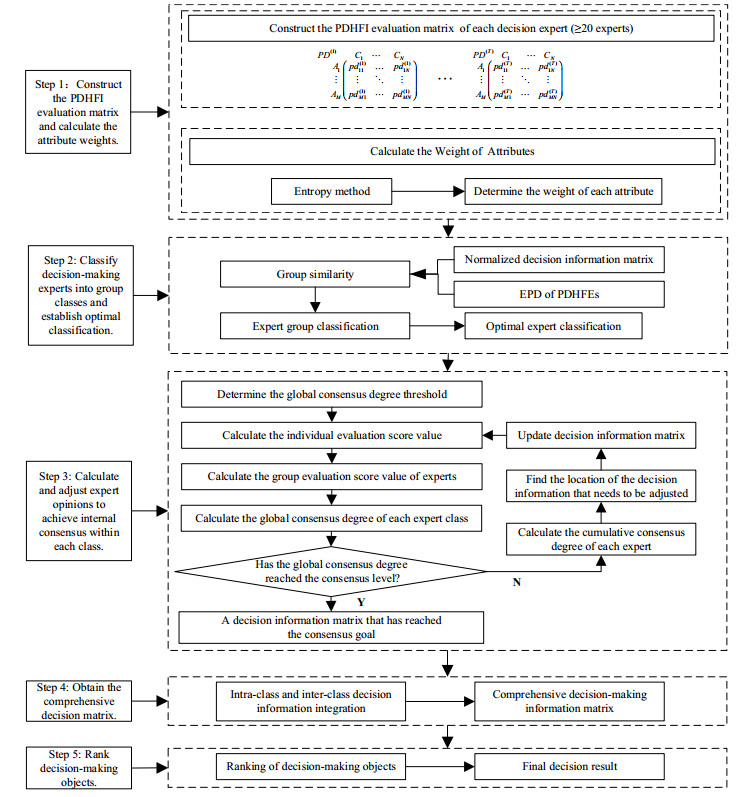
We proposed a novel decision-making method, the large-scale group consensus multi-attribute decision-making method based on probabilistic dual hesitant fuzzy sets, to address the challenge of large-scale group multi-attribute decision-making in fuzzy environments. This method concurrently accounted for the membership and non-membership degrees of decision-making experts in fuzzy environments and the corresponding probabilistic value to quantify expert decision information. Furthermore, it applied to complex scenarios involving groups of 20 or more decision-making experts. We delineated five major steps of the method, elaborating on the specific models and algorithms used in each phase. We began by constructing a probabilistic dual hesitant fuzzy information evaluation matrix and determining attribute weights. The following steps involved classifying large-scale decision-making expert groups and selecting the optimal classification scheme based on effectiveness assessment criteria. A global consensus degree threshold was established, followed by implementing a consensus-reaching model to synchronize opinions within the same class of expert groups. Decision information was integrated within and between classes using an information integration model, leading to a comprehensive decision matrix. Decision outcomes for the objects were then determined through a ranking method. The method's effectiveness and superiority were validated through a case study on urban emergency capability assessment, and its advantages were further emphasized in comparative analyses with other methods.
Citation: Yuting Zhu, Wenyu Zhang, Junjie Hou, Hainan Wang, Tingting Wang, Haining Wang. The large-scale group consensus multi-attribute decision-making method based on probabilistic dual hesitant fuzzy sets[J]. Mathematical Biosciences and Engineering, 2024, 21(3): 3944-3966. doi: 10.3934/mbe.2024175
We proposed a novel decision-making method, the large-scale group consensus multi-attribute decision-making method based on probabilistic dual hesitant fuzzy sets, to address the challenge of large-scale group multi-attribute decision-making in fuzzy environments. This method concurrently accounted for the membership and non-membership degrees of decision-making experts in fuzzy environments and the corresponding probabilistic value to quantify expert decision information. Furthermore, it applied to complex scenarios involving groups of 20 or more decision-making experts. We delineated five major steps of the method, elaborating on the specific models and algorithms used in each phase. We began by constructing a probabilistic dual hesitant fuzzy information evaluation matrix and determining attribute weights. The following steps involved classifying large-scale decision-making expert groups and selecting the optimal classification scheme based on effectiveness assessment criteria. A global consensus degree threshold was established, followed by implementing a consensus-reaching model to synchronize opinions within the same class of expert groups. Decision information was integrated within and between classes using an information integration model, leading to a comprehensive decision matrix. Decision outcomes for the objects were then determined through a ranking method. The method's effectiveness and superiority were validated through a case study on urban emergency capability assessment, and its advantages were further emphasized in comparative analyses with other methods.

| [1] |
Q. Ding, Y. M. Wang, M. Goh, TODIM Dynamic emergency decision-making method based on hybrid weighted distance under probabilistic hesitant fuzzy information, Int. J. Fuzzy Syst., 23 (2021), 474–491. https://doi.org/10.1007/s40815-020-00978-8 doi: 10.1007/s40815-020-00978-8

|
| [2] |
R. Ikram, S. Meshram, M. Hasan, X. Cao, E. Alvandi, C. Meshram, et al., The application of multi-attribute decision making methods in integrated watershed management, Stochastic Environ. Res. Risk Assess., (2023). https://doi.org/10.1007/s00477-023-02557-3 doi: 10.1007/s00477-023-02557-3
|
| [3] |
F. Jin, Y. Zhu, Y. Zhang, S. Guo, J. Liu, L. Zhou, Interval type-2 trapezoidal fuzzy multi-attribute decision-making method and its application to the corporate investment selection, J. Intell. Fuzzy Syst., 45 (2023), 2319–2330. https://doi.org/10.3233/JIFS-230310 doi: 10.3233/JIFS-230310
|
| [4] |
Y. Song, G. Li, A mathematical programming approach to manage group decision making with incomplete hesitant fuzzy linguistic preference relations, Comput. Ind. Eng., 135 (2019), 467–475. https://doi.org/10.1016/j.cie.2019.06.036 doi: 10.1016/j.cie.2019.06.036
|
| [5] |
Y. Song, G. Li, D. Ergu, N. Liu, An optimisation-based method to conduct consistency and consensus in group decision making under probabilistic uncertain linguistic preference relations, J. Oper. Res. Soc., 73 (2022), 840–854. https://doi.org/10.1080/01605682.2021.1873079 doi: 10.1080/01605682.2021.1873079
|
| [6] |
Y. Shen, X. Ma, J. Zhan, A two-stage adaptive consensus reaching model by virtue of three-way clustering for large-scale group decision making, Inf. Sci., 649 (2023), 119658. https://doi.org/10.1016/j.ins.2023.119658 doi: 10.1016/j.ins.2023.119658
|
| [7] |
B. Yu, Z. Zheng, Z. Xiao, Y. Fu, Z. Xu, A large-scale group decision-making method based on group-oriented rough dominance relation in scenic spot service improvement, Expert Syst. Appl., 233 (2023), 120999. https://doi.org/10.1016/j.eswa.2023.120999 doi: 10.1016/j.eswa.2023.120999
|
| [8] |
F. Meng, D. Zhao, X. Zhang, A fair consensus adjustment mechanism for large-scale group decision making in term of Gini coefficient, Eng. Appl. Artif. Intell., 126 (2023), 106962. https://doi.org/10.1016/j.engappai.2023.106962 doi: 10.1016/j.engappai.2023.106962
|
| [9] |
X. Gou, Z. Xu, Double hierarchy linguistic term set and its extensions: The state-of-the-art survey, Int. J. Intell. Syst., 36 (2021), 832–865. https://doi.org/10.1002/int.22323 doi: 10.1002/int.22323
|
| [10] |
Y. Shen, X. Ma, J. Zhan, A two-stage adaptive consensus reaching model by virtue of three-way clustering for large-scale group decision making, Inf. Sci., 649 (2023). https://doi.org/10.1016/j.ins.2023.119658 doi: 10.1016/j.ins.2023.119658
|
| [11] |
X. Zhou, S. Li, C. Wei, Consensus reaching process for group decision-making based on trust network and ordinal consensus measure, Inf. Fusion, 101 (2024). https://doi.org/10.1016/j.inffus.2023.101969 doi: 10.1016/j.inffus.2023.101969
|
| [12] |
S. M. Yu, Z. J. Du, X. Y. Zhang, H. Y. Luo, X. D. Lin, Trust Cop-Kmeans clustering analysis and minimum-cost consensus model considering voluntary trust loss in social network large-scale decision-making, IEEE Trans. Fuzzy Syst., 30 (2022), 2634–2648. https://doi.org/10.1109/TFUZZ.2021.3089745 doi: 10.1109/TFUZZ.2021.3089745
|
| [13] |
Y. Li, Y. Ji, S. Qu, Consensus building for uncertain large-scale group decision-making based on the clustering algorithm and robust discrete optimization, Group Decis. Negotiation, 31 (2022), 453–489. https://doi.org/10.1007/s10726-022-09774-1 doi: 10.1007/s10726-022-09774-1
|
| [14] |
G. R. Yang, X. Wang, R. X. Ding, S. P. Lin, Q. H. Lou, E. Herrera-Viedma, Managing non-cooperative behaviors in large-scale group decision making based on trust relationships and confidence levels of decision makers, Inf. Fusion, 97 (2023), 101820. https://doi.org/10.1016/j.inffus.2023.101820 doi: 10.1016/j.inffus.2023.101820
|
| [15] |
Z. Du, S. Yu, C. Cai, Constrained community detection and multistage multicost consensus in social network large-scale decision-making, IEEE Trans. Comput. Social Syst., (2023). https://doi.org/10.1109/TCSS.2023.3265701 doi: 10.1109/TCSS.2023.3265701
|
| [16] |
S. Yu, X. Zhang, Z. Du, Enhanced minimum-cost consensus: focusing on overadjustment and flexible consensus cost, Inf. Fuusion, 89 (2023), 336–354. https://doi.org/10.1016/j.inffus.2022.08.028 doi: 10.1016/j.inffus.2022.08.028
|
| [17] |
Z. Chen, X. Zhang, R. Rodriguez, W. Pedrycz, L. Martinez, M.J. Skibniewski, Expertise-structure and risk-appetite-integrated two-tiered collective opinion generation framework for large-scale group decision making, IEEE Trans. Fuzzy Syst., 30 (2022), 5496–5510. https://doi.org/10.1109/TFUZZ.2022.3179594 doi: 10.1109/TFUZZ.2022.3179594
|
| [18] |
L. A. Zadeh, Fuzzy logic equals computing with words, IEEE Trans. Fuzzy Syst., 4 (1996), 103–111. https://doi.org/10.1109/91.493904 doi: 10.1109/91.493904
|
| [19] |
K. Atanassov, Intuitionistic fuzzy-sets, Fuzzy Sets Syst., 20 (1986), 87–96. https://doi.org/10.1016/S0165-0114(86)80034-3 doi: 10.1016/S0165-0114(86)80034-3
|
| [20] |
R. R. Yager, Pythagorean membership grades in multicriteria decision making, IEEE Trans. Fuzzy Syst., 22 (2014), 958–965. https://doi.org/10.1109/TFUZZ.2013.2278989. doi: 10.1109/TFUZZ.2013.2278989
|
| [21] |
V. Torra, Hesitant fuzzy sets, Int. J. Intell. Syst., 25 (2010), 529–539. https://doi.org/10.1002/int.20418 doi: 10.1002/int.20418
|
| [22] |
P. Wang, R. Dang, P. Liu, D. Pamucar, Attitude- and cost-driven consistency optimization model for decision-making with probabilistic linguistic preference relation, Comput. Ind. Eng., 186 (2023). https://doi.org/10.1016/j.cie.2023.109748 doi: 10.1016/j.cie.2023.109748
|
| [23] |
P. Liu, P. Wang, W. Pedrycz, Consistency-and consensus-based group decision-making method with incomplete probabilistic linguistic preference relations, IEEE Trans. Fuzzy Syst., 29 (2021), 2565–2579. https://doi.org/10.1109/TFUZZ.2020.3003501 doi: 10.1109/TFUZZ.2020.3003501
|
| [24] |
Z. Xu, W. Zhou, Consensus building with a group of decision makers under the hesitant probabilistic fuzzy environment, Fuzzy Optim. Dec. Making, 16 (2017), 481–503. https://doi.org/10.1007/s10700-016-9257-5 doi: 10.1007/s10700-016-9257-5
|
| [25] |
Z. Hao, Z. Xu, H. Zhao, Z. Su, Probabilistic dual hesitant fuzzy set and its application in risk evaluation, Knowledge-Based Syst., 127 (2017), 16–28. https://doi.org/10.1016/j.knosys.2017.02.033 doi: 10.1016/j.knosys.2017.02.033
|
| [26] |
Y. Zhu, W. Zhang, J. Hou, R. Zhang, Multi-attribute group decision making algorithm with probabilistic dual hesitant fuzzy sets and PROMETHEE method, Comput. Eng. Appl., 58 (2022), 88–97. https://doi.org/10.3778/j.issn.1002-8331.2203-0483 doi: 10.3778/j.issn.1002-8331.2203-0483
|
| [27] |
B. Ning, H. Wang, G. Wei, C. Wei, Several similarity measures of probabilistic dual hesitant fuzzy sets and their applications to new energy vehicle charging station location, Alexandria Eng. J., 71 (2023), 371–385. https://doi.org/10.1016/j.aej.2023.03.052 doi: 10.1016/j.aej.2023.03.052
|
| [28] |
W. Zhang, Y. Zhu, The probabilistic dual hesitant fuzzy multi-attribute decision-making method based on cumulative prospect theory and its application, Axioms, 12 (2023). https://doi.org/10.3390/axioms12100925 doi: 10.3390/axioms12100925
|
| [29] |
Z. Ren, Z. Xu, H. Wang, The strategy selection problem on artificial intelligence with an integrated VIKOR and AHP method under probabilistic dual hesitant fuzzy information, IEEE Access, 7 (2019), 103979–103999. https://doi.org/10.1109/ACCESS.2019.2931405 doi: 10.1109/ACCESS.2019.2931405
|
| [30] |
X. Wang, H. Wang, Z. Xu, Z. Ren, Green supplier selection based on probabilistic dual hesitant fuzzy sets: A process integrating best worst method and superiority and inferiority ranking, Appl. Intell., 52 (2022), 8279–8301. https://doi.org/10.1007/s10489-021-02821-5 doi: 10.1007/s10489-021-02821-5
|
| [31] |
H. Li, F. Li, J. Zuo, J. Sun, C. Yuan, L. Ji, et al., Emergency decision-making system for the large-scale infrastructure: a case study of the south-to-north water diversion project, J. Infrastruct. Syst., 28 (2022). https://doi.org/10.1061/(ASCE)IS.1943-555X.0000659 doi: 10.1061/(ASCE)IS.1943-555X.0000659
|
| [32] |
X. Gou, Z. Xu, H. Liao, F. Herrera, Consensus model handling minority opinions and noncooperative behaviors in large-scale group decision-making under double hierarchy linguistic preference relations, IEEE Trans. Cybern., 51 (2021), 283–296. https://doi.org/10.1109/TCYB.2020.2985069 doi: 10.1109/TCYB.2020.2985069
|
| [33] |
A. Aydogdu, S. Gul, New entropy propositions for interval-valued spherical fuzzy sets and their usage in an extension of ARAS (ARAS-IVSFS), Expert Syst., 39 (2022). https://doi.org/10.1111/exsy.12898 doi: 10.1111/exsy.12898
|
| [34] |
H. Garg, T. Mahmood, U. ur Rehman, Z. Ali, CHFS: Complex hesitant fuzzy sets-their applications to decision making with different and innovative distance measures, CAAI Trans. Intell. Technol., 6 (2021), 93–122. https://doi.org/10.1049/cit2.12016 doi: 10.1049/cit2.12016
|
| [35] | Z. Ma, J. Zhu, S. Zhang, H. Wang, X. Liu, Classification-based aggregation model on large scale group decision making with hesitant fuzzy linguistic information, J. Control Decis., 34 (2019), 167–179. |
| [36] |
L. Wang, H. Xue, Group decision-making method based on expert classification consensus information integration, Symmetry, 12 (2020), 1180. https://doi.org/10.3390/sym12071180 doi: 10.3390/sym12071180
|
| [37] |
H. Hassani, R. Razavi-Far, M. Saif, E. Herrera-Viedma, Consensus-based decision support model and fusion architecture for dynamic decision making, Inf. Sci., 597 (2022), 86–104. https://doi.org/10.1016/j.ins.2022.03.040 doi: 10.1016/j.ins.2022.03.040
|
| [38] |
K. Qi, H. Chai, Q. Duan, Y. Du, Q. Wang, J. Sun, et al., A collaborative emergency decision making approach based on BWM and TODIM under interval 2-tuple linguistic environment, Int. J. Mach. Learn. Cybern., 13 (2022), 383–405. https://doi.org/10.1007/s13042-021-01412-7 doi: 10.1007/s13042-021-01412-7
|
| [39] | S. Zhang, X. Liu, J. Zhu, and Z. Wang, Adaptive consensus model with hesitant fuzzy linguistic information considering individual cumulative consensus contribution, J. Control Decis., 36 (2021), 187–195. |
| [40] |
H. Garg, G. Kaur, Quantifying gesture information in brain hemorrhage patients using probabilistic dual hesitant fuzzy sets with unknown probability information, Comput. Ind. Eng., 140 (2020). https://doi.org/10.1016/j.cie.2019.106211 doi: 10.1016/j.cie.2019.106211
|
| [41] |
Z. Wu, J. Xu, A consensus model for large-scale group decision making with hesitant fuzzy information and changeable clusters, Inf. Fusion, 41 (2018), 217–231. https://doi.org/10.1016/j.inffus.2017.09.011 doi: 10.1016/j.inffus.2017.09.011
|

Figures(2) / Tables(9)

Yuting Zhu, Wenyu Zhang, Junjie Hou, Hainan Wang, Tingting Wang, Haining Wang. The large-scale group consensus multi-attribute decision-making method based on probabilistic dual hesitant fuzzy sets[J]. Mathematical Biosciences and Engineering, 2024, 21(3): 3944-3966. doi: 10.3934/mbe.2024175







 DownLoad:
DownLoad: