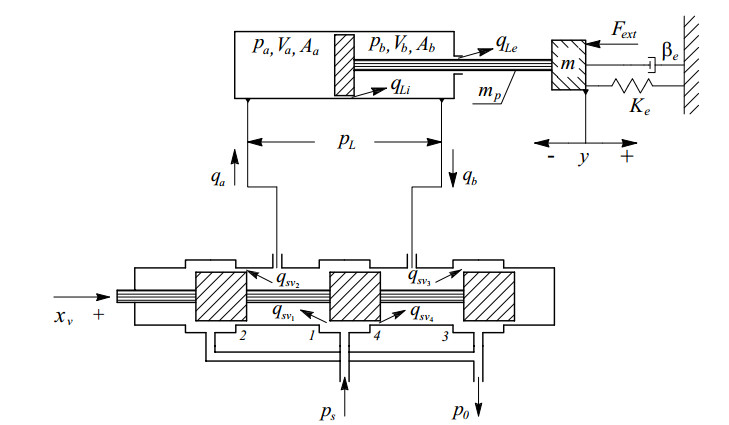
Hydraulic servo actuators (HSAs) are often used in the industry in tasks that request great power, high accuracy and dynamic motion. It is well known that an HSA is a highly complex nonlinear system, and that the system parameters cannot be accurately determined due to various uncertainties, an inability to measure some parameters and disturbances. This paper considers an event-triggered learning control problem of the HSA with unknown dynamics based on adaptive dynamic programming (ADP) via output feedback. Due to increasing practical application of the control algorithm, a linear discrete model of HSA is considered and an online learning data driven controller is used, which is based on measured input and output data instead of unmeasurable states and unknown system parameters. Hence, the ADP-based data driven controller in this paper requires neither the knowledge of the HSA dynamics nor exosystem dynamics. Then, an event-based feedback strategy is introduced to the closed-loop system to save the communication resources and reduce the number of control updates. The convergence of the ADP-based control algorithm is also theoretically shown. Simulation results verify the feasibility and effectiveness of the proposed approach in solving the optimal control problem of HSAs.
Citation: Vladimir Djordjevic, Hongfeng Tao, Xiaona Song, Shuping He, Weinan Gao, Vladimir Stojanovic. Data-driven control of hydraulic servo actuator: An event-triggered adaptive dynamic programming approach[J]. Mathematical Biosciences and Engineering, 2023, 20(5): 8561-8582. doi: 10.3934/mbe.2023376
Hydraulic servo actuators (HSAs) are often used in the industry in tasks that request great power, high accuracy and dynamic motion. It is well known that an HSA is a highly complex nonlinear system, and that the system parameters cannot be accurately determined due to various uncertainties, an inability to measure some parameters and disturbances. This paper considers an event-triggered learning control problem of the HSA with unknown dynamics based on adaptive dynamic programming (ADP) via output feedback. Due to increasing practical application of the control algorithm, a linear discrete model of HSA is considered and an online learning data driven controller is used, which is based on measured input and output data instead of unmeasurable states and unknown system parameters. Hence, the ADP-based data driven controller in this paper requires neither the knowledge of the HSA dynamics nor exosystem dynamics. Then, an event-based feedback strategy is introduced to the closed-loop system to save the communication resources and reduce the number of control updates. The convergence of the ADP-based control algorithm is also theoretically shown. Simulation results verify the feasibility and effectiveness of the proposed approach in solving the optimal control problem of HSAs.

| [1] | J. Vyas, B. Gopalsamy, H. Joshi, Electro-Hydraulic Actuation Systems: Design, Testing, Identification and Validation, 1$^{st}$ edition, Springer, Singapore, 2019. https://doi.org/10.1007/978-981-13-2547-2 |
| [2] | A. Vacca, G. Franzoni, Hydraulic Fluid Power: Fundamentals, Applications, and Circuit Design, 1$^{st}$ edition, John Wiley & Sons, Hoboken, New Jersey, 2021. |
| [3] | N. Manring, Fluid Power Pumps and Motors: Analysis, Design, and Control, 1$^{st}$ edition, McGraw-Hill Education, New York, 2013. |
| [4] |
N. Nedic, V. Stojanovic, V. Djordjevic, Optimal control of hydraulically driven parallel robot platform based on firefly algorithm, Nonlinear Dyn., 82 (2015), 1457–1473. https://doi.org/10.1007/s11071-015-2252-5 doi: 10.1007/s11071-015-2252-5

|
| [5] |
V. Stojanovic, N. Nedic, D. Prsic, Lj. Dubonjic, V. Djordjevic, Application of cuckoo search algorithm to constrained control problem of a parallel robot platform, Int. J. Adv. Manuf. Technol., 87 (2016), 2497–2507. https://doi.org/10.1007/s00170-016-8627-z doi: 10.1007/s00170-016-8627-z
|
| [6] |
V. Filipovic, N. Nedic, V. Stojanovic, Robust identification of pneumatic servo actuators in the real situations, Forsch. Ingenieurwes., 75 (2011), 183–196. https://doi.org/10.1007/s10010-011-0144-5 doi: 10.1007/s10010-011-0144-5
|
| [7] | J. F. Blackburn, G. Reethof, J. L. Shearer, Fluid Power Control, MIT Press, Cambridge, Massachusetts, 1960. |
| [8] | M. Jelali, A. Kroll, Hydraulic Servo-Systems: Modelling, Identification and Control, 1$^{st}$ edition, Springer, London, 2003. https://doi.org/10.1007/978-1-4471-0099-7 |
| [9] | F. L. Lewis, D. Liu, Reinforcement Learning and Approximate Dynamic Programming for Feedback Control, 1$^{st}$ edition, John Wiley & Sons, Hoboken, New Jersey, 2013. |
| [10] | D. Bertsekas, Reinforcement Learning and Optimal Control, 1$^{st}$ edition, Athena Scientific, Belmont, Massachusetts, 2019. |
| [11] | D. Bertsekas, Dynamic Programming and Optimal Control: Volume I, 4$^{th}$ edition, Athena Scientific, Belmont, Massachusetts, 2012. |
| [12] | F. L. Lewis, D. Vrabie, V. L. Syrmos, Optimal Control, 3$^{rd}$ edition, John Wiley & Sons, Hoboken, New Jersey, 2012. |
| [13] | M. Tomás-Rodríguez, S. P. Banks, Linear, Time-Varying Approximations to Nonlinear Dynamical Systems: With Applications in Control and Optimization, 1$^{st}$ edition, Springer, London, 2010. https://doi.org/10.1007/978-1-84996-101-1 |
| [14] |
V. Stojanovic, D. Prsic, Robust identification for fault detection in the presence of non-Gaussian noises: application to hydraulic servo drives, Nonlinear Dyn., 100 (2020), 2299–2313. https://doi.org/10.1007/s11071-020-05616-4 doi: 10.1007/s11071-020-05616-4
|
| [15] |
M. Mynuddin, W. Gao, Distributed predictive cruise control based on reinforcement learning and validation on microscopic traffic simulation, IET Intel. Transport Syst., 14 (2020), 270–277. https://doi.org/10.1049/iet-its.2019.0404 doi: 10.1049/iet-its.2019.0404
|
| [16] | M. Mynuddin, W. Gao, Z. P. Jiang, Reinforcement learning for multi-agent systems with an application to distributed predictive cruise control, in American Control Conference (ACC), (2020), 315–320. https://doi.org/10.23919/ACC45564.2020.9147968 |
| [17] |
M. Davari, W. Gao, Z.P. Jiang, F. L. Lewis, An optimal primary frequency control based on adaptive dynamic programming for islanded modernized microgrids, IEEE Trans. Autom. Sci. Eng., 18 (2020), 1109–1121. https://doi.org/10.1109/TASE.2020.2996160 doi: 10.1109/TASE.2020.2996160
|
| [18] |
A. van de Walle, F. Naets, W. Desmet, Virtual microphone sensing through vibro-acoustic modelling and Kalman filtering, Mech. Syst. Signal Process., 104 (2018), 120–133. https://doi.org/10.1016/j.ymssp.2017.08.032 doi: 10.1016/j.ymssp.2017.08.032
|
| [19] |
K. Maes, A. Iliopoulos, W. Weijtjens, C. Devriendt, G. Lombaert, Dynamic strain estimation for fatigue assessment of an offshore monopile wind turbine using filtering and modal expansion algorithms, Mech. Syst. Signal Process., 76 (2016), 592–611. https://doi.org/10.1016/j.ymssp.2016.01.004 doi: 10.1016/j.ymssp.2016.01.004
|
| [20] |
Y. H. Chang, Q. Hu, C. J. Tomlin, Secure estimation based Kalman filter for cyber-physical systems against sensor attacks, Automatica, 95 (2018), 399–412. https://doi.org/10.1016/j.automatica.2018.06.010 doi: 10.1016/j.automatica.2018.06.010
|
| [21] |
A. Cavallo, G. De Maria, C. Natale, S. Pirozzi, Slipping detection and avoidance based on Kalman filter, Mechatronics, 24 (2014), 489–499. https://doi.org/10.1016/j.mechatronics.2014.05.006 doi: 10.1016/j.mechatronics.2014.05.006
|
| [22] |
W. Gao, M. Huang, Z.P. Jiang, T. Chai, Sampled-data-based adaptive optimal output-feedback control of a 2-degree-of-freedom helicopter, IET Control Theory Appl., 10 (2016), 1440–1447. https://doi.org/10.1049/iet-cta.2015.0977 doi: 10.1049/iet-cta.2015.0977
|
| [23] |
J. J. Murray, C. J. Cox, G. G. Lendaris, R. Saeks, Adaptive dynamic programming, IEEE Trans. Syst. Man Cybern. Part C Appl. Rev., 32 (2002), 140–153. https://doi.org/10.1109/TSMCC.2002.801727 doi: 10.1109/TSMCC.2002.801727
|
| [24] | P. J. Werbos, Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences, Ph.D thesis, Harvard University, 1974. |
| [25] |
W. Gao, Z. P. Jiang, Learning-based adaptive optimal tracking control of strict-feedback nonlinear systems, IEEE Trans. Neural Networks Learn. Syst., 29 (2017), 2614–2624. https://doi.org/10.1109/TNNLS.2017.2761718 doi: 10.1109/TNNLS.2017.2761718
|
| [26] |
T. Bian, Z.P. Jiang, Value iteration and adaptive dynamic programming for data-driven adaptive optimal control design, Automatica, 71 (2016), 348–360. https://doi.org/10.1016/j.automatica.2016.05.003 doi: 10.1016/j.automatica.2016.05.003
|
| [27] |
M. Roozegar, M. J. Mahjoob, M. Jahromi, Optimal motion planning and control of a nonholonomic spherical robot using dynamic programming approach: simulation and experimental results, Mechatronics, 39 (2016), 174–184. https://doi.org/10.1016/j.mechatronics.2016.05.002 doi: 10.1016/j.mechatronics.2016.05.002
|
| [28] | J. L. Sun, C. S. Liu, An overview on the adaptive dynamic programming based missile guidance law, Acta Autom. Sin., 43 (2017), 1101–1113. |
| [29] |
Q. Hu, Robust adaptive sliding mode attitude maneuvering and vibration damping of three-axis-stabilized flexible spacecraft with actuator saturation limits, Nonlinear Dyn., 55 (2009), 301–321. https://doi.org/10.1007/s11071-008-9363-1 doi: 10.1007/s11071-008-9363-1
|
| [30] |
W. Gao, Y. Jiang, Z. P. Jiang, T. Chai, Output-feedback adaptive optimal control of interconnected systems based on robust adaptive dynamic programming, Automatica, 72 (2016), 37–45. https://doi.org/10.1016/j.automatica.2016.05.008 doi: 10.1016/j.automatica.2016.05.008
|
| [31] | K. J. Åström, Event based control, in Analysis and Design of Nonlinear Control Systems (eds. A. Astolfi, L. Marconi), Springer, Berlin, Heidelberg, (2007), 127–147. https://doi.org/10.1007/978-3-540-74358-3 |
| [32] |
W. P. M. H. Heemels, M. C. F. Donkers, A. R. Teel, Periodic event-triggered control for linear systems, IEEE Trans. Autom. Control, 58 (2012), 847–861. https://doi.org/10.1109/TAC.2012.2220443 doi: 10.1109/TAC.2012.2220443
|
| [33] |
B. Jiang, H. R. Karimi, Y. Kao, C. Gao, Takagi-Sugeno model based event-triggered fuzzy sliding-mode control of networked control systems with semi-Markovian switchings, IEEE Trans. Fuzzy Syst., 28 (2019), 673–683. https://doi.org/10.1109/TFUZZ.2019.2914005 doi: 10.1109/TFUZZ.2019.2914005
|
| [34] |
T. Liu, Z. P. Jiang, A small-gain approach to robust event-triggered control of nonlinear systems, IEEE Trans. Autom. Control, 60 (2015), 2072–2085. https://doi.org/10.1109/TAC.2015.2396645 doi: 10.1109/TAC.2015.2396645
|
| [35] |
Y. S. Ma, W. W Che, C. Deng, Z. G. Wu, Observer-based event-triggered containment control for MASs under DoS attacks, IEEE Trans. Cybern., 52 (2021), 13156–13167. https://doi.org/10.1109/TCYB.2021.3104178 doi: 10.1109/TCYB.2021.3104178
|
| [36] |
X. Wang, H. R. Karimi, M. Shen, D. Liu, L. W. Li, J. Shi, Neural network-based event-triggered data-driven control of disturbed nonlinear systems with quantized input, Neural Networks, 156 (2022), 152–159. https://doi.org/10.1016/j.neunet.2022.09.021 doi: 10.1016/j.neunet.2022.09.021
|
| [37] |
M. Shen, Y. Gu, J. H. Park, Y. Yi, W. W. Che, Composite control of linear systems with event-triggered inputs and outputs, IEEE Trans. Circuits Syst. II Express Briefs, 69 (2021), 1154–1158. https://doi.org/10.1109/TCSII.2021.3098820 doi: 10.1109/TCSII.2021.3098820
|
| [38] | X. Wang, M. Shen, J. H. Park, Event-triggered control of uncertain nonlinear discrete-time systems with extended state observer, preprint. https://doi.org/10.21203/rs.3.rs-644060/v1 |
| [39] |
A. Sahoo, H. Xu, S. Jagannathan, Neural network-based event-triggered state feedback control of nonlinear continuous-time systems, IEEE Trans. Neural Networks Learn. Syst., 27 (2015), 497–509. https://doi.org/10.1109/TNNLS.2015.2416259 doi: 10.1109/TNNLS.2015.2416259
|
| [40] | L. Ljung, System Identification: Theory for the User, 2$^{nd}$ edition, Prentice-Hall, Upper Saddle River, New Jersey, 1999. |
| [41] | R. Pintelon, J. Schoukens, System Identification: A Frequency Domain Approach, 1$^{st}$ edition, John Wiley & Sons, Hoboken, New Jersey, 2012. |
| [42] |
C. R. Rojas, J. C. Aguero, J. S. Welsh, G. C. Goodwin, A. Feuer, Robustness in experiment design, IEEE Trans. Autom. Control, 57 (2011), 860–874. https://doi.org/10.1109/TAC.2011.2166294 doi: 10.1109/TAC.2011.2166294
|
| [43] |
A. Al-Tamimi, F. L. Lewis, M. Abu-Khalaf, Model-free Q-learning designs for linear discrete-time zero-sum games with application to H-infinity control, Automatica, 43 (2007), 473–481. https://doi.org/10.1016/j.automatica.2006.09.019 doi: 10.1016/j.automatica.2006.09.019
|
| [44] |
F. L. Lewis, K. G. Vamvoudakis, Reinforcement learning for partially observable dynamic processes: Adaptive dynamic programming using measured output data, IEEE Trans. Syst. Man Cybern. Part B Cybern., 41 (2010), 14–25. https://doi.org/10.1109/TSMCB.2010.2043839 doi: 10.1109/TSMCB.2010.2043839
|
| [45] | T. Chen, B. A. Francis, Optimal Sampled-Data Control Systems, 1$^{st}$ edition, Springer, London, 1995. https://doi.org/10.1007/978-1-4471-3037-6 |
| [46] |
G. Hewer, An iterative technique for the computation of the steady state gains for the discrete optimal regulator, IEEE Trans. Autom. Control, 16 (1971), 382–384. https://doi.org/10.1109/TAC.1971.1099755 doi: 10.1109/TAC.1971.1099755
|
| [47] | W. Gao, Y. Jiang, Z. P. Jiang, T. Chai, Adaptive and optimal output feedback control of linear systems: An adaptive dynamic programming approach, in Proceeding of the 11th World Congress on Intelligent Control and Automation, (2014), 2085–2090. https://doi.org/10.1109/WCICA.2014.7053043 |
| [48] | W. Aangenent, D. Kostic, B. de Jager, R. van de Molengraft, M. Steinbuch, Data-based optimal control, in Proceedings of the 2005, American Control Conference, (2005), 1460–1465. https://doi.org/10.1109/ACC.2005.1470171 |
| [49] | K. J. Åström, B. Wittenmark, Adaptive Control, 2$^{nd}$ edition, Dover Publication Inc, Mineola, New York, 2008. |
| [50] | P. A. Ioannou, J. Sun, Robust Adaptive Control, 2$^{nd}$ edition, Dover Publication Inc, Mineola, New York, 2012. |
| [51] |
K. G. Vamvoudakis, F. L. Lewis, Multi-player non-zero-sum games: Online adaptive learning solution of coupled Hamilton–Jacobi equations, Automatica, 47 (2011), 1556–1569. https://doi.org/10.1016/j.automatica.2011.03.005 doi: 10.1016/j.automatica.2011.03.005
|
| [52] |
H. Xu, S. Jagannathan, F. L. Lewis, Stochastic optimal control of unknown linear networked control system in the presence of random delays and packet losses, Automatica, 48 (2012), 1017–1030. https://doi.org/10.1016/j.automatica.2012.03.007 doi: 10.1016/j.automatica.2012.03.007
|










Figures(11) / Tables(1)

Vladimir Djordjevic, Hongfeng Tao, Xiaona Song, Shuping He, Weinan Gao, Vladimir Stojanovic. Data-driven control of hydraulic servo actuator: An event-triggered adaptive dynamic programming approach[J]. Mathematical Biosciences and Engineering, 2023, 20(5): 8561-8582. doi: 10.3934/mbe.2023376







 DownLoad:
DownLoad: