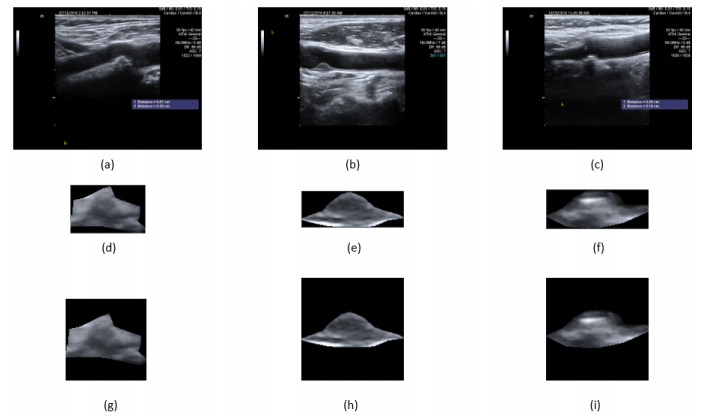
Carotid plaque classification from ultrasound images is crucial for predicting ischemic stroke risk. While deep learning has shown effectiveness, it heavily relies on substantial labeled datasets. Achieving high performance with limited labeled images is essential for clinical use. Self-supervised learning (SSL) offers a potential solution; however, the existing works mainly focus on constructing the SSL tasks, neglecting the use of multiple tasks for pretraining. To overcome these limitations, this study proposed a self-supervised fusion network (Fusion-SSL) for carotid plaque ultrasound image classification with limited labeled data. Fusion-SSL consists of two SSL tasks: classifying image block order (Ordering) and predicting image rotation angle (Rotating). A dual-branch residual neural network was developed to fuse feature presentations learned by the two tasks, which can extract richer visual boundary shape and contour information than a single task. In this experiment, 1270 carotid plaque ultrasound images were collected from 844 patients at Zhongnan Hospital (Wuhan, China). The results showed that Fusion-SSL outperforms single SSL methods across different percentages of labeled training data, ranging from 10 to 100%. Moreover, with only 40% labeled training data, Fusion-SSL achieved comparable results to a single SSL method (predicting image rotation angle) with 100% labeled data. These results indicate that Fusion-SSL could be beneficial for the classification of carotid plaques and the early warning of a stroke in clinical practice.
Citation: Yue Zhang, Haitao Gan, Furong Wang, Xinyao Cheng, Xiaoyan Wu, Jiaxuan Yan, Zhi Yang, Ran Zhou. A self-supervised fusion network for carotid plaque ultrasound image classification[J]. Mathematical Biosciences and Engineering, 2024, 21(2): 3110-3128. doi: 10.3934/mbe.2024138
Carotid plaque classification from ultrasound images is crucial for predicting ischemic stroke risk. While deep learning has shown effectiveness, it heavily relies on substantial labeled datasets. Achieving high performance with limited labeled images is essential for clinical use. Self-supervised learning (SSL) offers a potential solution; however, the existing works mainly focus on constructing the SSL tasks, neglecting the use of multiple tasks for pretraining. To overcome these limitations, this study proposed a self-supervised fusion network (Fusion-SSL) for carotid plaque ultrasound image classification with limited labeled data. Fusion-SSL consists of two SSL tasks: classifying image block order (Ordering) and predicting image rotation angle (Rotating). A dual-branch residual neural network was developed to fuse feature presentations learned by the two tasks, which can extract richer visual boundary shape and contour information than a single task. In this experiment, 1270 carotid plaque ultrasound images were collected from 844 patients at Zhongnan Hospital (Wuhan, China). The results showed that Fusion-SSL outperforms single SSL methods across different percentages of labeled training data, ranging from 10 to 100%. Moreover, with only 40% labeled training data, Fusion-SSL achieved comparable results to a single SSL method (predicting image rotation angle) with 100% labeled data. These results indicate that Fusion-SSL could be beneficial for the classification of carotid plaques and the early warning of a stroke in clinical practice.

| [1] |
P. J. Modrego, M. A. Pina, M. M. Fraj, N. Llorens, Type, causes, and prognosis of stroke recurrence in the province of teruel, spain. a 5-year analysis, Neurol. Sci., 21 (2000), 355–360. https://doi.org/10.1007/s100720070050 doi: 10.1007/s100720070050

|
| [2] |
V. L. Feigin, R. V. Krishnamurthi, P. Parmar, B. Norrving, G. A. Mensah, D. A. Bennett, et al., Update on the global burden of ischemic and hemorrhagic stroke in 1990–2013: the GBD 2013 study, Neuroepidemiology, 45 (2015), 161–176. https://doi.org/10.1159/000441085 doi: 10.1159/000441085
|
| [3] |
S. S. Ho, Current status of carotid ultrasound in atherosclerosis, Quant. Imaging Med. Surg., 6 (2016), 285–296. https://doi.org/10.21037/qims.2016.05.03 doi: 10.21037/qims.2016.05.03
|
| [4] |
K. Lekadir, A. Galimzianova, A. Betriu, M. D. M. Vila, L. Igual, D. L. Rubin, et al., A convolutional neural network for automatic characterization of plaque composition in carotid ultrasound, IEEE J. Biomed. Health Inf., 21 (2017), 48–55. https://doi.org/10.1109/JBHI.2016.2631401 doi: 10.1109/JBHI.2016.2631401
|
| [5] |
J. Zhan, J. Wang, Z. Ben, H. Ruan, S. Chen, Recognition of angiographic atherosclerotic plaque development based on deep learning, IEEE Access, 7 (2019), 170807–170819. https://doi.org/10.1109/ACCESS.2019.2954626 doi: 10.1109/ACCESS.2019.2954626
|
| [6] | W. Ma, X. Cheng, X. Xu, F. Wang, R. Zhou, A. Fenster, et al., Multilevel strip pooling-based convolutional neural network for the classification of carotid plaque echogenicity, Comput. Math. Methods Med., 2021 (2021). https://doi.org/10.1155/2021/3425893 |
| [7] | W. Ma, R. Zhou, Y. Zhao, Y. Xia, A. Fenster, M. Ding, Plaque recognition of carotid ultrasound images based on deep residual network, in 2019 IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (ITAIC), (2019), 931–934. https://doi.org/10.1109/ITAIC.2019.8785825 |
| [8] |
M. Zreik, R. W. van Hamersvelt, J. M. Wolterink, T. Leiner, M. A. Viergever, I. Isgum, A recurrent CNN for automatic detection and classification of coronary artery plaque and stenosis in coronary ct angiography, IEEE Trans. Med. Imaging, 38 (2019), 1588–1598. https://doi.org/10.1109/TMI.2018.2883807 doi: 10.1109/TMI.2018.2883807
|
| [9] |
Q. Huang, H. Tian, L. Jia, Z. Li, Z. Zhou, A review of deep learning segmentation methods for carotid artery ultrasound images, Neurocomputing, 545 (2023), 126298. https://doi.org/10.1016/j.neucom.2023.126298 doi: 10.1016/j.neucom.2023.126298
|
| [10] | Q. Huang, L. Jia, G. Ren, X. Wang, C. Liu, Extraction of vascular wall in carotid ultrasound via a novel boundary-delineation network, Eng. Appl. Artif. Intell., 121 (2023). https://doi.org/10.1016/j.engappai.2023.106069 |
| [11] |
Q. Huang, L. Zhao, G. Ren, X. Wang, C. Liu, W. Wang, NAG-Net: Nested attention-guided learning for segmentation of carotid lumen-intima interface and media-adventitia interface, Comput. Biol. Med., 156 (2023), 1588–1598. https://doi.org/10.1016/j.compbiomed.2023.106718 doi: 10.1016/j.compbiomed.2023.106718
|
| [12] | L. Cai, E. Zhao, H. Niu, Y. Liu, T. Zhang, D. Liu, et al., A machine learning approach to predict cerebral perfusion status based on internal carotid artery blood flow, Comput. Biol. Med., 164 (2023). https://doi.org/10.1016/j.compbiomed.2023.107264 |
| [13] | S. Gidaris, A. Bursuc, N. Komodakis, P. Perez, M. Cord, Boosting few-shot visual learning with self-supervision, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2019), 8058–8067. https://doi.org/10.1109/ICCV.2019.00815 |
| [14] | W. Bai, C. Chen, G. Tarroni, J. Duan, F. Guitton, S. E. Petersen, et al., Self-supervised learning for cardiac MR image segmentation by anatomical position prediction, in Medical Image Computing and Computer Assisted Intervention–MICCAI 2019, 11765 (2019), 541–549. https://doi.org/10.1007/978-3-030-32245-8_60 |
| [15] |
N. A. Koohbanani, B. Unnikrishnan, S. A. Khurram, P. Krishnaswamy, N. Rajpoot, Self-path: self-supervision for classification of pathology images with limited annotations, IEEE Trans. Med. Imaging, 40 (2021), 845–2856. https://doi.org/10.1109/TMI.2021.3056023 doi: 10.1109/TMI.2021.3056023
|
| [16] | C. Abbet, I. Zlobec, B. Bozorgtabar, J. P. Thiran, Divide-and-rule: self-supervised learning for survival analysis in colorectal cancer, in Medical Image Computing and Computer Assisted Intervention–MICCAI 2020, 12265 (2020), 480–489. https://doi.org/10.1007/978-3-030-59722-1_46 |
| [17] | A. S. Hervella, J. Rouco, J. Novo, M. Ortega, Self-supervised multimodal reconstruction of retinal images over paired datasets, Expert Syst. Appl., 161 (2020). https://doi.org/10.1016/j.eswa.2020.113674 |
| [18] | L. Chen, P. Bentley, K. Mori, K. Misawa, M. Fujiwara, D. Rueckert, Self-supervised learning for medical image analysis using image context restoration, Med. Image Anal., 58 (2019). https://doi.org/10.1016/j.media.2019.101539 |
| [19] | J. Yan, H. Gan, X. Xu, Z. Yang, Z. Ye, SSCPC-Net: Classification of carotid plaques in ultrasound images using a self-supervised convolutional neural network, in 2022 China Automation Congress (CAC), (2022), 4504–4509. https://doi.org/10.1109/CAC57257.2022.10055587 |
| [20] | S. Gidaris, P. Singh, N. Komodakis, Unsupervised representation learning by predicting image rotations, preprint, arXiv: 1803.07728. https://doi.org/10.48550/arXiv.1803.07728 |
| [21] |
E. Picano, M. Paterni, Ultrasound tissue characterization of vulnerable atherosclerotic plaque, Int. J. Mol. Sci., 16 (2015), 10121–10133. https://doi.org/10.3390/ijms160510121 doi: 10.3390/ijms160510121
|
| [22] | X. Li, W. Wang, X. Hu, J. Yang, Selective kernel networks, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2019), 510–519. https://doi.org/10.1109/CVPR.2019.00060 |
| [23] | M. Grandini, E. Bagli, G. Visani, Metrics for multi-class classification: an overview, preprint, arXiv: 2008.05756. https://doi.org/10.48550/arXiv.2008.05756 |
| [24] | N. Ma, X. Zhang, H. Zheng, J. Sun, Shufflenet v2: practical guidelines for efficient CNN architecture design, in Proceedings of the European Conference on Computer Vision (ECCV), 11218 (2018), 116–131. https://doi.org/10.48550/arXiv.1807.11164 |
| [25] | A. Howard, M. Sandler, G. Chu, L. Chen, B. Chen, M. Tan, et al., Searching for mobilenetv3, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2019), 1314–1324. https://doi.org/10.48550/arXiv.1905.02244 |
| [26] | M. Tan, Q. Le, Efficientnet: rethinking model scaling for convolutional neural networks, in International Conference on Machine Learning, 97 (2019), 6105–6114. https://doi.org/10.48550/arXiv.1905.11946 |
| [27] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2016), 770–778. https://doi.org/10.48550/arXiv.1512.03385 |
| [28] | X. Chen, K. He, Exploring simple siamese representation learning, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2021), 15750–15758. https://doi.org/10.48550/arXiv.2011.10566 |








Figures(9) / Tables(4)

Yue Zhang, Haitao Gan, Furong Wang, Xinyao Cheng, Xiaoyan Wu, Jiaxuan Yan, Zhi Yang, Ran Zhou. A self-supervised fusion network for carotid plaque ultrasound image classification[J]. Mathematical Biosciences and Engineering, 2024, 21(2): 3110-3128. doi: 10.3934/mbe.2024138







 DownLoad:
DownLoad: