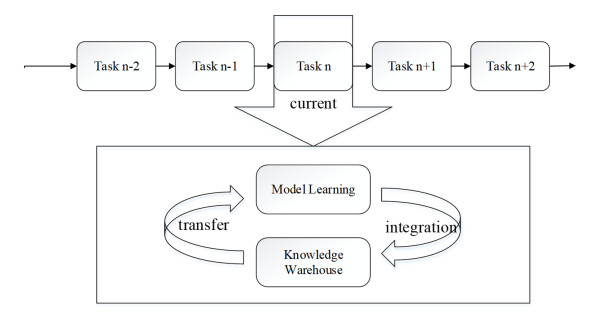
The study expects to solve the problems of insufficient labeling, high input dimension, and inconsistent task input distribution in traditional lifelong machine learning. A new deep learning model is proposed by combining feature representation with a deep learning algorithm. First, based on the theoretical basis of the deep learning model and feature extraction. The study analyzes several representative machine learning algorithms, and compares the performance of the optimized deep learning model with other algorithms in a practical application. By explaining the machine learning system, the study introduces two typical algorithms in machine learning, namely ELLA (Efficient lifelong learning algorithm) and HLLA (Hierarchical lifelong learning algorithm). Second, the flow of the genetic algorithm is described, and combined with mutual information feature extraction in a machine algorithm, to form a composite algorithm HLLA (Hierarchical lifelong learning algorithm). Finally, the deep learning model is optimized and a deep learning model based on the HLLA algorithm is constructed. When K = 1200, the classification error rate reaches 0.63%, which reflects the excellent performance of the unsupervised database algorithm based on this model. Adding the feature model to the updating iteration process of lifelong learning deepens the knowledge base ability of lifelong machine learning, which is of great value to reduce the number of labels required for subsequent model learning and improve the efficiency of lifelong learning.
Citation: Yufeng Qian. Exploration of machine algorithms based on deep learning model and feature extraction[J]. Mathematical Biosciences and Engineering, 2021, 18(6): 7602-7618. doi: 10.3934/mbe.2021376
The study expects to solve the problems of insufficient labeling, high input dimension, and inconsistent task input distribution in traditional lifelong machine learning. A new deep learning model is proposed by combining feature representation with a deep learning algorithm. First, based on the theoretical basis of the deep learning model and feature extraction. The study analyzes several representative machine learning algorithms, and compares the performance of the optimized deep learning model with other algorithms in a practical application. By explaining the machine learning system, the study introduces two typical algorithms in machine learning, namely ELLA (Efficient lifelong learning algorithm) and HLLA (Hierarchical lifelong learning algorithm). Second, the flow of the genetic algorithm is described, and combined with mutual information feature extraction in a machine algorithm, to form a composite algorithm HLLA (Hierarchical lifelong learning algorithm). Finally, the deep learning model is optimized and a deep learning model based on the HLLA algorithm is constructed. When K = 1200, the classification error rate reaches 0.63%, which reflects the excellent performance of the unsupervised database algorithm based on this model. Adding the feature model to the updating iteration process of lifelong learning deepens the knowledge base ability of lifelong machine learning, which is of great value to reduce the number of labels required for subsequent model learning and improve the efficiency of lifelong learning.

| [1] |
A. Esteva, K. Chou, S. Yeung, N. Naik, A. Madani, A. Mottaghi, et al., Deep learning-enabled medical computer vision, NPJ Digital Med., 4 (2021), 1-9. doi: 10.1038/s41746-020-00373-5

|
| [2] |
D.T. Nguyen, M. B. Lee, T. D. Pham, G. Batchuluun, M. Arsalan, K. R. Park, Enhanced image-based endoscopic pathological site classification using an ensemble of deep learning models, Sensors, 20 (2020), 5982. doi: 10.3390/s20215982
|
| [3] |
T. Higaki, Y. Nakamura, J. Zhou, Z. Yu, T. Nemoto, F. Tatsugami, et al., Deep learning reconstruction at CT: phantom study of the image characteristics, Acad. Radiol., 27 (2020), 82-87. doi: 10.1016/j.acra.2019.09.008
|
| [4] |
A. Hakim, Y. Mor, I. A. Toker, A. Levine, M. Neuhof, Y. Markovitz, et al., WorMachine: machine learning-based phenotypic analysis tool for worms, BMC Biol., 16(2018), 1-11. doi: 10.1186/s12915-017-0471-6
|
| [5] |
C. Wang, Z. Xiao, B. Wang, J. Wu, Identification of autism based on SVM-RFE and stacked sparse auto-encoder, IEEE Access, 7(2019), 118030-118036. doi: 10.1109/ACCESS.2019.2936639
|
| [6] |
A. N. Aicha, G. Englebienne, K. S. Schooten, M. Pijnappels, B. Krö se, Deep learning to predict falls in older adults based on daily-life trunk accelerometry, Sensors, 18 (2018), 1654. doi: 10.3390/s18051654
|
| [7] |
A. Fc, B. Ky, B. Jl, Deconvolutional neural network for image super-resolution, Neural Networks, 132 (2020), 394-404. doi: 10.1016/j.neunet.2020.09.017
|
| [8] | J. Sun, D. I. Liping, Z. Sun, et al. Estimation of GDP using deep learning with NPP-VIIRS imagery and land cover data at the county-level in CONUS, IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., 13 (2020), 1400-1415. |
| [9] |
M. A. Khan, I. Ashraf, M. Alhaisoni, R. Damaševičius, R. Scherer, A. Rehman, et al., Multimodal brain tumor classification using deep learning and robust feature selection: A machine learning application for radiologists, Diagnostics, 10 (2020), 565. doi: 10.3390/diagnostics10080565
|
| [10] |
F. P. An, Human action recognition algorithm based on adaptive initialization of deep learning model parameters and support vector machine, IEEE Access, 6 (2018), 59405-59421. doi: 10.1109/ACCESS.2018.2874022
|
| [11] | M. Heidarysafa, K. Kowsari, D.E. Brown, K. J. Meimandi, L. E. Barnes, An improvement of data classification using random multimodel deep learning (rmdl), Int. J. Mach. Learn. Cybern., 8 (2018), 298-310. |
| [12] |
S. Almabdy, L. Elrefaei, Deep convolutional neural network-based approaches for face recognition, Appl. Sci., 9 (2019), 4397. doi: 10.3390/app9204397
|
| [13] |
S. H. S. Basha, S. R. Dubey, V. Pulabaigari, S. Mukherjee, Impact of fully connected layers on performance of convolutional neural networks for image classification, Neurocomputing, 378 (2020), 112-119. doi: 10.1016/j.neucom.2019.10.008
|
| [14] | S. H. Wang, Y. D. Zhang, DenseNet-201-based deep neural network with composite learning factor and precomputation for multiple sclerosis classification, ACM Trans. Multimedia Comput., Commun., Appl. (TOMM), 60 (2020), 1-19. |
| [15] | S. S. Du, W. Hu, J. D. Lee, Algorithmic regularization in learning deep homogeneous models: Layers are automatically balanced, preprint, arXiv: 1806.00900. |
| [16] |
S. Duari, V. Bhatnagar, Complex network based supervised keyword extractor, Expert Syst. Appl., 140 (2020), 112876. doi: 10.1016/j.eswa.2019.112876
|
| [17] |
Y. Hua, X. Sui, S. Zhou, Q. Chen, G. Gu, H. Bai, et al., A novel method of global optimisation for wavefront shaping based on the differential evolution algorithm, Optics Commun., 481 (2021), 126541. doi: 10.1016/j.optcom.2020.126541
|
| [18] |
L. Kang, C. Wu, B. Wang, Principles, approaches and challenges of applying big data in safety psychology research, Front. Psychol., 10 (2019), 1596. doi: 10.3389/fpsyg.2019.01596
|
| [19] |
A. F. Fuentes, S. Yoon, J. Lee, D. S. Park, High-performance deep neural network-based tomato plant diseases and pests diagnosis system with refinement filter bank, Front. Plant Sci., 9 (2018), 1162. doi: 10.3389/fpls.2018.01162
|
| [20] | S. B. Dias, S. J. Hadjileontiadou, J. Diniz, L. J. Hadjileontiadi, DeepLMS: a deep learning predictive model for supporting online learning in the Covid-19 era, Sci. Rep., 10 (2020). |
| [21] | S. Hizlisoy, S. Yildirim, Z. Tufekci, Music emotion recognition using convolutional long short term memory deep neural networks, Eng. Sci. Technol., Int. J., 24 (2021), 760-767. |
| [22] |
V. G. V. Vydiswaran, Y.Y. Zhang, Y. S. Wang, H. Xu, Special issue of BMC medical informatics and decision making on health natural language processing, BMC Med. Inf. Decis. Making, 19 (2019), 76. doi: 10.1186/s12911-019-0777-0
|
| [23] |
K. Stuburi, M. Gaiduk, R. Seepold, A deep learning approach to detect sleep stages, Procedia Comput. Sci., 176 (2020), 2764-2772. doi: 10.1016/j.procs.2020.09.280
|
| [24] |
G. Yang, S. Yu, Synthesized fault diagnosis method reasoned from rough set-neural network and evidence theory, Concurrency Comput.: Pract. Exper., 31 (2019), e4944. doi: 10.1002/cpe.4944
|
| [25] | S. Hizlisoy, S. Yildirim, Z. Tufekci, Music emotion recognition using convolutional long short term memory deep neural networks, Eng. Sci. Technol., Int. J., 24 (2020), 760-767. |







Figures(8) / Tables(3)

Yufeng Qian. Exploration of machine algorithms based on deep learning model and feature extraction[J]. Mathematical Biosciences and Engineering, 2021, 18(6): 7602-7618. doi: 10.3934/mbe.2021376







 DownLoad:
DownLoad: