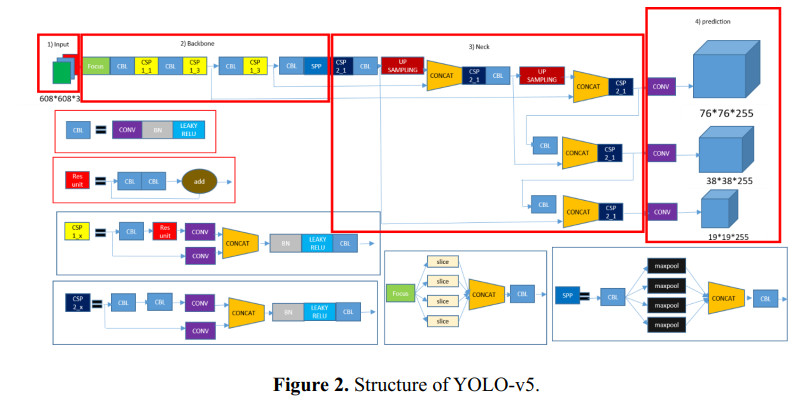
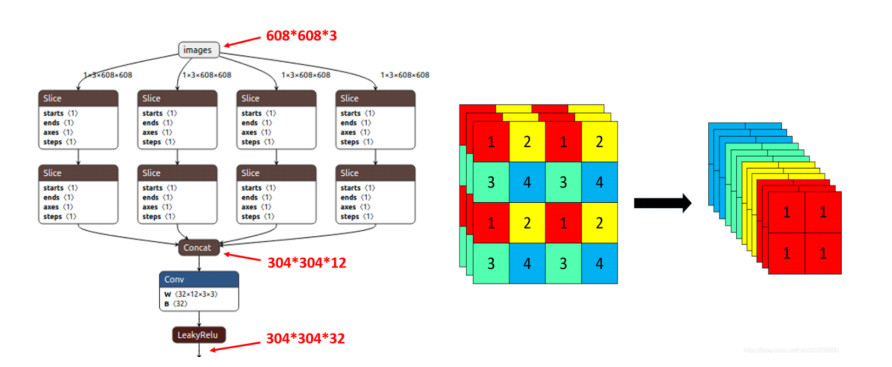
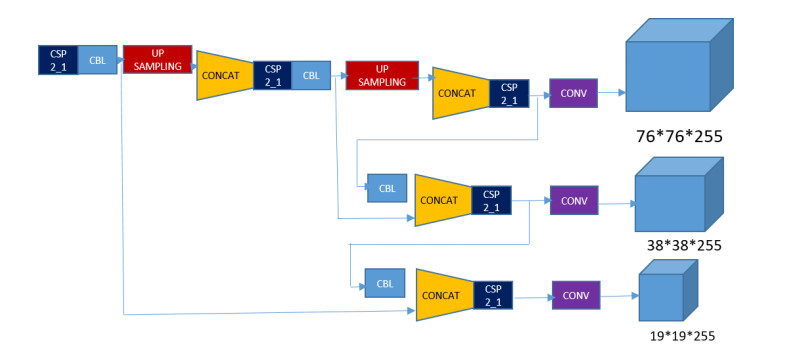
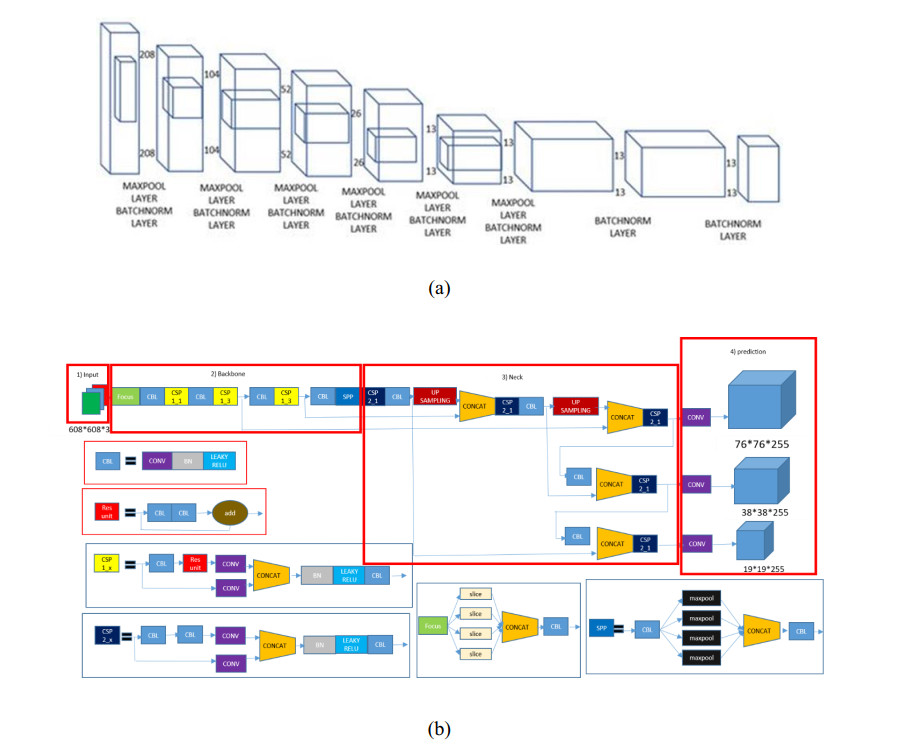
In this paper, a new model known as YOLO-v5 is initiated to detect defects in PCB. In the past many models and different approaches have been implemented in the quality inspection for detection of defect in PCBs. This algorithm is specifically selected due to its efficiency, accuracy and speed. It is well known that the traditional YOLO models (YOLO, YOLO-v2, YOLO-v3, YOLO-v4 and Tiny-YOLO-v2) are the state-of-the-art in artificial intelligence industry. In electronics industry, the PCB is the core and the most basic component of any electronic product. PCB is almost used in each and every electronic product that we use in our daily life not only for commercial purposes, but also used in sensitive applications such defense and space exploration. These PCB should be inspected and quality checked to detect any kind of defects during the manufacturing process. Most of the electronic industries are focused on the quality of their product, a small error during manufacture or quality inspection of the electronic products such as PCB leads to a catastrophic end. Therefore, there is a huge revolution going on in the manufacturing industry where the object detection method like YOLO-v5 is a game changer for many industries such as electronic industries.
Citation: Venkat Anil Adibhatla, Huan-Chuang Chih, Chi-Chang Hsu, Joseph Cheng, Maysam F. Abbod, Jiann-Shing Shieh. Applying deep learning to defect detection in printed circuit boards via a newest model of you-only-look-once[J]. Mathematical Biosciences and Engineering, 2021, 18(4): 4411-4428. doi: 10.3934/mbe.2021223
In this paper, a new model known as YOLO-v5 is initiated to detect defects in PCB. In the past many models and different approaches have been implemented in the quality inspection for detection of defect in PCBs. This algorithm is specifically selected due to its efficiency, accuracy and speed. It is well known that the traditional YOLO models (YOLO, YOLO-v2, YOLO-v3, YOLO-v4 and Tiny-YOLO-v2) are the state-of-the-art in artificial intelligence industry. In electronics industry, the PCB is the core and the most basic component of any electronic product. PCB is almost used in each and every electronic product that we use in our daily life not only for commercial purposes, but also used in sensitive applications such defense and space exploration. These PCB should be inspected and quality checked to detect any kind of defects during the manufacturing process. Most of the electronic industries are focused on the quality of their product, a small error during manufacture or quality inspection of the electronic products such as PCB leads to a catastrophic end. Therefore, there is a huge revolution going on in the manufacturing industry where the object detection method like YOLO-v5 is a game changer for many industries such as electronic industries.

| [1] | H. Suzuki, Junkosha Co Ltd., Printed Circuit Board, US 4640866, March 16, 1987. |
| [2] | H. Matsubara, M. Itai, K. Kimura, NGK Spark Plug Co Ltd., Printed Circuit Board, US 6573458, September 12, 2003. |
| [3] | J. A. Magera, G. J. Dunn, The Printed Circuit Designer's Guide to Flex and Rigid-Flex Fundamentals, Motorola Solutions Inc., Printed Circuit Board, US 7459202, August 21, 2008. |
| [4] | H. S. Cho, J. G. Yoo, J. S. Kim, S. H. Kim, Official Gazette of the United states patent and trademark, Samsung Electro Mechanics Co Ltd., Printed Circuit Board, US 8159824, 2012. |
| [5] | A. P. S. Chauhan, S. C. Bhardwaj, Detection of bare PCB defects by image subtraction method using machine vision, in Proceedings of the World Congress on Engineering, 2 (2011), 6-8. |
| [6] | N. K. Khalid, Z. Ibrahim, An Image Processing Approach towards Classification of Defects on Printed Circuit Board, PhD thesis, University Technology Malaysia, Johor, Malaysia, 2007. |
| [7] |
Y. Bengio, A. Courville, P. Vincent, Representation learning: A review and new perspectives, IEEE Trans. Pattern Anal. Mach. Intell., 35 (2013), 1798-828. doi: 10.1109/TPAMI.2013.50

|
| [8] | P. S. Malge, PCB defect detection, classification and localization using mathematical morphology and image processing tools, Int. J. Comput. Appl., 87 (2014), 40-45. |
| [9] | Y. Takada, T. Shiina, H. Usami, Y. Iwahori, Defect detection and classification of electronic circuit boards using keypoint extraction and CNN features, in The Ninth International Conferences on Pervasive Patterns and Applications Defect, 100 (2017), 113-116. |
| [10] | D. B. Anitha, R. Mahesh, A survey on defect detection in bare PCB and assembled PCB using image processing techniques, in 2017 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), (2017), 39-43. |
| [11] |
A. J. Crispin, V. Rankov, Automated inspection of PCB components using a genetic algorithm template-matching approach, Int. J. Adv. Manuf. Technol., 35 (2007), 293-300. doi: 10.1007/s00170-006-0730-0
|
| [12] | F. Raihan, W. Ce, PCB defect detection USING OPENCV with image subtraction method, in 2017 International Conference on Information Management and Technology (ICIMTech), (2017), 204-209. |
| [13] | I. B. Basyigit, A. Genc, H. Dogan, F. A. Senel, S. Helhel, Deep learning for both broadband prediction of the radiated emission from heatsinks and heatsink optimization, Eng. Sci. Technol. Int. J., 24 (2021), 706-714. |
| [14] | S. Metlek, K. Kayaalp, I. B. Basyigit, A. Genc, H. Doğan, The dielectric properties prediction of the vegetation depending on the moisture content using the deep neural network model, Int. J. RF Microwave Comput.-Aided Eng., 31 (2020), e22496. |
| [15] | H. Hosseini, B. Xiao, M. Jaiswal, R. Poovendran, On the limitation of convolutional neural networks in recognizing negative images, in 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), (2017), 352-358. |
| [16] |
X. Tao, Z. Wang, Z. Zhang, D. Zhang, D. Xu, X. Gong, et al., Wire defect recognition of spring-wire socket using multitask convolutional neural networks, IEEE Trans. Compon. Package. Manuf. Technol., 8 (2018), 689-698. doi: 10.1109/TCPMT.2018.2794540
|
| [17] | J. R. R. Uijlings, K. E. A. Van De Sande, T. Gevers, A. W. M. Smeulders, Selective search for object recognition, Int. J. Comput. Vision, 104 (2012), 154-171. |
| [18] | R. Girshick, J. Donahue, T. Darrell, J. Malik, Rich feature hierarchies for accurate object detection and semantic segmentation, in Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, (2014), 580-587. |
| [19] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, preprint, arXiv: 1512.03385. |
| [20] | K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, preprint, arXiv: 1409.1556. |
| [21] | C. Szegedy, S. Ioffe, V. Vanhoucke, Inception-v4, inception-resnet and the impact of residual connections on learning, preprint, arXiv: 1602.07261. |
| [22] | C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, et al., Going deeper with convolutions, preprint, arXiv: 1409.4842. |
| [23] | N. Suda, V. Chandra, G. Dasika, A. Mohanty, Y. Ma, S. Vrudhula, et al., Throughput-optimized OpenCL-based FPGA accelerator for large-scale convolutional neural networks, in Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, (2016), 16-25. |
| [24] | J. Zhang, J. Li, Improving the performance of OpenCL-based FPGA accelerator for convolutional neural network, in Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, (2017), 25-34. |
| [25] | D. Wang, J. An, K. Xu, PipeCNN: An OpenCL-based FPGA accelerator for large-scale convolution neuron networks, preprint, arXiv: 1611.02450. |
| [26] | J. Cong, B. Xiao, Minimizing computation in convolutional neural networks, in International conference on artificial neural networks, Springer, Cham, (2014), 281-290. |
| [27] |
V. A. Adibhatla, H. C. Chih, C. C. Hsu, J. Cheng, M. F. Abbod, J. S. Shieh, Defect detection in printed circuit boards using you-only-look-once convolutional neural networks, Electronics, 9 (2020), 1547. doi: 10.3390/electronics9091547
|
| [28] | M. Pritt, G. Chern, Satellite image classification with deep learning, in 2017 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), (2017), 1-7. |
| [29] |
X. S. Zhang, R. J. Roy, E. W. Jensen, EEG complexity as a measure of depth of anesthesia for patients, IEEE Trans. Biomed. Eng., 48 (2001), 1424-1433. doi: 10.1109/10.966601
|
| [30] |
V. Lalitha, C. Eswaran, Automated detection of anesthetic depth levels using chaotic features with artificial neural networks, J. Med. Syst., 31 (2007), 445-452. doi: 10.1007/s10916-007-9083-y
|
| [31] | M. Peker, B. Sen, H. Gürüler, Rapid automated classification of anesthetic depth levels using GPU based parallelization of neural networks, J. Med. Syst., 39 (2015), 1-11. |
| [32] |
P. L. Callet, C. Viard-Gaudin, D. Barba, A convolutional neural network approach for objective video quality assessment, IEEE Trans. Neural Networks, 17 (2006), 1316-1327. doi: 10.1109/TNN.2006.879766
|
| [33] | D. C. Cireşan, U. Meier, L. M. Gambardella, J. Schmidhuber, Convolutional neural network committees for handwritten character classification, in Proceedings of the 2011 International Conference on Document Analysis and Recognition, (2011), 1135-1139. |
| [34] | N. Kalchbrenner, E. Grefenstette, P. Blunsom, A convolutional neural network for modelling sentences, preprint, arXiv: 1404.2188. |
| [35] | A. Devarakonda, M. Naumov, M. Garland, Adabatch: Adaptive batch sizes for training deep neural networks, preprint, arXiv: 1712.02029. |
| [36] | T. Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollár, Focal loss for dense object detection, in Proceedings of the IEEE international conference on computer vision, (2017), 2980-2988. |
| [37] |
L. Shao, F. Zhu, X. Li, Transfer learning for visual categorization: A survey, IEEE Trans. Neural Netw. Learn. Syst., 26 (2015), 1019-1034. doi: 10.1109/TNNLS.2014.2330900
|




Figures(9) / Tables(8)

Venkat Anil Adibhatla, Huan-Chuang Chih, Chi-Chang Hsu, Joseph Cheng, Maysam F. Abbod, Jiann-Shing Shieh. Applying deep learning to defect detection in printed circuit boards via a newest model of you-only-look-once[J]. Mathematical Biosciences and Engineering, 2021, 18(4): 4411-4428. doi: 10.3934/mbe.2021223







 DownLoad:
DownLoad: