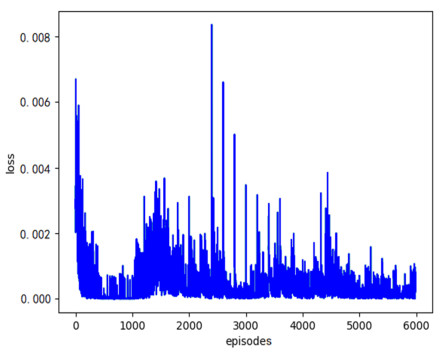
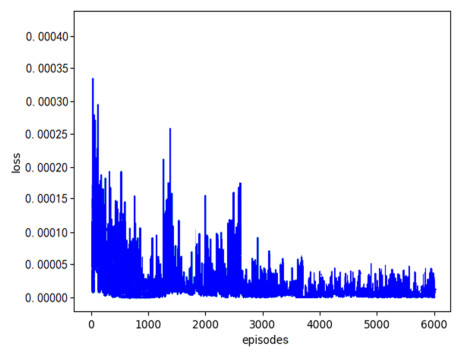
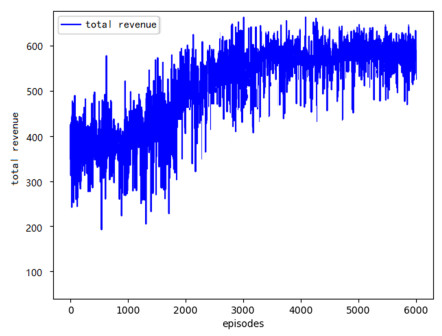
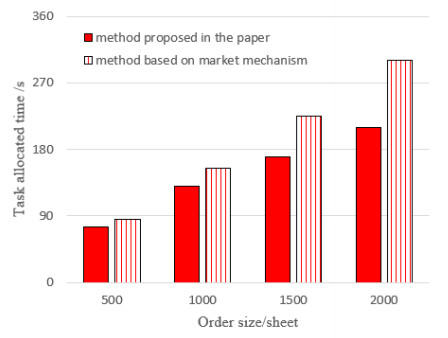
A Robotic Mobile Fulfillment System (RMFS) is a new type of parts-to-picker order fulfillment system where multiple robots coordinate to complete a large number of order picking tasks. The multi-robot task allocation (MRTA) problem in RMFS is complex and dynamic, and it cannot be well solved by traditional MRTA methods. This paper proposes a task allocation method for multiple mobile robots based on multi-agent deep reinforcement learning, which not only has the advantage of reinforcement learning in dealing with dynamic environment but also can solve the task allocation problem of large state space and high complexity utilizing deep learning. First, a multi-agent framework based on cooperative structure is proposed according to the characteristics of RMFS. Then, a multi agent task allocation model is constructed based on Markov Decision Process. In order to avoid inconsistent information among agents and improve the convergence speed of traditional Deep Q Network (DQN), an improved DQN algorithm based on a shared utilitarian selection mechanism and priority empirical sample sampling is proposed to solve the task allocation model. Simulation results show that the task allocation algorithm based on deep reinforcement learning is more efficient than that based on a market mechanism, and the convergence speed of the improved DQN algorithm is much faster than that of the original DQN algorithm.
Citation: Ruiping Yuan, Jiangtao Dou, Juntao Li, Wei Wang, Yingfan Jiang. Multi-robot task allocation in e-commerce RMFS based on deep reinforcement learning[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 1903-1918. doi: 10.3934/mbe.2023087
A Robotic Mobile Fulfillment System (RMFS) is a new type of parts-to-picker order fulfillment system where multiple robots coordinate to complete a large number of order picking tasks. The multi-robot task allocation (MRTA) problem in RMFS is complex and dynamic, and it cannot be well solved by traditional MRTA methods. This paper proposes a task allocation method for multiple mobile robots based on multi-agent deep reinforcement learning, which not only has the advantage of reinforcement learning in dealing with dynamic environment but also can solve the task allocation problem of large state space and high complexity utilizing deep learning. First, a multi-agent framework based on cooperative structure is proposed according to the characteristics of RMFS. Then, a multi agent task allocation model is constructed based on Markov Decision Process. In order to avoid inconsistent information among agents and improve the convergence speed of traditional Deep Q Network (DQN), an improved DQN algorithm based on a shared utilitarian selection mechanism and priority empirical sample sampling is proposed to solve the task allocation model. Simulation results show that the task allocation algorithm based on deep reinforcement learning is more efficient than that based on a market mechanism, and the convergence speed of the improved DQN algorithm is much faster than that of the original DQN algorithm.

| [1] |
N. Boysen, R. D. Koster, F. Weidinger, Warehousing in the e-commerce era: A survey, Eur. J. Oper. Res., 277 (2019), 396–411. https://doi.org/10.1016/j.ejor.2018.08.023 doi: 10.1016/j.ejor.2018.08.023

|
| [2] |
R. D. Koster, T. Le-Duc, K. J. Roodbergen, Design and control of warehouse order picking: A literature review, Eur. J. Oper. Res., 182 (2007), 481–501. https://doi.org/10.1016/j.ejor.2006.07.009 doi: 10.1016/j.ejor.2006.07.009
|
| [3] | M. Wulfraat, Is Kiva systems a good fit for your distribution center? An unbiased distribution consultant evaluation, 2012. Available from: http://www.mwpvl.com/html/kiva_systems.html. |
| [4] |
H. Hu, Q. Zhang, H. Hu, J. Chen, Z. Li, Q-learning based mobile swarm intelligence task allocation algorithm, Comput. Integr. Manuf. Syst., 24 (2018), 1774–1783. https://doi.org/10.13196/j.cims.2018.07.019 doi: 10.13196/j.cims.2018.07.019
|
| [5] |
L. Mo, L. Su, X. Li, Research and development of task allocation methods in multi-robot systems, Manuf. Autom., 35 (2013), 21–24+28. https://doi.org/10.3969/j.issn.1009-0134.2013.05.07 doi: 10.3969/j.issn.1009-0134.2013.05.07
|
| [6] |
Z. Shi, Q. C, Cooperative task allocation for multiple UAVs based on improved multi objective quantum behaved particle swarm optimization algorithm, J. Nanjing Univ. Sci. Technol., 36 (2012), 945–951. https://doi.org/10.14177/j.cnki.32-1397n.2012.06.013 doi: 10.14177/j.cnki.32-1397n.2012.06.013
|
| [7] |
B. H. Sun, H. Wang, B. F. Fang, Z. L. Ling, J. Lin, Task allocation in emotional robot pursuit based on self-organizing algorithm, Robot, 39 (2017), 680–687. https://doi.org/10.13973/j.cnki.robot.2017.0680 doi: 10.13973/j.cnki.robot.2017.0680
|
| [8] |
B. F. Fang, L. Chen, H. Wang, S. L. Dai, Q. B. Zhong, Research on multirobot pursuit task allocation algorithm based on emotional cooperation factor, Sci. World J., (2014), 864180. https://doi.org/10.1155/2014/864180 doi: 10.1155/2014/864180
|
| [9] |
L. Liu, X. C. Ji, Z. Q. Zheng, Multi-robot task allocation based on market and capability classification, Robot, 28 (2006), 337–343. https://doi.org/10.13973/j.cnki.robot.2006.03.019 doi: 10.3321/j.issn:1002-0446.2006.03.019
|
| [10] | F. Janati, F. Abdollahi, S. S. Ghidary, M. Jannatifar, J. Baltes, S. Sadeghnejad, Multi-robot task allocation using clustering method, in Robot Intelligence Technology and Applications 4, Springer, Cham, 447 (2017), 233–247. https://doi.org/10.1007/978-3-319-31293-4_19 |
| [11] |
A. Farinelli, L. Iocchi, D. Nardi, Distributed on-line dynamic task assignment for multi-robot patrolling, Auton. Robots, 41 (2017), 1321–1345. https://doi.org/10.1007/s10514-016-9579-8 doi: 10.1007/s10514-016-9579-8
|
| [12] | B. Heap, M. Pagnucco, Repeated sequential single-cluster auctions with dynamic tasks for multi-robot task allocation with pickup and delivery, in German Conference on Multiagent System Technologies, 8076 (2013), 87–100. https://doi.org/10.1007/978-3-642-40776-5_10 |
| [13] |
H. Zhao, C. Shi, Exploration of the unknown environment of multi-robot collaboration based on market method, Comput. Digital Eng., 45 (2017), 2085–2089. https://doi.org/10.3969/j.issn.1672-9722.2017.11.001 doi: 10.3969/j.issn.1672-9722.2017.11.001
|
| [14] |
R. Yuan, J. Li, X. Wang, L. He, Multirobot task allocation in e-commerce robotic mobile fulfillment systems, Math. Probl. Eng., (2021), 6308950. https://doi.org/10.1155/2021/6308950 doi: 10.1155/2021/6308950
|
| [15] |
B. P. Zou, Y. M. Gong, X. H. Xu, Z. Yuan, Assignment rules in robotic mobile fulfilment systems for online retailers, Int. J. Prod. Res., 55 (2017), 6175–6192. https://doi.org/10.1080/00207543.2017.1331050 doi: 10.1080/00207543.2017.1331050
|
| [16] |
D. Roy, S. Nigam, R. D. Koster, I. Adan, J. Resing, Robot-storage zone assignment strategies in mobile fulfillment systems, Transp. Res. Part E Logist. Transp. Rev., 122 (2019), 119–142. https://doi.org/10.1016/j.tre.2018.11.005 doi: 10.1016/j.tre.2018.11.005
|
| [17] |
Z. Yuan, Y. Y. Gong, Bot-in-time delivery for robotic mobile fulfillment systems, IEEE Trans. Eng. Manage., 64 (2017), 83–93. https://doi.org/10.1109/TEM.2016.2634540 doi: 10.1109/TEM.2016.2634540
|
| [18] | P. Ghassemi, S. Chowdhury, Decentralized task allocation in multi-robot systems via bipartite graph matching augmented with fuzzy clustering, in The ASME 2018 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, 2018. https://doi.org/10.1115/DETC2018-86161 |
| [19] |
K. R. Gue, K. Furmans, Z. Seibold, U. Onur, Grid store a puzzle-based storage system with decentralized control, IEEE Trans. Autom. Sci. Eng., 11 (2014), 429–438. https://doi.org/10.1109/TASE.2013.2278252 doi: 10.1109/TASE.2013.2278252
|
| [20] |
B. W. Shen, N. B. Yu, J. T. Liu, Intelligent scheduling and path planning of warehouse mobile robots, CAAI Trans. Intell. Syst., 9 (2014), 659–664. https://doi.org/10.3969/j.issn.1673-4785.201312048 doi: 10.3969/j.issn.1673-4785.201312048
|
| [21] |
R. P. Yuan, H. L. Wang, L. R. Sun, J. T. Li, Research on the task scheduling of "goods to picker" order picking system based on logistics AGV, Oper. Res. Manage. Sci., 27 (2018), 133–138. https://doi.org/10.12005/orms.2018.0241 doi: 10.12005/orms.2018.0241
|
| [22] |
J. T. Zhang, F. X. Yang, X. Weng, A building-block-based genetic algorithm for solving the robots allocation problem in a robotic mobile fulfillment system, Math. Probl. Eng., (2019), 6153848. https://doi.org/10.1155/2019/6153848 doi: 10.1155/2019/6153848
|
| [23] |
M. Zolfpour-Arokhlo, A. Selamat, S. Z. M. Hashim, H. Afkhami, Modeling of route planning system based on Q value-based dynamic programming with multi-agent reinforcement learning algorithms, Eng. Appl. Artif. Intell., 29 (2014), 163–177. https://doi.org/10.1016/ j.engappai.2014.01.001 doi: 10.1016/j.engappai.2014.01.001
|
| [24] |
J. Dou, C. Chen, P. Yang, Genetic scheduling and reinforcement learning in multirobot systems for intelligent warehouses, Math. Probl. Eng., (2015), 597956. https://doi.org/10.1155/2015/597956 doi: 10.1155/2015/597956
|
| [25] |
M. Chen, A. Liu, W. Liu, K. Ota, M. Dong, N. N. Xiong, RDRL: A Recurrent deep reinforcement learning scheme for dynamic spectrum access in reconfigurable wireless networks, IEEE Trans. Network Sci. Eng., 9 (2022), 364–376. https://doi.org/10.1109/TNSE.2021.3117565 doi: 10.1109/TNSE.2021.3117565
|
| [26] |
M. Chen, W. Liu, N. Zhang, J. Li, Y. Ren, M. Yi, et al., GPDS: A multi-agent deep reinforcement learning game for anti-jamming secure computing in MEC network, Expert Syst. Appl., 210 (2022), 118394. https://doi.org/10.1016/j.eswa.2022.118394 doi: 10.1016/j.eswa.2022.118394
|
| [27] |
B. Park, C. Kang, J. Choi, Cooperative multi-robot task allocation with reinforcement learning, Appl. Sci., 12(2022), 272–291. https://doi.org/10.3390/app12010272 doi: 10.3390/app12010272
|
| [28] | Y. D. Wang, Research on Multi-Object Workflow Scheduling Method Based on Deep-Q-Network Multi-Agent Reinforcement Learning, MA.Sc thesis, Chongqing University, 2019. https://doi.org/10.27670/d.cnki.gcqdu.2019.000536 |
Figures(8) / Tables(1)

Ruiping Yuan, Jiangtao Dou, Juntao Li, Wei Wang, Yingfan Jiang. Multi-robot task allocation in e-commerce RMFS based on deep reinforcement learning[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 1903-1918. doi: 10.3934/mbe.2023087







 DownLoad:
DownLoad: