi: 10.3934/mbe.2024267







 DownLoad:
DownLoad: