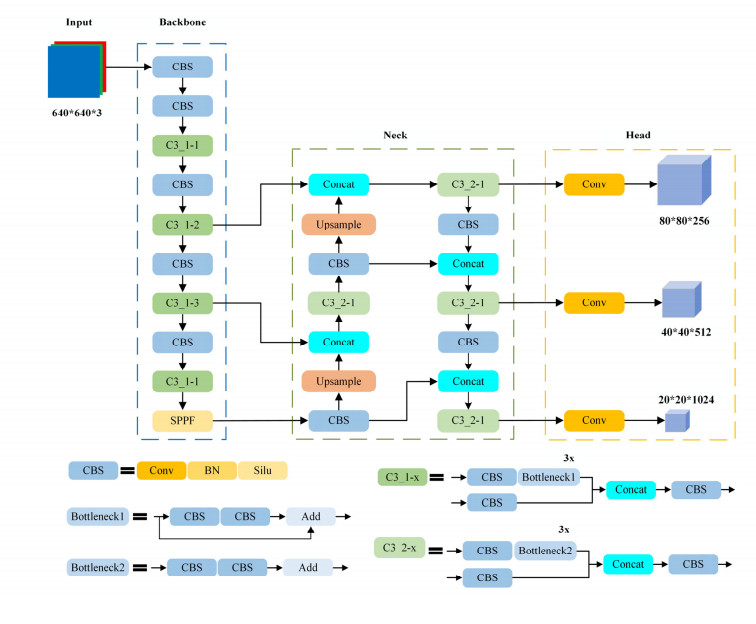
With the widespread integration of deep learning in intelligent transportation and various industrial sectors, target detection technology is gradually becoming one of the key research areas. Accurately detecting road vehicles and pedestrians is of great significance for the development of autonomous driving technology. Road object detection faces problems such as complex backgrounds, significant scale changes, and occlusion. To accurately identify traffic targets in complex environments, this paper proposes a road target detection algorithm based on the enhanced YOLOv5s. This algorithm introduces the weighted enhanced polarization self attention (WEPSA) self-attention mechanism, which uses spatial attention and channel attention to strengthen the important features extracted by the feature extraction network and suppress insignificant background information. In the neck network, we designed a weighted feature fusion network (CBiFPN) to enhance neck feature representation and enrich semantic information. This strategic feature fusion not only boosts the algorithm's adaptability to intricate scenes, but also contributes to its robust performance. Then, the bounding box regression loss function uses EIoU to accelerate model convergence and reduce losses. Finally, a large number of experiments have shown that the improved YOLOv5s algorithm achieves mAP@0.5 scores of 92.8% and 53.5% on the open-source datasets KITTI and Cityscapes. On the self-built dataset, the mAP@0.5 reaches 88.7%, which is 1.7%, 3.8%, and 3.3% higher than YOLOv5s, respectively, ensuring real-time performance while improving detection accuracy. In addition, compared to the latest YOLOv7 and YOLOv8, the improved YOLOv5 shows good overall performance on the open-source datasets.
Citation: Wenjie Liang. Research on a vehicle and pedestrian detection algorithm based on improved attention and feature fusion[J]. Mathematical Biosciences and Engineering, 2024, 21(4): 5782-5802. doi: 10.3934/mbe.2024255
With the widespread integration of deep learning in intelligent transportation and various industrial sectors, target detection technology is gradually becoming one of the key research areas. Accurately detecting road vehicles and pedestrians is of great significance for the development of autonomous driving technology. Road object detection faces problems such as complex backgrounds, significant scale changes, and occlusion. To accurately identify traffic targets in complex environments, this paper proposes a road target detection algorithm based on the enhanced YOLOv5s. This algorithm introduces the weighted enhanced polarization self attention (WEPSA) self-attention mechanism, which uses spatial attention and channel attention to strengthen the important features extracted by the feature extraction network and suppress insignificant background information. In the neck network, we designed a weighted feature fusion network (CBiFPN) to enhance neck feature representation and enrich semantic information. This strategic feature fusion not only boosts the algorithm's adaptability to intricate scenes, but also contributes to its robust performance. Then, the bounding box regression loss function uses EIoU to accelerate model convergence and reduce losses. Finally, a large number of experiments have shown that the improved YOLOv5s algorithm achieves mAP@0.5 scores of 92.8% and 53.5% on the open-source datasets KITTI and Cityscapes. On the self-built dataset, the mAP@0.5 reaches 88.7%, which is 1.7%, 3.8%, and 3.3% higher than YOLOv5s, respectively, ensuring real-time performance while improving detection accuracy. In addition, compared to the latest YOLOv7 and YOLOv8, the improved YOLOv5 shows good overall performance on the open-source datasets.

| [1] | S. Guzman, A. Gomez, G. Diez, D. S. Fernández, Car detection methodology in outdoor environment based on histogram of oriented gradient (HOG) and support vector machine (SVM), in 6th Latin-American Conference on Networked and Electronic Media (LACNEM 2015), (2015). https://doi.org/10.1049/ic.2015.0310 |
| [2] |
L. Guo, P. S. Ge, M. H. Zhang, L. H. Li, Y. B. Zhao, Pedestrian detection for intelligent transportation systems combining AdaBoost algorithm and support vector machine, Exp. Syst. Appl., 39 (2012), 4274–4286. https://doi.org/10.1016/j.eswa.2011.09.106 doi: 10.1016/j.eswa.2011.09.106

|
| [3] | H. Razalli, R. Ramli, M. H. Alkawaz, Emergency vehicle recognition and classification method using HSV color segmentation, in 2020 16th IEEE International Colloquium on Signal Processing & Its Applications (CSPA), (2020), 284–289. https://doi.org/10.1109/CSPA48992.2020.9068695 |
| [4] |
Z. M. Zhu, J. Qiao, Research of preceding vehicle identification based on HAAR-like features and Adaboost algorithm, Electronic Measurement Technol., 40 (2017), 180–184. https:doi.org//10.19651/j.cnki.emt.2017.05.037 doi: 10.19651/j.cnki.emt.2017.05.037
|
| [5] | R. Girshick, J. Donahue, T. Darrell, J. Malik, Rich feature hierarchies for accurate object detection and semantic segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2014), 580–587. https://doi.org/10.1109/CVPR.2014.81 |
| [6] | R. Girshick, Fast R-CNN, in Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2015), 1440–1448. https://doi.org/10.1109/ICCV.2015.169 |
| [7] |
S. Q. Ren, K. M. He, R. Girshick, J. Sun, Faster R-CNN: Towards real-time object detection with region proposal networks, Adv. Neural Inf. Process. Syst., 28 (2015), 1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031 doi: 10.1109/TPAMI.2016.2577031
|
| [8] | W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C. Y. Fu, et al., SSD: Single shot multibox detector, in Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, 14, (2016), 21–37. https://doi.org/10.1007/978-3-319-46448-0_2 |
| [9] | M. Tan, R. Pang, Q. V. Le, Efficientdet: Scalable and efficient object detection, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2020), 10781–10790. https://doi.org/10.1109/CVPR42600.2020.01079 |
| [10] | T. Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollár, Focal loss for dense object detection, in Proceedings of the IEEE International Conference on Computer Vision, (2017), 2980–2988. https://doi.org/10.1109/ICCV.2017.324 |
| [11] | K. Shi, H. Bao, N. Na, Forward vehicle detection based on incremental learning and fast R-CNN, in 2017 13th International Conference on Computational Intelligence and Security (CIS), (2017), 73–76. https://doi.org/10.1109/CIS.2017.00024 |
| [12] |
G. Yin, M. Yu, M. Wang, Y. Hu, Y. Zhang, Research on highway vehicle detection based on faster R-CNN and domain adaptation, Appl. Intell., 52 (2022), 3483–3498. https://doi.org/10.1007/s10489-021-02552-7 doi: 10.1007/s10489-021-02552-7
|
| [13] |
C. Zhao, X. Shu, X. Yan, X. Zuo, F. Zhu, RDD-YOLO: A modified YOLO for detection of steel surface defects, Measurement, 214 (2023), 112776. https://doi.org/10.1016/j.measurement.2023.112776 doi: 10.1016/j.measurement.2023.112776
|
| [14] |
Y. Cai, Z. Yao, H. Jiang, W. Qin, J. Xiao, X. Huang, et al., Rapid detection of fish with SVC symptoms based on machine vision combined with a NAM-YOLO v7 hybird model, Aquaculture, 582 (2024), 740558. https://doi.org/10.1016/j.aquaculture.2024.740558 doi: 10.1016/j.aquaculture.2024.740558
|
| [15] |
A. M. Roy, R. Bose, J. A. Bhaduri, A fast accurate fine-grain object detection model based on YOLOv4 deep neural network, Neural Comput. Appl., 2022 (2022), 1–27. https://doi.org/10.1007/s00521-021-06651-x doi: 10.1007/s00521-021-06651-x
|
| [16] |
M. Kasper-Eulaers, N. Hahn, S. Berger, T. Sebulonsen, Ø. Myrland, P. E. Kummervold, Detecting heavy goods vehicles in rest areas in winter conditions using YOLOv5, Algorithms, 14 (2021). https://doi.org/10.3390/a14040114 doi: 10.3390/a14040114
|
| [17] |
T. Shi, Y. Ding, W. Zhu, YOLOv5s_2E: Improved YOLOv5s for aerial small target detection, IEEE Access, 2023 (2023). https://doi.org/10.1109/ACCESS.2023.3300372 doi: 10.1109/ACCESS.2023.3300372
|
| [18] |
C. J. Zhang, X. B. Hu, H. C. Niu, Vehicle object detection based on improved YOLOv5 method, J. Sichuan Univ., 5 (2022), 79–87. https://doi.org/10.19907/j.0490-6756.2022.053001 doi: 10.19907/j.0490-6756.2022.053001
|
| [19] |
T. Gao, M. Wushouer, G. Tuerhong, DMS-YOLOv5: A decoupled multi-scale YOLOv5 method for small object detection, Appl. Sci., 13 (2023), 6124. https://doi.org/10.3390/app13106124 doi: 10.3390/app13106124
|
| [20] | Y. F. Zhang, W. Ren, Z. Zhang, Z. Jia, L. Wang, T. Tan, Focal and efficient IOU loss for accurate bounding box regression, Neurocomputing, 506 (2022), 146–157. |
| [21] |
B. Y. Sheng, J. Hou, J. X. Li, H. Dang, Road object detection method for complex road scenes, Comput. Eng. Appl., 15 (2023), 87–96. https://doi.org/10.3778/j.issn.1002-8331.2212-0093 doi: 10.3778/j.issn.1002-8331.2212-0093
|
| [22] |
H. J. Liu, F. Q. Liu, X. Y. Fan, D. Huang, Polarized self-attention: Towards high-quality pixel-wise mapping, Neurocomputing, 506 (2022), 158–167. https://doi.org/10.1016/j.neucom.2022.07.054 doi: 10.1016/j.neucom.2022.07.054
|
| [23] |
J. H. Liu, G. F. Yin, D. J. Huang, Object detection in visible light and infrared images based on feature fusion, Laser Infrared, 3 (2023), 394–401. https://doi.org/10.3969/j.issn.1001-5078.2023.03.010 doi: 10.3969/j.issn.1001-5078.2023.03.010
|
| [24] | T. Y. Lin, P. Dollár, R. Grishick, K. He, B. Hariharan, S. Belongie, Feature pyramid networks for object detection, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2017), 2117–2125. https://doi.org/10.1109/CVPR.2017.106 |
| [25] | S. Liu, L. Qin, H. Qin, J. Shi, J. Jia, Path aggregation network for instance segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 8759–8768. https://doi.org/10.1109/CVPR.2018.00913 |
| [26] | M. X. Tan, R. Pang, Q.V. Le, Efficientdet: Scalable and efficient object detection, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2020), 10781–10790. https://doi.org/10.1109/CVPR42600.2020.01079 |
| [27] | J. Redmon, A. Farhadi, Yolov3: An incremental improvement, preprint, arXiv: 1804, 02767. https://doi.org/10.48550/arXiv.1804.02767 |
| [28] | Z. Ge, S. Liu, F. Wang, Z. Li, J. Sun, Yolox: Exceeding yolo series in 2021, preprint, arXiv: 2107.08430. https://doi.org/10.48550/arXiv.2107.08430 |
| [29] | C. Y, Wang, A. Bochkovskiy, H. Y. M. Liao, YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2023), 7464–7475. https://doi.org/10.1109/CVPR52729.2023.00721 |
| [30] | X. Zhou, D. Wang, P. Krähenbühl, Object as points, preprint, arXiv: 1904, 07850. https://doi.org/10.48550/arXiv.1904.07850 |
| [31] |
X. Wang, Z. Li, H. L. Zhang, High-resolution network Anchor-free object detection method based on iterative aggregation, J. Beijing Univ. Aeronaut. Astronaut., 47 (2021), 2533–2541. https://doi.org/10.13700/j.bh.1001-5965.2020.0484 doi: 10.13700/j.bh.1001-5965.2020.0484
|
| [32] | J. Choi, D. Chun, H. Kim, H. J. Lee, Gaussian yolov3: An accurate and fast object detector using localization uncertainty for autonomous driving, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2019), 502–511. |
| [33] |
H. Xu, M. Guo, N. Nedjah, et al., Vehicle and pedestrian detection algorithm based on lightweight YOLOv3-promote and semi-precision acceleration, IEEE Trans. Intell. Transp. Syst., 23 (2022), 19760–19771. https://doi.org/10.1109/TITS.2021.3137253 doi: 10.1109/TITS.2021.3137253
|
| [34] |
S. G. Ma, N. B. Li, Z. Q. Hou, W. S. Yu, X. B. Yang, Object detection algorithm based on DSGIoU loss and dual branch coordinate attention, J. Beijing Univ. Aeronaut. Astronaut., (2024), 1–14. https://doi.org/10.13700/j.bh.1001-5965.2023.0192 doi: 10.13700/j.bh.1001-5965.2023.0192
|
| [35] |
J. Chen, J. Zhu, R. Xu, Y. Chen, H. Zeng, J. Huang, ORNet: Orthogonal re-parameterized networks for fast pedestrian and vehicle detection, IEEE Trans. Intell. Vehicles, 2023 (2023), 2662–2674. https://doi.org/10.1109/TIV.2023.3323204 doi: 10.1109/TIV.2023.3323204
|







Figures(8) / Tables(10)

Wenjie Liang. Research on a vehicle and pedestrian detection algorithm based on improved attention and feature fusion[J]. Mathematical Biosciences and Engineering, 2024, 21(4): 5782-5802. doi: 10.3934/mbe.2024255







 DownLoad:
DownLoad: