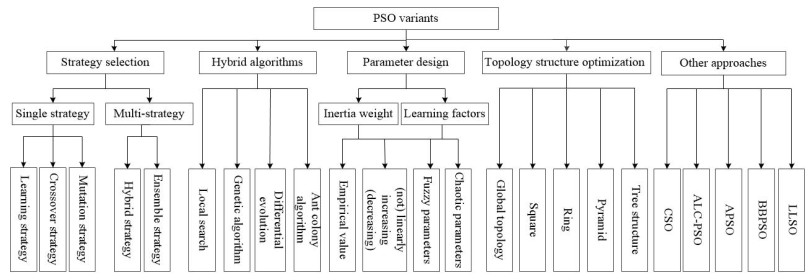
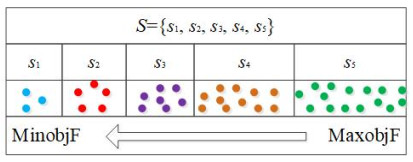
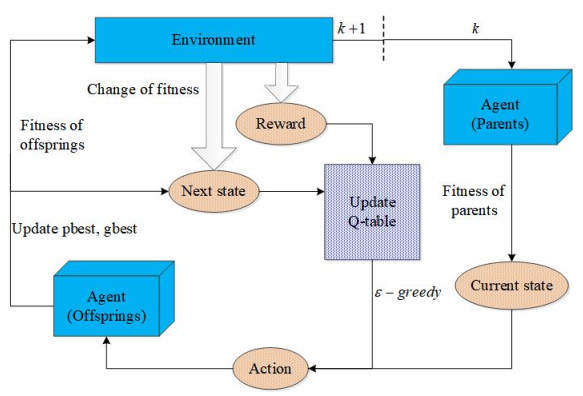
The trade-off between exploitation and exploration is a dilemma inherent to particle swarm optimization (PSO) algorithms. Therefore, a growing body of PSO variants is devoted to solving the balance between the two. Among them, the method of self-adaptive multi-strategy selection plays a crucial role in improving the performance of PSO algorithms but has yet to be well exploited. In this research, with the aid of the reinforcement learning technique to guide the generation of offspring, a novel self-adaptive multi-strategy selection mechanism is designed, and then a multi-strategy self-learning PSO algorithm based on reinforcement learning (MPSORL) is proposed. First, the fitness value of particles is regarded as a set of states that are divided into several state subsets non-uniformly. Second, the $ \varepsilon $-greedy strategy is employed to select the optimal strategy for each particle. The personal best particle and the global best particle are then updated after executing the strategy. Subsequently, the next state is determined. Thus, the value of the Q-table, as a scheme adopted in self-learning, is reshaped by the reward value, the action and the state in a non-stationary environment. Finally, the proposed algorithm is compared with other state-of-the-art algorithms on two well-known benchmark suites and a real-world problem. Extensive experiments indicate that MPSORL has better performance in terms of accuracy, convergence speed and non-parametric tests in most cases. The multi-strategy selection mechanism presented in the manuscript is effective.
Citation: Xiaoding Meng, Hecheng Li, Anshan Chen. Multi-strategy self-learning particle swarm optimization algorithm based on reinforcement learning[J]. Mathematical Biosciences and Engineering, 2023, 20(5): 8498-8530. doi: 10.3934/mbe.2023373
The trade-off between exploitation and exploration is a dilemma inherent to particle swarm optimization (PSO) algorithms. Therefore, a growing body of PSO variants is devoted to solving the balance between the two. Among them, the method of self-adaptive multi-strategy selection plays a crucial role in improving the performance of PSO algorithms but has yet to be well exploited. In this research, with the aid of the reinforcement learning technique to guide the generation of offspring, a novel self-adaptive multi-strategy selection mechanism is designed, and then a multi-strategy self-learning PSO algorithm based on reinforcement learning (MPSORL) is proposed. First, the fitness value of particles is regarded as a set of states that are divided into several state subsets non-uniformly. Second, the $ \varepsilon $-greedy strategy is employed to select the optimal strategy for each particle. The personal best particle and the global best particle are then updated after executing the strategy. Subsequently, the next state is determined. Thus, the value of the Q-table, as a scheme adopted in self-learning, is reshaped by the reward value, the action and the state in a non-stationary environment. Finally, the proposed algorithm is compared with other state-of-the-art algorithms on two well-known benchmark suites and a real-world problem. Extensive experiments indicate that MPSORL has better performance in terms of accuracy, convergence speed and non-parametric tests in most cases. The multi-strategy selection mechanism presented in the manuscript is effective.

| [1] |
E. H. Houssein, A. G. Gad, K. Hussain, P. N. Suganthan, Major advances in particle swarm optimization: theory, analysis, and application, Swarm Evol. Comput., 63 (2021), 100868. https://doi.org/10.1016/j.swevo.2021.100868 doi: 10.1016/j.swevo.2021.100868

|
| [2] |
H. J. Park, S. W. Cho, C. Lee, Particle swarm optimization algorithm with time buffer insertion for robust berth scheduling, Comput. Ind. Eng., 160 (2021), 107585. https://doi.org/10.1016/j.cie.2021.107585 doi: 10.1016/j.cie.2021.107585
|
| [3] |
X. Song, Y. Zhang, D. Gong, H. Liu, W. Zhang, Surrogate sample-assisted particle swarm optimization for feature selection on high-dimensional data, IEEE Trans. Evol. Comput., 2022 (2022). https://doi.org/10.1109/TEVC.2022.3175226 doi: 10.1109/TEVC.2022.3175226
|
| [4] |
X. Liu, Y. Du, M. Jiang, X. Zeng, Multiobjective particle swarm optimization based on network embedding for complex network community detection, IEEE Trans. Comput. Soc. Syst., 7 (2020), 437–449. https://doi.org/10.1109/tcss.2020.2964027 doi: 10.1109/tcss.2020.2964027
|
| [5] |
R. Jin, P. Hou, G. Yang, Y. Qi, C. Chen, Z. Chen, Cable routing optimization for offshore wind power plants via wind scenarios considering power loss cost model, Appl. Energy, 254 (2019), 113719. https://doi.org/10.1016/j.apenergy.2019.113719 doi: 10.1016/j.apenergy.2019.113719
|
| [6] |
J. J. Liang, A. K. Qin, P. N. Suganthan, S. Baskar, Comprehensive learning particle swarm optimizer for global optimization of multimodal functions, IEEE Trans. Evol. Comput., 10 (2006), 281–295. https://doi.org/10.1109/tevc.2005.857610 doi: 10.1109/tevc.2005.857610
|
| [7] |
N. Lynn, P. N. Suganthan, Heterogeneous comprehensive learning particle swarm optimization with enhanced exploration and exploitation, Swarm Evol. Comput., 24 (2015), 11–24. https://doi.org/10.1016/j.swevo.2015.05.002 doi: 10.1016/j.swevo.2015.05.002
|
| [8] |
Z. Liu, T. Nishi, Strategy dynamics particle swarm optimizer, Inf. Sci., 582 (2022), 665–703. https://doi.org/10.1016/j.ins.2021.10.028 doi: 10.1016/j.ins.2021.10.028
|
| [9] |
R. P. Parouha, P. Verma, Design and applications of an advanced hybrid meta-heuristic algorithm for optimization problems, Artif. Intell. Rev., 54 (2021), 5931–6010. https://doi.org/10.1007/s10462-021-09962-6 doi: 10.1007/s10462-021-09962-6
|
| [10] |
Y. Gong, J. Li, Y. Zhou, Y. Li, H. S. Chung, Y. Shi, et al., Genetic learning particle swarm optimization, IEEE Trans. Cybern., 46 (2015), 2277–2290. https://doi.org/10.1109/tcyb.2015.2475174 doi: 10.1109/tcyb.2015.2475174
|
| [11] |
S. Wang, Y. Li, H. Yang, Self-adaptive mutation differential evolution algorithm based on particle swarm optimization, Appl. Soft Comput., 81 (2019), 105496. https://doi.org/10.1016/j.asoc.2019.105496 doi: 10.1016/j.asoc.2019.105496
|
| [12] |
M. S. Nobile, P. Cazzaniga, D. Besozzi, R. Colombo, G. Mauri, G. Pasi, Fuzzy self-tuning pso: A settings-free algorithm for global optimization, Swarm Evol. Comput., 39 (2018), 70–85. https://doi.org/10.1016/j.swevo.2017.09.001 doi: 10.1016/j.swevo.2017.09.001
|
| [13] |
A. Ratnaweera, S. K. Halgamuge, H. C. Watson, Self-organizing hierarchical particle swarm optimizer with time-varying acceleration coefficients, IEEE Trans. Evol. Comput., 8 (2004), 240–255. https://doi.org/10.1109/tevc.2004.826071 doi: 10.1109/tevc.2004.826071
|
| [14] |
R. Vafashoar, H. Morshedlou, M. R. Meybodi, Bifurcated particle swarm optimizer with topology learning particles, Appl. Soft Comput., 114 (2022), 108039. https://doi.org/10.1016/j.asoc.2021.108039 doi: 10.1016/j.asoc.2021.108039
|
| [15] |
R. Mendes, J. Kennedy, J. Neves, The fully informed particle swarm: simpler, maybe better, IEEE Trans. Evol. Comput., 8 (2004), 204–210. https://doi.org/10.1109/tevc.2004.826074 doi: 10.1109/tevc.2004.826074
|
| [16] |
R. Cheng, Y. Jin, A competitive swarm optimizer for large scale optimization, IEEE Trans. Cybern., 45 (2014), 191–204. https://doi.org/10.1109/tcyb.2014.2322602 doi: 10.1109/tcyb.2014.2322602
|
| [17] |
W. Chen, J. Zhang, Y. Lin, N. Chen, Z. Zhan, H. S. Chung, et al., Particle swarm optimization with an aging leader and challengers, IEEE Trans. Evol. Comput., 17 (2012), 241–258. https://doi.org/10.1109/tevc.2011.2173577 doi: 10.1109/tevc.2011.2173577
|
| [18] |
Z. Zhan, J. Zhang, Y. Li, H. S. Chung, Adaptive particle swarm optimization, IEEE Trans. Syst. Man Cybern. B Cybern., 39 (2009), 1362–1381. https://doi.org/10.1109/tsmcb.2009.2015956 doi: 10.1109/tsmcb.2009.2015956
|
| [19] | J. Kennedy, Bare bones particle swarms, in Proceedings of the 2003 IEEE Swarm Intelligence Symposium. SIS'03 (Cat. No. 03EX706), (2003), 80–87. https://doi.org/10.1109/sis.2003.1202251 |
| [20] |
Q. Yang, W. Chen, J. D. Deng, Y. Li, T. Gu, J. Zhang, A level-based learning swarm optimizer for large-scale optimization, IEEE Trans. Evol. Comput., 22 (2017), 578–594. https://doi.org/10.1109/tevc.2017.2743016 doi: 10.1109/tevc.2017.2743016
|
| [21] |
B. Liang, Y. Zhao, Y. Li, A hybrid particle swarm optimization with crisscross learning strategy, Eng. Appl. Artif. Intell., 105 (2021), 104418. https://doi.org/10.1016/j.engappai.2021.104418 doi: 10.1016/j.engappai.2021.104418
|
| [22] |
G. Xu, Q. Cui, X. Shi, H. Ge, Z. H. Zhan, H. P. Lee, et al., Particle swarm optimization based on dimensional learning strategy, Swarm Evol. Comput., 45 (2019), 33–51. https://doi.org/10.1016/j.swevo.2018.12.009 doi: 10.1016/j.swevo.2018.12.009
|
| [23] |
Y. Chen, L. Li, J. Xiao, Y. Yang, J. Liang, T. Li, Particle swarm optimizer with crossover operation, Eng. Appl. Artif. Intell., 70 (2018), 159–169. https://doi.org/10.1016/j.engappai.2018.01.009 doi: 10.1016/j.engappai.2018.01.009
|
| [24] |
X. Zhang, H. Liu, T. Zhang, Q. Wang, Y. Wang, L. Tu, Terminal crossover and steering-based particle swarm optimization algorithm with disturbance, Appl. Soft Comput., 85 (2019), 105841. https://doi.org/10.1016/j.asoc.2019.105841 doi: 10.1016/j.asoc.2019.105841
|
| [25] |
X. Tao, W. Guo, Q. Li, C. Ren, R. Liu, Multiple scale self-adaptive cooperation mutation strategy-based particle swarm optimization, Appl. Soft Comput., 89 (2020), 106124. https://doi.org/10.1016/j.asoc.2020.106124 doi: 10.1016/j.asoc.2020.106124
|
| [26] |
W. Li, X. Meng, Y. Huang, Z. Fu, Multipopulation cooperative particle swarm optimization with a mixed mutation strategy, Inf. Sci., 529 (2020), 179–196. https://doi.org/10.1016/j.ins.2020.02.034 doi: 10.1016/j.ins.2020.02.034
|
| [27] |
W. Huang, W. Zhang, Adaptive multi-objective particle swarm optimization with multi-strategy based on energy conversion and explosive mutation, Appl. Soft Comput., 113 (2021), 107937. https://doi.org/10.1016/j.asoc.2021.107937 doi: 10.1016/j.asoc.2021.107937
|
| [28] |
H. Wang, Z. Wu, S. Rahnamayan, Y. Liu, M. Ventresca, Enhancing particle swarm optimization using generalized opposition-based learning, Inf. Sci., 181 (2011), 4699–4714. https://doi.org/10.1016/j.ins.2011.03.016 doi: 10.1016/j.ins.2011.03.016
|
| [29] |
H. Ouyang, L. Gao, S. Li, X. Kong, Improved global-best-guided particle swarm optimization with learning operation for global optimization problems, Appl. Soft Comput., 52 (2017), 987–1008. https://doi.org/10.1016/j.asoc.2016.09.030 doi: 10.1016/j.asoc.2016.09.030
|
| [30] |
X. Zhang, X. Wang, Q. Kang, J. Cheng, Differential mutation and novel social learning particle swarm optimization algorithm, Inf. Sci., 480 (2019), 109–129. https://doi.org/10.1016/j.ins.2018.12.030 doi: 10.1016/j.ins.2018.12.030
|
| [31] |
S. Wang, G. Liu, M. Gao, S. Cao, A. Guo, J. Wang, Heterogeneous comprehensive learning and dynamic multi-swarm particle swarm optimizer with two mutation operators, Inf. Sci., 540 (2020), 175–201. https://doi.org/10.1016/j.ins.2020.06.027 doi: 10.1016/j.ins.2020.06.027
|
| [32] |
X. Tao, X. Li, W. Chen, T. Liang, Y. Li, J. Guo, et al., Self-adaptive two roles hybrid learning strategies-based particle swarm optimization, Inf. Sci., 578 (2021), 457–481. https://doi.org/10.1016/j.ins.2021.07.008 doi: 10.1016/j.ins.2021.07.008
|
| [33] |
H. Wang, M. Liang, C. Sun, G. Zhang, L. Xie, Multiple-strategy learning particle swarm optimization for large-scale optimization problems, Complex Intell. Syst., 7 (2021), 1–16. https://doi.org/10.1007/s40747-020-00148-1 doi: 10.1007/s40747-020-00148-1
|
| [34] |
N. Lynn, P. N. Suganthan, Ensemble particle swarm optimizer, Appl. Soft Comput., 55 (2017), 533–548. https://doi.org/10.1016/j.asoc.2017.02.007 doi: 10.1016/j.asoc.2017.02.007
|
| [35] |
C. Li, S. Yang, T. T. Nguyen, A self-learning particle swarm optimizer for global optimization problems, IEEE Trans. Syst. Man Cybern. B Cybern., 42 (2011), 627–646. https://doi.org/10.1109/tsmcb.2011.2171946 doi: 10.1109/tsmcb.2011.2171946
|
| [36] |
M. M. Drugan, Reinforcement learning versus evolutionary computation: A survey on hybrid algorithms, Swarm Evol. Comput., 44 (2019), 228–246. https://doi.org/10.1016/j.swevo.2018.03.011 doi: 10.1016/j.swevo.2018.03.011
|
| [37] | R. S. Sutton, A. G. Barto, Reinforcement Learning: An Introduction, MIT press, 1998. https://doi.org/10.1109/tnn.1998.712192 |
| [38] | Y. Liu, H. Lu, S. Cheng, Y. Shi, An adaptive online parameter control algorithm for particle swarm optimization based on reinforcement learning, in 2019 IEEE Congress on Evolutionary Computation (CEC), (2019), 815–822. https://doi.org/10.1109/cec.2019.8790035 |
| [39] |
F. Wang, X. Wang, S. Sun, A reinforcement learning level-based particle swarm optimization algorithm for large-scale optimization, Inf. Sci., 602 (2022), 298–312. https://doi.org/10.1016/j.ins.2022.04.053 doi: 10.1016/j.ins.2022.04.053
|
| [40] |
Z. Li, L. Shi, C. Yue, Z. Shang, B. Qu, Differential evolution based on reinforcement learning with fitness ranking for solving multimodal multiobjective problems, Swarm Evol. Comput., 49 (2019), 234–244. https://doi.org/10.1016/j.swevo.2019.06.010 doi: 10.1016/j.swevo.2019.06.010
|
| [41] |
Z. Hu, W. Gong, Constrained evolutionary optimization based on reinforcement learning using the objective function and constraints, Knowl. Based Syst., 237 (2022), 107731. https://doi.org/10.1016/j.knosys.2021.107731 doi: 10.1016/j.knosys.2021.107731
|
| [42] |
F. Zou, G. G. Yen, L. Tang, C. Wang, A reinforcement learning approach for dynamic multi-objective optimization, Inf. Sci., 546 (2021), 815–834. https://doi.org/10.1016/j.ins.2020.08.101 doi: 10.1016/j.ins.2020.08.101
|
| [43] |
Y. Tian, X. Li, H. Ma, X. Zhang, K. C. Tan, Y. Jin, Deep reinforcement learning based adaptive operator selection for evolutionary multi-objective optimization, IEEE Trans. Emerging Top. Comput. Intell., 2022 (2022). https://doi.org/10.1109/tetci.2022.3146882 doi: 10.1109/tetci.2022.3146882
|
| [44] |
P. Yin, C. Chao, Automatic selection of fittest energy demand predictors based on cyber swarm optimization and reinforcement learning, Appl. Soft Comput., 71 (2018), 152–164. https://doi.org/10.1016/j.asoc.2018.06.042 doi: 10.1016/j.asoc.2018.06.042
|
| [45] |
L. Lu, H. Zheng, J. Jie, M. Zhang, R. Dai, Reinforcement learning-based particle swarm optimization for sewage treatment control, Complex Intell. Syst., 7 (2021), 2199–2210. https://doi.org/10.1007/s40747-021-00395-w doi: 10.1007/s40747-021-00395-w
|
| [46] |
T. N. Huynh, D. T. T. Do, J. Lee, Q-learning-based parameter control in differential evolution for structural optimization, Appl. Soft Comput., 107 (2021), 107464. https://doi.org/10.1016/j.asoc.2021.107464 doi: 10.1016/j.asoc.2021.107464
|
| [47] |
M. I. Radaideh, K. Shirvan, Rule-based reinforcement learning methodology to inform evolutionary algorithms for constrained optimization of engineering applications, Knowl. Based Syst., 217 (2021), 106836. https://doi.org/10.1016/j.knosys.2021.106836 doi: 10.1016/j.knosys.2021.106836
|
| [48] |
R. Li, W. Gong, C. Lu, A reinforcement learning based RMOEA/D for bi-objective fuzzy flexible job shop scheduling, Expert Syst. Appl., 203 (2022), 117380. https://doi.org/10.1016/j.eswa.2022.117380 doi: 10.1016/j.eswa.2022.117380
|
| [49] | J. Kennedy, R. Eberhart, Particle swarm optimization, in Proceedings of ICNN'95-International Conference on Neural Networks, 4 (1995), 1942–1948. https://doi.org/10.1109/icnn.1995.488968 |
| [50] | Y. Shi, R. Eberhart, A modified particle swarm optimizer, in 1998 IEEE International Conference on Evolutionary Computation Proceedings. IEEE World Congress on Computational iIntelligence (Cat. No. 98TH8360), (1998), 69–73. https://doi.org/10.1109/icec.1998.699146 |
| [51] |
C. J. C. H. Watkins, P. Dayan, Q-learning, Mach. Learn., 8 (1992), 279–292. https://doi.org/10.1007/bf00992698 doi: 10.1007/bf00992698
|
| [52] |
B. Y. Qu, P. N. Suganthan, S. Das, A distance-based locally informed particle swarm model for multimodal optimization, IEEE Trans. Evol. Comput., 17 (2013), 387–402. https://doi.org/10.1109/tevc.2012.2203138 doi: 10.1109/tevc.2012.2203138
|
| [53] | K. E. Parsopoulos, M. N. Vrahatis, A unified particle swarm optimization scheme, in Proceedings of the IEEE International Conference of Computational Methods in Sciences and Engineering, (2004), 221–226. https://doi.org/10.1201/9780429081385-222 |
| [54] | N. H. Awad, M. Z. Ali, P. N. Suganthan, J. J. Liang, B. Y. Qu, Problem definitions and evaluation criteria for the CEC 2017 special session and sompetition on single objective real-parameter numerical optimization, Technical Report, 2016. |
| [55] | K. V. Price, N. H. Awad, M. Z. Ali, P. N. Suganthan, Problem definitions and evaluation criteria for the 100-Digit challenge special session and competition on single objective numerical optimization, Nanyang Technological University Singapore, Technical Report, 2018. |
| [56] |
J. Derrac, S. García, D. Molina, F. Herrera, A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms, Swarm Evol. Comput., 1 (2011), 3–18. https://doi.org/10.1016/j.swevo.2011.02.002 doi: 10.1016/j.swevo.2011.02.002
|
| [57] |
A. LaTorre, D. Molina, E. Osaba, J. Poyatos, J. Del Ser, F. Herrera, A prescription of methodological guidelines for comparing bio-inspired optimization algorithms, Swarm Evol. Comput., 67 (2021), 100973. https://doi.org/10.1016/j.swevo.2021.100973 doi: 10.1016/j.swevo.2021.100973
|
| [58] |
W. Zhao, Z. Zhang, L. Wang, Manta ray foraging optimization: An effective bio-inspired optimizer for engineering applications, Eng. Appl. Artif. Intell., 87 (2020), 103300. https://doi.org/10.1016/j.engappai.2019.103300 doi: 10.1016/j.engappai.2019.103300
|
| [59] |
M. H. N. Shahraki, S. Taghian, S. Mirjalili, An improved grey wolf optimizer for solving engineering problems, Expert Syst. Appl., 166 (2021), 113917. https://doi.org/10.1016/j.eswa.2020.113917 doi: 10.1016/j.eswa.2020.113917
|
| [60] |
P. Civicioglu, E. Besdok, Bezier search differential evolution algorithm for numerical function optimization: A comparative study with CRMLSP, MVO, WA, SHADE and LSHADE, Expert Syst. Appl., 165 (2021), 113875. https://doi.org/10.1016/j.eswa.2020.113875 doi: 10.1016/j.eswa.2020.113875
|
| [61] |
D. H. Wolpert, W. G. Macready, No free lunch theorems for optimization, IEEE Trans. Evol. Comput., 1 (1997), 67–82. https://doi.org/10.1109/4235.585893 doi: 10.1109/4235.585893
|
| [62] | S. Das, P. N. Suganthan, Problem definitions and evaluation criteria for CEC 2011 competition on testing evolutionary algorithms on real world optimization problems, Jadavpur University, Nanyang Technological University, Kolkata, Technical Report, (2010), 341–359. |
| [63] | O. Olorunda, A. P. Engelbrecht, Measuring exploration/exploitation in particle swarms using swarm diversity, in 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence, (2008), 1128–1134. https://doi.org/10.1109/cec.2008.4630938 |

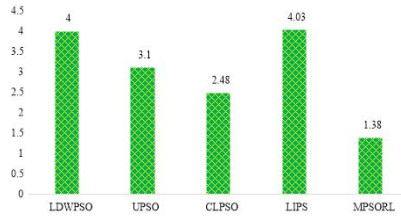
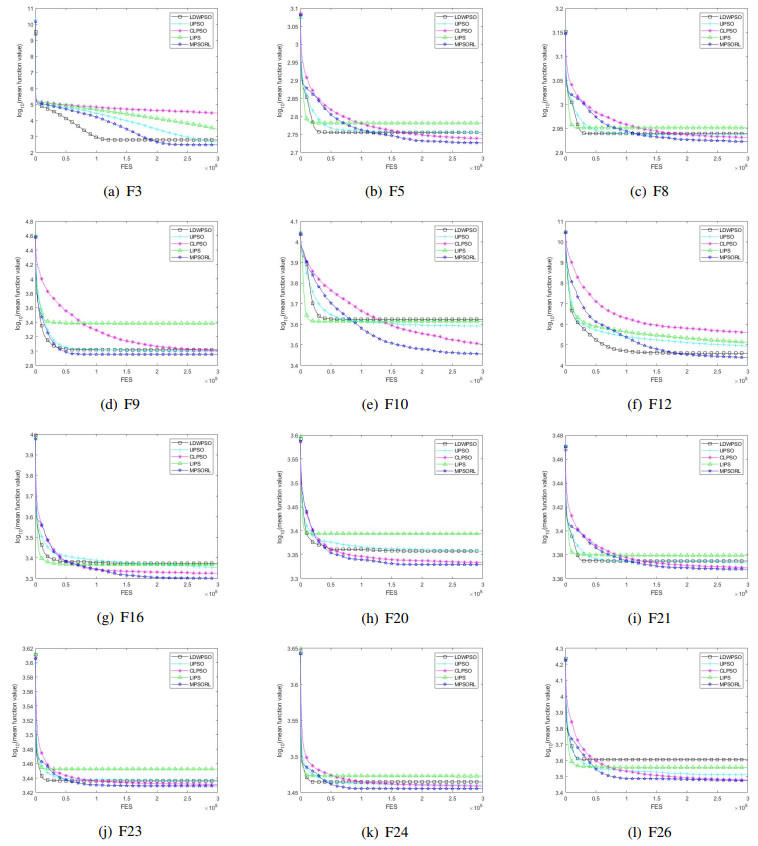
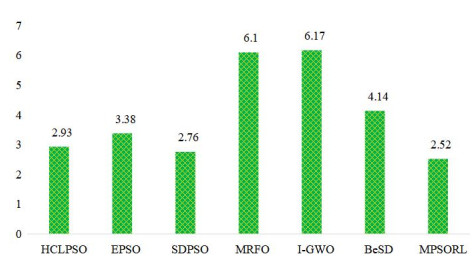
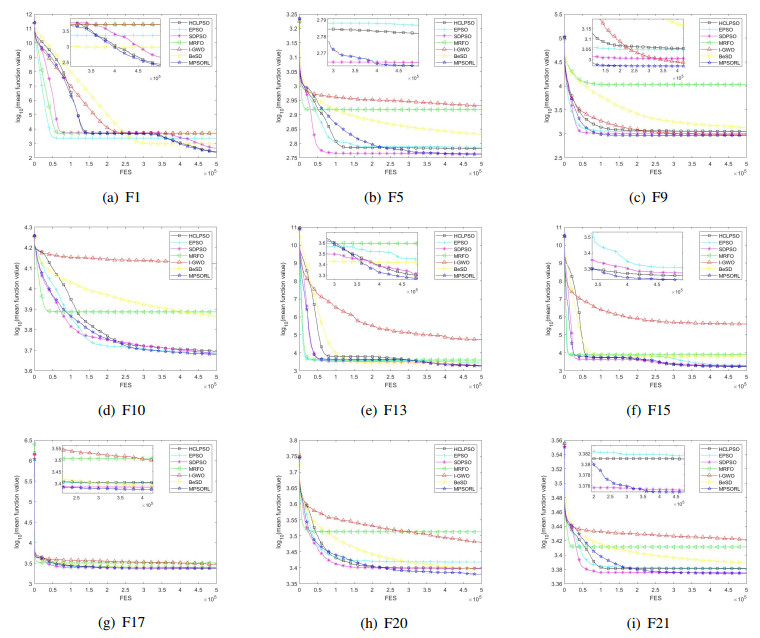
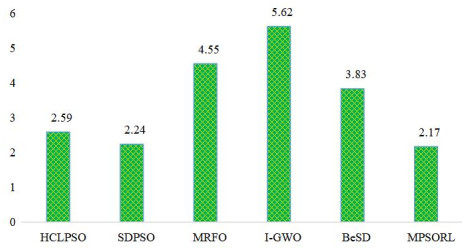
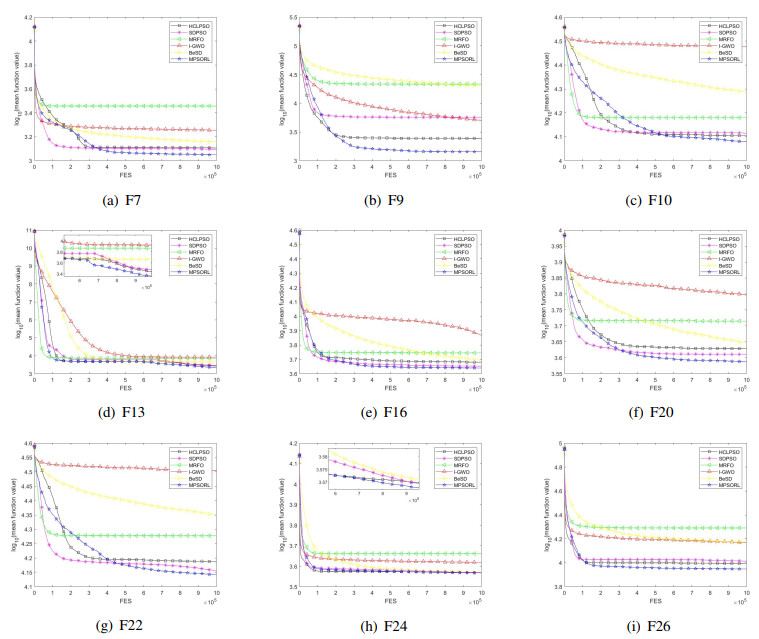
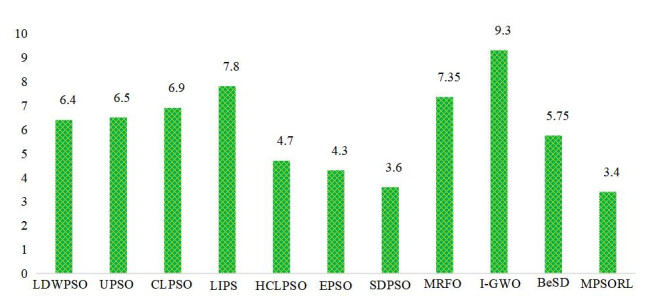
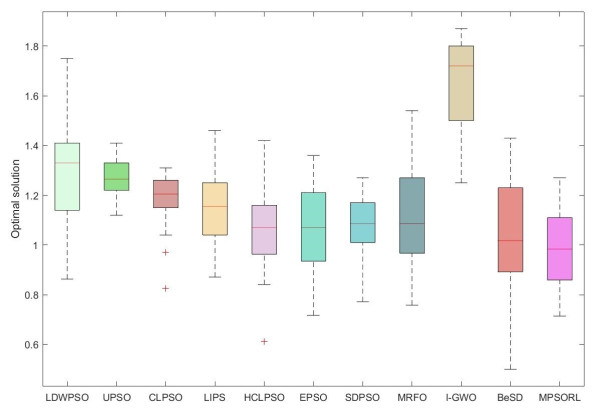


Figures(15) / Tables(13)

Xiaoding Meng, Hecheng Li, Anshan Chen. Multi-strategy self-learning particle swarm optimization algorithm based on reinforcement learning[J]. Mathematical Biosciences and Engineering, 2023, 20(5): 8498-8530. doi: 10.3934/mbe.2023373







 DownLoad:
DownLoad: