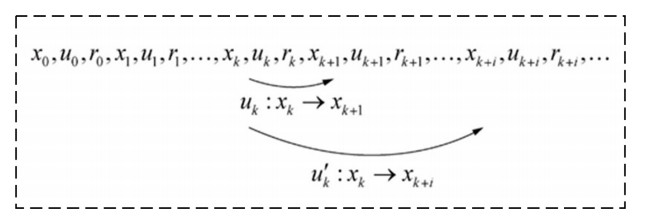
In recent years, dynamic programming and reinforcement learning theory have been widely used to solve the nonlinear control system (NCS). Among them, many achievements have been made in the construction of network model and system stability analysis, but there is little research on establishing control strategy based on the detailed requirements of control process. Spurred by this trend, this paper proposes a detail-reward mechanism (DRM) by constructing the reward function composed of the individual detail evaluation functions in order to replace the utility function in the Hamilton-Jacobi-Bellman (HJB) equation. And this method is introduced into a wider range of deep reinforcement learning algorithms to solve optimization problems in NCS. After the mathematical description of the relevant characteristics of NCS, the stability of iterative control law is proved by Lyapunov function. With the inverted pendulum system as the experiment object, the dynamic environment is designed and the reward function is established by using the DRM. Finally, three deep reinforcement learning algorithm models are designed in the dynamic environment, which are based on Deep Q-Networks, policy gradient and actor-critic. The effects of different reward functions on the experimental accuracy are compared. The experimental results show that in NCS, using the DRM to replace the utility function in the HJB equation is more in line with the detailed requirements of the designer for the whole control process. By observing the characteristics of the system, designing the reward function and selecting the appropriate deep reinforcement learning algorithm model, the optimization problem of NCS can be solved.
Citation: Shixuan Yao, Xiaochen Liu, Yinghui Zhang, Ze Cui. An approach to solving optimal control problems of nonlinear systems by introducing detail-reward mechanism in deep reinforcement learning[J]. Mathematical Biosciences and Engineering, 2022, 19(9): 9258-9290. doi: 10.3934/mbe.2022430
In recent years, dynamic programming and reinforcement learning theory have been widely used to solve the nonlinear control system (NCS). Among them, many achievements have been made in the construction of network model and system stability analysis, but there is little research on establishing control strategy based on the detailed requirements of control process. Spurred by this trend, this paper proposes a detail-reward mechanism (DRM) by constructing the reward function composed of the individual detail evaluation functions in order to replace the utility function in the Hamilton-Jacobi-Bellman (HJB) equation. And this method is introduced into a wider range of deep reinforcement learning algorithms to solve optimization problems in NCS. After the mathematical description of the relevant characteristics of NCS, the stability of iterative control law is proved by Lyapunov function. With the inverted pendulum system as the experiment object, the dynamic environment is designed and the reward function is established by using the DRM. Finally, three deep reinforcement learning algorithm models are designed in the dynamic environment, which are based on Deep Q-Networks, policy gradient and actor-critic. The effects of different reward functions on the experimental accuracy are compared. The experimental results show that in NCS, using the DRM to replace the utility function in the HJB equation is more in line with the detailed requirements of the designer for the whole control process. By observing the characteristics of the system, designing the reward function and selecting the appropriate deep reinforcement learning algorithm model, the optimization problem of NCS can be solved.

| [1] |
J. Wu, W. Sun, S. F. Su, Y. Q. Wu, Adaptive quantized control for uncertain nonlinear systems with unknown control directions, Int. J. Robust Nonlinear Control, 31 (2021), 8658–8671. https://doi.org/10.1002/rnc.5748 doi: 10.1002/rnc.5748

|
| [2] |
A. Shatyrko, J. Diblík, D. Khusainov, M. Růžičková, Stabilization of Lur'e-type nonlinear control systems by Lyapunov-Krasovskii functionals, Adv. Diff. Equations, 2012 (2012), 1–9. https://doi.org/10.1186/1687-1847-2012-229 doi: 10.1186/1687-1847-2012-229
|
| [3] |
K. Tatsuya, Limit-cycle-like control for 2-dimensional discrete-time nonlinear control systems and its application to the Hénon map, Commun. Nonlinear Sci. Numer. Simul., 18 (2013), 171–183. https://doi.org/10.1016/j.cnsns.2012.06.012 doi: 10.1016/j.cnsns.2012.06.012
|
| [4] |
Y. H. Wei, Lyapunov stability theory for nonlinear nabla fractional order systems, IEEE Trans. Circuits Sys., 68 (2021), 3246–3250. https://doi.org/10.1109/TCSII.2021.3063914 doi: 10.1109/TCSII.2021.3063914
|
| [5] |
G. Pole, A. Girard, P. Tabuada, Approximately bisimilar symbolic models for nonlinear control systems, Automatica, 44 (2008), 2508–2516. https://doi.org/10.1016/j.automatica.2008.02.021 doi: 10.1016/j.automatica.2008.02.021
|
| [6] |
H. G. Zhang, X. Zhang, Y. H. Luo, J. Yang, An overview of research on adaptive dynamic programming, Acta Autom. Sin., 39 (2013), 303–311. https://doi.org/10.1016/S1874-1029(13)60031-2 doi: 10.1016/S1874-1029(13)60031-2
|
| [7] |
M. Volckaert, M. Diehl, J. Swevers, Generalization of norm optimal ILC for nonlinear systems with constraints, Mech. Syst. Signal Proc., 39 (2013), 280–296. https://doi.org/10.1016/j.ymssp.2013.03.009 doi: 10.1016/j.ymssp.2013.03.009
|
| [8] |
W. N. Gao, Z. P. Jiang, Nonlinear and adaptive suboptimal control of connected vehicles: A global adaptive dynamic programming approach, J. Intell. Rob. Syst., 85 (2017), 597–611. http://doi.org/10.1007/s10846-016-0395-3 doi: 10.1007/s10846-016-0395-3
|
| [9] |
E. Trélat, Optimal control and applications to aerospace: Some results and challenges, J. Optim. Theory Appl., 154 (2012), 713–758. https://doi.org/10.1007/s10957-012-0050-5 doi: 10.1007/s10957-012-0050-5
|
| [10] |
M. Margaliot, Stability analysis of switched systems using variational principles: An introduction, Automatica, 42 (2006), 2059–2077. https://doi.org/10.1016/j.automatica.2006.06.020 doi: 10.1016/j.automatica.2006.06.020
|
| [11] |
A. Maidi, J. P. Corriou, Open-loop optimal controller design using variational iteration method, Appl. Math. Comput., 219 (2013), 8632–8645. https://doi.org/10.1016/j.amc.2013.02.075 doi: 10.1016/j.amc.2013.02.075
|
| [12] |
F. H. Clarke, R. B. Vinter, The relationship between the maximum principle and dynamic programming, SIAM J. Control Optim., 25 (1987), 1291–1311. http://doi.org/10.1137/0325071 doi: 10.1137/0325071
|
| [13] |
R. W. Beard, G. N. Saridis, J. T. Wen, Approximate solutions to the time-invariant Hamilton–Jacobi–Bellman equation, J. Optim. Theory Appl., 96 (1998), 589–626. http://doi.org/10.1023/A:1022664528457 doi: 10.1023/A:1022664528457
|
| [14] |
J. A. Roubos, S. Mollov, R. Babuška, H. B. Verbruggen, Fuzzy model-based predictive control using Takagi–Sugeno models, Int. J. Approximate Reasoning, 22 (1999), 3–30. http://doi.org/10.1016/S0888-613X(99)00020-1 doi: 10.1016/S0888-613X(99)00020-1
|
| [15] |
D. A. Bristow, M. Tharayil, A. G. Alleyne, A survey of iterative learning control, IEEE Control Syst. Mag., 26 (2006), 96–114. https://doi.org/10.1109/MCS.2006.1636313 doi: 10.1109/MCS.2006.1636313
|
| [16] | P. J. Werbos, W. T. Miller, R. S. Sutton, A menu of designs for reinforcement learning over time, Neural networks for control, MIT press, Cambridge, (1990), 67–95. |
| [17] |
J. Wang, R. Y. K. Fung, Adaptive dynamic programming algorithms for sequential appointment scheduling with patient preferences, Artif. Intell. Med., 63 (2015), 33–40. https://doi.org/10.1016/j.artmed.2014.12.002 doi: 10.1016/j.artmed.2014.12.002
|
| [18] |
D. V. Prokhorov, D. C. Wunsch, Adaptive critic designs, IEEE Trans. Neural Networks, 8 (1997), 997–1007. http://doi.org/10.1109/72.623201 doi: 10.1109/72.623201
|
| [19] |
J. J. Murray, C. J. Cox, G. G. Lendaris, R. Saeks, Adaptive dynamic programming. IEEE Trans. Syst. Man Cybern., 32 (2002), 140–153. http://doi.org/10.1109/TSMCC.2002.801727 doi: 10.1109/TSMCC.2002.801727
|
| [20] |
H. G. Zhang, Q. L. Wei, D. R. Liu, An iterative adaptive dynamic programming method for solving a class of nonlinear zero-sum differential games, Automatica, 47 (2011), 207–214. http://doi.org/10.1016/j.automatica.2010.10.033 doi: 10.1016/j.automatica.2010.10.033
|
| [21] |
Q. L. Wei, H. G. Zhang, D. R. Liu, Y. Zhao, An optimal control scheme for a class of discrete-time nonlinear systems with time delays using adaptive dynamic programming, Acta Autom. Sin., 36 (2010), 121–129. http://doi.org/10.1016/S1874-1029(09)60008-2 doi: 10.1016/S1874-1029(09)60008-2
|
| [22] |
J. Ding, S. N. Balakrishnan, Approximate dynamic programming solutions with a single network adaptive critic for a class of nonlinear systems, J. Control Theory Appl., 9 (2011), 370–380. http://doi.org/10.1007/s11768-011-0191-3 doi: 10.1007/s11768-011-0191-3
|
| [23] | D. R. Liu, D. Wang, D. B. Zhao, Adaptive dynamic programming for optimal control of unknown nonlinear discrete-time systems, in 2011 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning (ADPRL) IEEE, (2011), 242–249. https://doi.org/10.1109/ADPRL.2011.5967357 |
| [24] |
J. Modayil, A. White A, R. S. Sutton, Multi-timescale nexting in a reinforcement learning robot, Adapt. Behav., 22 (2014), 146–160. http://doi.org/10.1177/1059712313511648 doi: 10.1177/1059712313511648
|
| [25] |
C. X. Mu, Y. Zhang, Z. K. Gao, C. Y. Sun, ADP-based robust tracking control for a class of nonlinear systems with unmatched uncertainties, IEEE Trans. Syst. Man Cybern. Syst., 50 (2019), 4056–4067. http://doi.org/10.1109/TSMC.2019.2895692 doi: 10.1109/TSMC.2019.2895692
|
| [26] |
H. Y. Dong, X. W. Zhao, B. Luo, Optimal tracking control for uncertain nonlinear systems with prescribed performance via critic-only ADP, IEEE Trans. Syst. Man Cybern. Syst., 52 (2020), 561–573. https://doi.org/10.1109/TSMC.2020.3003797 doi: 10.1109/TSMC.2020.3003797
|
| [27] |
R. Z. Song, L. Zhu, Optimal fixed-point tracking control for discrete-time nonlinear systems via ADP, IEEE/CAA J. Autom. Sin., 6 (2019), 657–666. https://doi.org/10.1109/JAS.2019.1911453 doi: 10.1109/JAS.2019.1911453
|
| [28] |
M. M. Liang, Q. L. Wei, A partial policy iteration ADP algorithm for nonlinear neuro-optimal control with discounted total reward, Neurocomputing, 424 (2021), 23–34. https://doi.org/10.1016/j.neucom.2020.11.014 doi: 10.1016/j.neucom.2020.11.014
|
| [29] |
B. Fan, Q. M. Yang, X. Y. Tang, Y. X. Sun, Robust ADP design for continuous-time nonlinear systems with output constraints, IEEE Trans. Neural Networks Learn. Syst., 29 (2018), 2127–2138. https://doi.org/10.1109/TNNLS.2018.2806347 doi: 10.1109/TNNLS.2018.2806347
|
| [30] |
X. Yang, H. B. He, Self-learning robust optimal control for continuous-time nonlinear systems with mismatched disturbances, Neural Networks, 99 (2018), 19–30. https://doi.org/10.1016/j.neunet.2017.11.022 doi: 10.1016/j.neunet.2017.11.022
|
| [31] |
D. R. Liu, X. Yang, D. Wang, Q. L. Wei, Reinforcement-learning-based robust controller design for continuous-time uncertain nonlinear systems subject to input constraints, IEEE Trans. Cybern., 45 (2015), 1372–1385. http://doi.org/10.1109/TCYB.2015.2417170 doi: 10.1109/TCYB.2015.2417170
|
| [32] |
X. Yang, D. R. Liu, D. Wang, Reinforcement learning for adaptive optimal control of unknown continuous-time nonlinear systems with input constraints, Int. J. Control, 87 (2014), 553–566. https://doi.org/10.1080/00207179.2013.848292 doi: 10.1080/00207179.2013.848292
|
| [33] |
J. G. Zhao, M. G. Gan, Finite-horizon optimal control for continuous-time uncertain nonlinear systems using reinforcement learning, Int. J. Syst. Sci., 51 (2020), 2429–2440. https://doi.org/10.1080/00207721.2020.1797223 doi: 10.1080/00207721.2020.1797223
|
| [34] |
B. Zhao, D. R. Liu, C. M. Luo, Reinforcement learning-based optimal stabilization for unknown nonlinear systems subject to inputs with uncertain constraints, IEEE Trans. Neural Networks Learn. Syst., 31 (2019), 4330–4340. https://doi.org/10.1109/TNNLS.2019.2954983 doi: 10.1109/TNNLS.2019.2954983
|
| [35] |
D. Wang, J. F. Qiao, Approximate neural optimal control with reinforcement learning for a torsional pendulum device, Neural Networks, 117 (2019), 1–7. https://doi.org/10.1016/j.neunet.2019.04.026 doi: 10.1016/j.neunet.2019.04.026
|
| [36] |
J. W. Kim, B. J. Park, H. Yoo, T. H. Oh, J. H. Lee, J. M. Lee, A model-based deep reinforcement learning method applied to finite-horizon optimal control of nonlinear control-affine system, J. Proc. Control, 87 (2020), 166–178. https://doi.org/10.1016/j.jprocont.2020.02.003 doi: 10.1016/j.jprocont.2020.02.003
|
| [37] |
F. Y. Wang, N. Jin, D. R. Liu, Q. L. Wei, Adaptive dynamic programming for finite-horizon optimal control of discrete-time nonlinear systems with epsilon-error bound, IEEE Trans. Neural Networks, 22 (2010), 24–36. https://doi.org/10.1109/TNN.2010.2076370 doi: 10.1109/TNN.2010.2076370
|
| [38] |
K. G. Vamvoudakis, F. L. Lewis, Multi-player non-zero-sum games: Online adaptive learning solution of coupled Hamilton–Jacobi equations, Automatica, 47 (2011), 1556–1569. https://doi.org/10.1016/j.automatica.2011.03.005 doi: 10.1016/j.automatica.2011.03.005
|
| [39] |
Q. L. Wei, D. R. Liu, An iterative epsilon-optimal control scheme for a class of discrete-time nonlinear systems with unfixed initial state, Neural Networks, 32 (2012), 236–244. https://doi.org/10.1007/978-981-10-4080-1_2 doi: 10.1007/978-981-10-4080-1_2
|
| [40] |
D. R. Liu, Q. L. Wei, P. F. Yan, Generalized policy iteration adaptive dynamic programming for discrete-time nonlinear systems, IEEE Trans. Syst. Man Cybern. Syst., 45 (2015), 1577–1591. https://doi.org/10.1109/TSMC.2015.2417510 doi: 10.1109/TSMC.2015.2417510
|
| [41] |
S. H. Li, H. B. Du, X. H. Yu, Discrete-time terminal sliding mode control systems based on euler's discretization, IEEE Trans. Autom. Control, 59 (2013), 546–552. https://doi.org/10.1109/TAC.2013.2273267 doi: 10.1109/TAC.2013.2273267
|
| [42] | D. Bertsekas, Dynamic Programming and Optimal Control: Volume I, Athena scientific, 2012. |
| [43] |
C. J. C. H. Watkins, P. Dayan, Q-learning, Mach. Learn., 8 (1992), 279–292. https://doi.org/10.1007/BF00992698 doi: 10.1007/BF00992698
|
| [44] | A. Y. Ng, D. Harada, S. Russell, Policy invariance under reward transformations: Theory and application to reward shaping, LCML, 99 (1999), 278–287. |
| [45] | L. Buşoniu, B. D. Schutter, R. Babuška, Approximate dynamic programming and reinforcement learning, in Interactive collaborative information systems, (2010), 3–44. https://doi.org/10.1007/978-3-642-11688-9_1 |
| [46] |
T. Aotani, T. Kobayashi, K. Sugimoto, Bottom-up multi-agent reinforcement learning by reward shaping for cooperative-competitive tasks, Appl. Intell., 51 (2021), 4434–4452. https://doi.org/10.1007/s10489-020-02034-2 doi: 10.1007/s10489-020-02034-2
|
| [47] |
C. HolmesParker, A. K. Agogino, K. Tumer, Combining reward shaping and hierarchies for scaling to large multiagent systems, Knowl. Eng. Rev., 31 (2016), 3–18. https://doi.org/10.1017/S0269888915000156 doi: 10.1017/S0269888915000156
|
| [48] |
P. Mannion, S. Devlin, K. Mason, J. Duggan, E. Howley, Policy invariance under reward transformations for multi-objective reinforcement learning, Neurocomputing, 263 (2017), 60–73. https://doi.org/10.1016/j.neucom.2017.05.090 doi: 10.1016/j.neucom.2017.05.090
|
| [49] |
P. Mannion, S. Devlin, J. Duggan, E. Howley, Reward shaping for knowledge-based multi-objective multi-agent reinforcement learning, Knowl. Eng. Rev., 33 (2018). https://doi.org/10.1017/S0269888918000292 doi: 10.1017/S0269888918000292
|
| [50] |
C. Y. Hu, A confrontation decision-making method with deep reinforcement learning and knowledge transfer for multi-agent system, Symmetry, 12 (2020), 631. https://doi.org/10.3390/sym12040631 doi: 10.3390/sym12040631
|
| [51] |
A. G. Barto, R. S. Sutton, C. W. Anderson, Neuronlike adaptive elements that can solve difficult learning control problems, IEEE Trans. Syst. Man Cybern. Syst., 5 (1983), 834–846. https://doi.org/10.1109/TSMC.1983.6313077 doi: 10.1109/TSMC.1983.6313077
|
| [52] |
L. B. Prasad, B. Tyagi, H. O. Gupta, Optimal control of nonlinear inverted pendulum system using PID controller and LQR: Performance analysis without and with disturbance input, Int. J. Autom. Comput., 11 (2014), 661–670. https://doi.org/10.1007/s11633-014-0818-1 doi: 10.1007/s11633-014-0818-1
|
| [53] |
V. Mnih, K. Kavukcuoglu, D. Silver, J. Veness, A. Graves, M. Riedmiller, et al, Human-level control through deep reinforcement learning, Nature, 518 (2015), 529–533. https://doi.org/10.1038/nature14236 doi: 10.1038/nature14236
|
| [54] | T. d. Bruin, J. Kober, K. Tuyls, R. Babuˇska, Experience selection in deep reinforcement learning for control, J. Mach. Learn. Res., 19 (2018). |
| [55] | B. C. Stadie, S. Levine, p. Abbeel, Incentivizing exploration in reinforcement learning with deep predictive models, preprint, arXiv: 1507.00814. |
| [56] | Z. L. Ning, P. R. Dong, X. J. Wang, JJPC. Rodrigues, F. Xia, Deep reinforcement learning for vehicular edge computing: An intelligent offloading system, in ACM Transactions on Intelligent Systems and Technology, 10 (2019), 1–24. https://doi.org/10.1145/3317572 |
| [57] |
H. Yoo, B. Kim, J. W. Kim, J. H. Lee, Reinforcement learning based optimal control of batch processes using Monte-Carlo deep deterministic policy gradient with phase segmentation, Comput. Chem. Eng., 144 (2021), 107133. https://doi.org/10.1016/j.compchemeng.2020.107133 doi: 10.1016/j.compchemeng.2020.107133
|
| [58] | T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, et al, Continuous control with deep reinforcement learning, preprint, arXiv: 1509.02971. |
| [59] | S. Satheeshbabu, N. K. Uppalapati, T. Fu, G. Krishnan, Continuous control of a soft continuum arm using deep reinforcement learning, in 2020 3rd IEEE International Conference on Soft Robotics (RoboSoft), IEEE, (2020), 497–503. https://doi.org/10.1109/RoboSoft48309.2020.9116003 |
| [60] |
Y. Ma, W. B. Zhu, M. G. Benton, J. Romagnoli, Continuous control of a polymerization system with deep reinforcement learning, J. Proc. Control, 75 (2019), 40–47. https://doi.org/10.1016/j.jprocont.2018.11.004 doi: 10.1016/j.jprocont.2018.11.004
|
| [61] |
R. B. Zmood, The euclidean space controllability of control systems with delay, SIAM J. Control, 12 (1974), 609–623. https://doi.org/10.1137/0312045 doi: 10.1137/0312045
|







Figures(8) / Tables(7)

Shixuan Yao, Xiaochen Liu, Yinghui Zhang, Ze Cui. An approach to solving optimal control problems of nonlinear systems by introducing detail-reward mechanism in deep reinforcement learning[J]. Mathematical Biosciences and Engineering, 2022, 19(9): 9258-9290. doi: 10.3934/mbe.2022430







 DownLoad:
DownLoad: