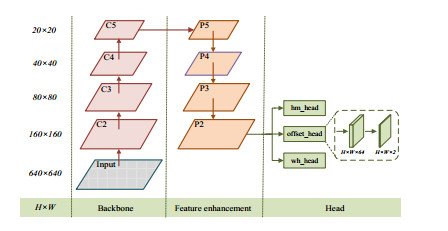
Nowadays, object detection methods based on deep neural networks have been widely applied in autonomous driving and intelligent robot systems. However, weakly perceived objects with a small size in the complex scenes own too few features to be detected, resulting in the decrease of the detection accuracy. To improve the performance of the detection model in complex scenes, the detector of an improved CenterNet was developed via this work to enhance the feature representation of weakly perceived objects. Specifically, we replace the ResNet50 with ResNext50 as the backbone network to enhance the ability of feature extraction of the model. Then, we append the lateral connection structure and the dilated convolution to improve the feature enhancement layer of the CenterNet, leading to enriched features and enlarged receptive fields for the weakly sensed objects. Finally, we apply the attention mechanism in the detection head of the network to enhance the key information of the weakly perceived objects. To demonstrate the effectiveness, we evaluate the proposed model on the KITTI dataset and COCO dataset. Compared with the original model, the average precision of multiple categories of the improved CenterNet for the vehicles and pedestrians in the KITTI dataset increased by 5.37%, whereas the average precision of weakly perceived pedestrians increased by 9.30%. Moreover, the average precision of small objects (AP_S) of the weakly perceived small objects in the COCO dataset increase 7.4%. Experiments show that the improved CenterNet can significantly improve the average detection precision for weakly perceived objects.
Citation: Jing Zhou, Ze Chen, Xinhan Huang. Weakly perceived object detection based on an improved CenterNet[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 12833-12851. doi: 10.3934/mbe.2022599
Nowadays, object detection methods based on deep neural networks have been widely applied in autonomous driving and intelligent robot systems. However, weakly perceived objects with a small size in the complex scenes own too few features to be detected, resulting in the decrease of the detection accuracy. To improve the performance of the detection model in complex scenes, the detector of an improved CenterNet was developed via this work to enhance the feature representation of weakly perceived objects. Specifically, we replace the ResNet50 with ResNext50 as the backbone network to enhance the ability of feature extraction of the model. Then, we append the lateral connection structure and the dilated convolution to improve the feature enhancement layer of the CenterNet, leading to enriched features and enlarged receptive fields for the weakly sensed objects. Finally, we apply the attention mechanism in the detection head of the network to enhance the key information of the weakly perceived objects. To demonstrate the effectiveness, we evaluate the proposed model on the KITTI dataset and COCO dataset. Compared with the original model, the average precision of multiple categories of the improved CenterNet for the vehicles and pedestrians in the KITTI dataset increased by 5.37%, whereas the average precision of weakly perceived pedestrians increased by 9.30%. Moreover, the average precision of small objects (AP_S) of the weakly perceived small objects in the COCO dataset increase 7.4%. Experiments show that the improved CenterNet can significantly improve the average detection precision for weakly perceived objects.

| [1] |
L. H. Wen, K. H. Jo, Deep learning-based perception systems for autonomous driving: A comprehensive survey, Neurocomputing, 489 (2022), 255–270. DOI: 10.1016/j.neucom.2021.08.155 doi: 10.1016/j.neucom.2021.08.155

|
| [2] |
X. Gao, G. Y. Zhang, Y. J. Xiong, Multi-scale multi-modal fusion for object detection in autonomous driving based on selective kernel, Measurement, 194 (2022), 111001. DOI: 10.1016/j.measurement.2022.111001 doi: 10.1016/j.measurement.2022.111001
|
| [3] | R. Girshick, J. Donahue, T. Darrell, J. Malik, Rich feature hierarchies for accurate object detection and semantic segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2014), 580–587. |
| [4] | S. Q. Ren, K. M. He, R. Girshick, J. Sun, Faster r-cnn: Towards real-time object detection with region proposal networks, in Proceedings of the Advances in Neural Information Processing Systems, (2015), 91–99. |
| [5] | J. Redmon, A. Farhadi, YOLO9000: better, faster, stronger, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 7263–7271. DOI: 10.1109/CVPR.2017.690 |
| [6] | J. Redmon, A. Farhadi, YOLOv3: An incremental improvement, preprint, arXiv: 1804.02767, DOI: 10.48550/arXiv.1804.02767 |
| [7] | A. Bochkovskiy, C. Y. Wang, H. Y. M. Liao, Yolov4: Optimal speed and accuracy of object detection, preprint, arXiv: 2004.10934. DOI: 10.48550/arXiv.2004.10934 |
| [8] | J. M. Pang, K. Chen, J. P. Shi, H. J. Feng, W. L. Ouyang, D. H. Lin, Libra r-cnn: Towards balanced learning for object detection, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 821–830. |
| [9] | Z. W. Cai, N. Vasconcelos, Cascade r-cnn: Delving into high quality object detection, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 6154–6162. |
| [10] | T. Y. Lin, P. Goyal, R. Girshick, K. M. He, P. Dollar, Focal loss for dense object detection, in Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2017), 2980–2988. |
| [11] | G. Zhao, J. Pang, H. Zhang, J. Zhou, L. J. Li, Anchor-free network for multi-class object detection in remote sensing images, in 2020 39th Chinese Control Conference (CCC), IEEE, (2020), 7510–7515. DOI: 10.23919/CCC50068.2020.9188903 |
| [12] | K. Duan, L. Xie, H. Qi, S. Bai, Q. Huang, Q. Tian, Corner proposal network for anchor-free, two-stage object detection, in Computer Vision-European Conference on Computer Vision (ECCV) 2020. Lecture Notes in Computer Science, Springer, Cham, 12348 (2020), 399–416. DOI: 10.1007/978-3-030-58580-8_24 |
| [13] | Z. Yang, S. Liu, H. Hu, L. Wang, S. Lin, Reppoints: Point set representation for object detection, in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 9657–9666. |
| [14] | Z. Ge, S. T. Liu, F. Wang, Z. M. Li, J. Sun, Yolox: Exceeding yolo series in 2021, preprint, arXiv: 2107.08430. DOI: 10.48550/arXiv.2107.08430 |
| [15] | K. W. Duan, L. X. Xie, H. G. Qi, S. Bai, Q. M. Huang, Q. Tian, Location-sensitive visual recognition with cross-iou loss, preprint, arXiv: 2104.04899. DOI: 10.48550/arXiv.2104.04899 |
| [16] | J. Wang, K. Chen, S. Yang, C. Loy, D. Lin, Region proposal by guided anchoring, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 2965–2974. |
| [17] | C. Zhu, Y. He, M. Savvides, Feature selective anchor-free module for single-shot object detection, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 840–849. |
| [18] | T. Y. Lin, P. Dollár, R. Girshick, K. M. He, B. Hariharan, S. Belongle, Feature pyramid networks for object detection, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 2117–2125. |
| [19] | S. Zhang, C. Chi, Y. Q. Yao, Z. Lei, S. Z. Li, Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 9759–9768. |
| [20] | Z. Tian, C. Shen, H. Chen, T. He, Fcos: Fully convolutional one-stage object detection, in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 9627–9636. |
| [21] | C. Zhu, F. Chen, Z. Shen, M. Savvides, Soft anchor-point object detection, in Proceedings of the ECCV, (2020), 91–107. DOI: 10.1007/978-3-030-58545-7_6 |
| [22] | H. Law, J. Deng, CornerNet: Detecting objects as paired keypoints, in Proceedings of the European Conference on Computer Vision (ECCV), (2018), 734–750. |
| [23] | X. Zhou, J. Zhuo, P. Krahenbuhl, Bottom-up object detection by grouping extreme and center points, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 850–859. |
| [24] | X. Zhou, D. Wang, P. Krä henbühl, Objects as points, preprint, arXiv: 1904.07850. DOI: 10.48550/arXiv.1904.07850 |
| [25] | W. Liu, D. Anguelov, D. Erhan, C. Szegedy, Ssd: Single shot multibox detector, in Computer Vision -European Conference on Computer Vision (ECCV), (2016), 21–37. DOI: 10.1007/978-3-319-46448-0_2 |
| [26] | C. Y. Fu, W. Liu, A. Ranga, A. Tyagi, A. C. Berg, DSSD: Deconvolutional single shot detector, preprint, arXiv: 1701.06659. DOI: 10.48550/arXiv.1701.06659 |
| [27] | S. Liu, D. Huang, Y. H. Wang, Receptive field block net for accurate and fast object detection, in Proceedings of the European Conference on Computer Vision (ECCV), (2018), 385–400. |
| [28] | J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in Proceedings of the CVPR, (2018), 7132–7141. DOI: 10.48550/arXiv.1709.01507 |
| [29] | Q. Wang, B. Wu, P. Zhu, P. Li, W. Zuo, Q. Hu, ECA-Net: Efficient channel attention for deep convolutional neural networks, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 11531–11539. |
| [30] | S. H. Woo, J. C. Park, J. Y. Lee, I. S. Kweon, Cbam: Convolutional block attention module, in Proceedings of the European Conference on Computer Vision (ECCV), (2018), 3–19. |
| [31] | V. Mnih, N. Heess, A. Graves, K. Kavukcuoglu, Recurrent models of visual attention, J. Adv. Neual. Inf. Process. Syst., 3 (2014), 2204–2212. |
| [32] |
J. Shin, H. J. Kim, PresB-Net: parametric binarized neural network with learnable activations and shuffled grouped convolution, PeerJ Comput. Sci., 8 (2022), e842. DOI: 10.7717/peerj-cs.842 doi: 10.7717/peerj-cs.842
|
| [33] | S. Xie, R. Girshick, P. Dollár, Z. W. Tu, K. M. He, Aggregated residual transformations for deep neural networks, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 1492–1500. |
| [34] | Q. Chen, Y. Wang, T. Yang, X. Zhang, You only look one-level feature, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 13039–13048. |
| [35] | A.Geiger, P. Lenz, R. Urtasun, Are we ready for autonomous driving? the kitti vision benchmark suite, in Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR). (2012), 3354–3361. DOI: 10.1109/CVPR.2012.6248074 |
| [36] | T. Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, Microsoft coco: Common objects in context, in Proceeding of the European conference on computer vision (ECCV), (2014), 740–755. DOI: 10.1007/978-3-319-10602-1_48 |
| [37] | K. M. He, X. Y. Zhang, S. Q. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 770–778. |
| [38] | Y. Li, Research of lightweight vehicle and pedestrian detection based on CNN, Master Thesis, North China University, 2021. |
| [39] | L. X. Meng, Research on vehicle pedestrian detection method based on deep learning, Master Thesis, North China University, 2021. |
| [40] | S. Zhang, C. Chi, Y. Q. Yao, Z. Lei, S. Z. Li, Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 9759–9768. |
| [41] | S. Wang, Y. Gong, J. Xing, L. Huang, C. Huang, W. Hu, RDSNet: A new deep architecture forreciprocal object detection and instance segmentation, in Proceedings of the AAAI Conference on Artificial Intelligence, 34 (2020), 12208–12215. DOI: 10.1609/aaai.v34i07.6902 |








Figures(9) / Tables(6)

Jing Zhou, Ze Chen, Xinhan Huang. Weakly perceived object detection based on an improved CenterNet[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 12833-12851. doi: 10.3934/mbe.2022599







 DownLoad:
DownLoad: