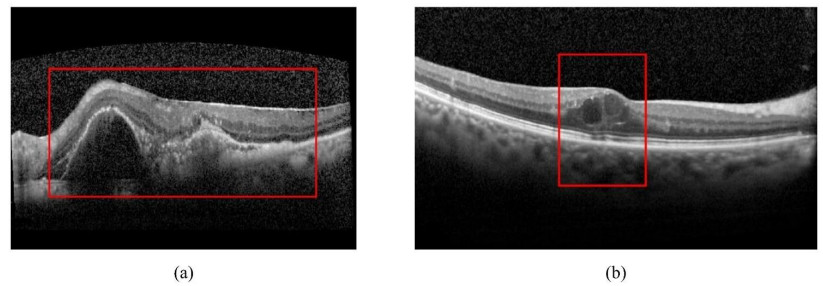
Anti-vascular endothelial growth factor (Anti-VEGF) therapy has become a standard way for choroidal neovascularization (CNV) and cystoid macular edema (CME) treatment. However, anti-VEGF injection is a long-term therapy with expensive cost and may be not effective for some patients. Therefore, predicting the effectiveness of anti-VEGF injection before the therapy is necessary. In this study, a new optical coherence tomography (OCT) images based self-supervised learning (OCT-SSL) model for predicting the effectiveness of anti-VEGF injection is developed. In OCT-SSL, we pre-train a deep encoder-decoder network through self-supervised learning to learn the general features using a public OCT image dataset. Then, model fine-tuning is performed on our own OCT dataset to learn the discriminative features to predict the effectiveness of anti-VEGF. Finally, classifier trained by the features from fine-tuned encoder as a feature extractor is built to predict the response. Experimental results on our private OCT dataset demonstrated that the proposed OCT-SSL can achieve an average accuracy, area under the curve (AUC), sensitivity and specificity of 0.93, 0.98, 0.94 and 0.91, respectively. Meanwhile, it is found that not only the lesion region but also the normal region in OCT image is related to the effectiveness of anti-VEGF.
Citation: Dehua Feng, Xi Chen, Xiaoyu Wang, Xuanqin Mou, Ling Bai, Shu Zhang, Zhiguo Zhou. Predicting effectiveness of anti-VEGF injection through self-supervised learning in OCT images[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 2439-2458. doi: 10.3934/mbe.2023114
Anti-vascular endothelial growth factor (Anti-VEGF) therapy has become a standard way for choroidal neovascularization (CNV) and cystoid macular edema (CME) treatment. However, anti-VEGF injection is a long-term therapy with expensive cost and may be not effective for some patients. Therefore, predicting the effectiveness of anti-VEGF injection before the therapy is necessary. In this study, a new optical coherence tomography (OCT) images based self-supervised learning (OCT-SSL) model for predicting the effectiveness of anti-VEGF injection is developed. In OCT-SSL, we pre-train a deep encoder-decoder network through self-supervised learning to learn the general features using a public OCT image dataset. Then, model fine-tuning is performed on our own OCT dataset to learn the discriminative features to predict the effectiveness of anti-VEGF. Finally, classifier trained by the features from fine-tuned encoder as a feature extractor is built to predict the response. Experimental results on our private OCT dataset demonstrated that the proposed OCT-SSL can achieve an average accuracy, area under the curve (AUC), sensitivity and specificity of 0.93, 0.98, 0.94 and 0.91, respectively. Meanwhile, it is found that not only the lesion region but also the normal region in OCT image is related to the effectiveness of anti-VEGF.

| [1] |
W. L. Wong, X. Su, X. Li, C. M. G. Cheung, R. Klein, C. Y. Cheng, et al., Global prevalence of age-related macular degeneration and disease burden projection for 2020 and 2040: A systematic review and meta-analysis, Lancet Glob. Health, 2 (2014), e106–e116, https://doi.org/10.1016/S2214-109X(13)70145-1. doi: 10.1016/S2214-109X(13)70145-1

|
| [2] |
H. E. Grossniklaus, W. Green, Choroidal neovascularization, Am. J. Ophthalmol., 137 (2004), 496–503. https://doi.org/10.1016/j.ajo.2003.09.042 doi: 10.1016/j.ajo.2003.09.042
|
| [3] |
M. R. Hee, C. R. Baumal, C. A. Puliafito, J. S. Duker, E. Reichel, J. R. Wilkins, et al., Optical coherence tomography of age-related macular degeneration and choroidal neovascularization, Ophthalmology, 103 (1996), 1260–1270. https://doi.org/10.1016/S0161-6420(96)30512-5 doi: 10.1016/S0161-6420(96)30512-5
|
| [4] |
T. D. Ting, M. Oh, T. A. Cox, C. H. Meyer, C. A. Toth, Decreased visual acuity associated with cystoid macular mdema in meovascular age-related macular degeneration, Arch. Ophthalmol., 120 (2002), 731–737. https://doi.org/10.1001/archopht.120.6.731 doi: 10.1001/archopht.120.6.731
|
| [5] |
N. Shah, M. G. Maguire, D. F. Martin, J. Shaffer, G. S. Ying, J. E. Grunwald, et al., Angiographic cystoid macular edema and outcomes in the comparison of age-related macular degeneration treatments trials, Ophthalmology, 123 (2016), 858–864. https://doi.org/10.1016/j.ophtha.2015.11.030 doi: 10.1016/j.ophtha.2015.11.030
|
| [6] | A. Loewenstein, D. Zur, Postsurgical cystoid macular edema, in Macular Edema, (2010), 148–159. https://doi.org/10.1159/000320078 |
| [7] |
M. Rajappa, P. Saxena, J. Kaur, Chapter 6-ocular angiogenesis: Mechanisms and recent advances in therapy, Adv. Clin. Chem., 50 (2010), 103–121. https://doi.org/10.1016/S0065-2423(10)50006-4 doi: 10.1016/S0065-2423(10)50006-4
|
| [8] |
V. Tah, H. O. Orlans, J. Hyer, E. Casswell, N. Din, V. Sri Shanmuganathan, et al, Anti-VEGF therapy and the retina: An update, J. Ophthalmol., 2015 (2015). https://doi.org/10.1155/2015/627674 doi: 10.1155/2015/627674
|
| [9] |
H. Gerding, J. Monexs, R. Tadayoni, F. Boscia, I. Pearce, S. Priglinger, Ranibizumab in retinal vein occlusion: Treatment recommendations by an expert panel, Brit. J. Ophthalmol., 99 (2015), 297–304. https://doi.org/10.1136/bjophthalmol-2014-305041 doi: 10.1136/bjophthalmol-2014-305041
|
| [10] | D. Yorston, Anti-VEGF drugs in the prevention of blindness, Community Eye Health, 27 (2014), 44–46. |
| [11] |
R. Marano, I. Toth, N. Wimmer, M. Brankov, P. Rakoczy, Dendrimer delivery of an anti-VEGF oligonucleotide into the eye: A long-term study into inhibition of laser-induced CNV, distribution, uptake and toxicity, Gene Ther., 12 (2005), 1544–1550. https://doi.org/10.1038/sj.gt.3302579 doi: 10.1038/sj.gt.3302579
|
| [12] |
J. H. Chang, N. K. Garg, E. Lunde, K. Y. Han, S. Jain, D. T. Azar, Corneal neovascularization: An anti-VEGF therapy review, Surv. Ophthalmol., 57 (2012), 415–429. https://doi.org/10.1016/j.survophthal.2012.01.007 doi: 10.1016/j.survophthal.2012.01.007
|
| [13] |
J. M. Schmitt, Optical coherence tomography (OCT): A review, IEEE J. Sel. Top. Quant. Electron., 5 (1999), 1205–1215. https://doi.org/10.1109/2944.796348 doi: 10.1109/2944.796348
|
| [14] |
K. Gnep, A. Fargeas, R. E. Gutiexrrez-Carvajal, F. Commandeur, R. Mathieu, J. D. Ospina, et al., Haralick textural features on T2-weighted MRI are associated with biochemical recurrence following radiotherapy for peripheral zone prostate cancer, J. Magn. Reson. Imaging, 45 (2017), 103–117. https://doi.org/10.1002/jmri.25335 doi: 10.1002/jmri.25335
|
| [15] |
C. Shen, Z. Liu, Z. Wang, J. Guo, H. Zhang, Y. Wang, et al., Building CT radiomics based nomogram for preoperative esophageal cancer patients lymph node metastasis prediction, Transl. Oncol., 11 (2018), 815–824. https://doi.org/10.1016/j.tranon.2018.04.005 doi: 10.1016/j.tranon.2018.04.005
|
| [16] |
R. Paul, S. H. Hawkins, Y. Balagurunathan, M. Schabath, R. J. Gillies, L. O. Hall, et al., Deep feature transfer learning in combination with traditional features predicts survival among patients with lung adenocarcinoma, Tomography, 2 (2016), 388–395. https://doi.org/10.18383/j.tom.2016.00211 doi: 10.18383/j.tom.2016.00211
|
| [17] | W. Han, L. Qin, C. Bay, X. Chen, K. H. Yu, A. Li, et al., Integrating deep transfer learning and radiomics features in glioblastoma multiforme patient survival prediction, in Medical Imaging 2020: Image Processing, International Society for Optics and Photonics, (2020), 113132S. https://doi.org/10.1117/12.2549325 |
| [18] |
W. Han, L. Qin, C. Bay, X. Chen, K. H. Yu, N. Miskin, et al., Deep transfer learning and radiomics feature prediction of survival of patients with high-grade gliomas, Am. J. Neuroradiology, 41 (2020), 40–48. https://doi.org/10.3174/ajnr.A6365 doi: 10.3174/ajnr.A6365
|
| [19] |
N. Papandrianos, E. I. Papageorgiou, A. Anagnostis, Development of convolutional neural networks to identify bone metastasis for prostate cancer patients in bone scintigraphy, Ann. Nucl. Med., 34 (2020), 824–832. https://doi.org/10.1007/s12149-020-01510-6 doi: 10.1007/s12149-020-01510-6
|
| [20] | C. Fourcade, L. Ferrer, G. Santini, N. Moreau, C. Rousseau, M. Lacombe, et al., Combining superpixels and deep learning approaches to segment active organs in metastatic breast cancer PET images, in 2020 42nd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), IEEE, (2020), 1536–1539. https://doi.org/10.1109/EMBC44109.2020.9175683 |
| [21] |
K. H. Cha, L. Hadjiiski, H. P. Chan, A. Z. Weizer, A. Alva, R. H. Cohan, et al., Bladder cancer treatment response assessment in CT using radiomics with deep-learning, Sci. Rep., 7 (2017), 1–12. https://doi.org/10.1038/s41598-017-09315-w doi: 10.1038/s41598-017-09315-w
|
| [22] |
M. Byra, K. Dobruch-Sobczak, Z. Klimonda, H. Piotrzkowska-Wroblewska, J. Litniewski, Early prediction of response to neoadjuvant chemotherapy in breast cancer sonography using siamese convolutional neural networks, IEEE J. Biomed. Health Inf., 25 (2020), 797–805. https://doi.org/10.1109/JBHI.2020.3008040 doi: 10.1109/JBHI.2020.3008040
|
| [23] |
D. Romo-Bucheli, U. Erfurth, H. Bogunović, End-to-end deep learning model for predicting treatment requirements in neovascular AMD from longitudinal retinal OCT imaging, IEEE J. Biomed. Health Inf., 24 (2020), 3456–3465. https://doi.org/10.1109/JBHI.2020.3000136 doi: 10.1109/JBHI.2020.3000136
|
| [24] |
S. Starke, S. Leger, A. Zwanenburg, K. Leger, F. Lohaus, A. Linge, et al., 2D and 3D convolutional neural networks for outcome modelling of locally advanced head and neck squamous cell carcinoma, Sci. Rep., 10 (2020), 1–13. https://doi.org/10.1038/s41598-020-70542-9 doi: 10.1038/s41598-020-70542-9
|
| [25] | J. D. Cardosi, H. Shen, J. I. Groner, M. Armstrong, H. Xiang, Machine intelligence for outcome predictions of trauma patients during emergency department care, preprint, arXiv: 2009.03873. https://doi.org/10.48550/arXiv.2009.03873 |
| [26] |
M. Pease, D. Arefan, J. Biligen, J. Sharpless, A. Puccio, K. Hochberger, et al., Deep neural network analysis of CT scans to predict outcomes in a prospective database of severe traumatic brain injury patients, Neurosurgery, 67 (2020), 417. https://doi.org/10.1093/neuros/nyaa447_417 doi: 10.1093/neuros/nyaa447_417
|
| [27] | D. Feng, X. Chen, Z. Zhou, H. Liu, Y. Wang, L. Bai, et al., A preliminary study of predicting effectiveness of anti-VEGF injection using OCT images based on deep learning, in 42nd Annual International Conference of the IEEE Engineering in Medicine and Biology Society, (2020), 5428–5431. https://doi.org/10.1109/EMBC44109.2020.9176743 |
| [28] | M. Noroozi, A. Vinjimoor, P. Favaro, H. Pirsiavash, Boosting self-supervised learning via knowledge transfer, in 2018 IEEE Conference on Computer Vision and Pattern Recognition, (2018). https://doi.org/10.1109/CVPR.2018.00975 |
| [29] | C. Doersch, A. Gupta, A. A. Efros, Unsupervised visual representation learning by context prediction, in 2015 IEEE International Conference on Computer Vision, (2015), 1422–1430. https://doi.org/10.1109/ICCV.2015.167 |
| [30] | M. Noroozi, P. Favaro, Unsupervised learning of visual representations by solving jigsaw puzzles, preprint, arXiv: 1603.09246. https://doi.org/10.48550/arXiv.1603.09246 |
| [31] |
L. Chen, P. Bentley, K. Mori, K. Misawa, M. Fujiwara, et al., Self-supervised learning for medical image analysis using image context restoration, Med. Image Anal., 58 (2019), 101539. https://doi.org/10.1016/j.media.2019.101539 doi: 10.1016/j.media.2019.101539
|
| [32] |
J. Zhu, Y. Li, Y. Hu, K. Ma, S. K. Zhou, Y. Zheng, Rubik's cube+: A self-supervised feature learning framework for 3D medical image analysis, Med. Image Anal., 64 (2020), 101746. https://doi.org/10.1016/j.media.2020.101746 doi: 10.1016/j.media.2020.101746
|
| [33] | Z. Zhou, V. Sodha, M. M. R. Siddiquee, R. Feng, N. Tajbakhsh, M. B. Gotway, et al., Models genesis: Generic autodidactic models for 3D medical image analysis, in International Conference on Medical Image Computing and Computer Assisted Intervention, (2019), 384–393. https://doi.org/10.1007/978-3-030-32251-9_42 |
| [34] | G. Larsson, M. Maire, G. Shakhnarovich, Colorization as a proxy task for visual understanding, in 2017 IEEE Conference on Computer Vision and Pattern Recognition, (2017), 840–849. https://doi.org/10.1109/CVPR.2017.96 |
| [35] | T. Chen, S. Kornblith, M. Norouzi, G. E. Hinton, A simple framework for contrastive learning of visual representations, in Proceedings of the 37th International Conference on Machine Learning, preprint, arXiv: 2002.05709. |
| [36] | A. Van den Oord, Y. Li, O. Vinyals, Representation learning with contrastive predictive coding, preprint, arXiv: 1807.03748. |
| [37] | G. Lorre, J. Rabarisoa, A. Orcesi, S. Ainouz, S. Canu, Temporal contrastive pretraining for video action recognition, in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, (2020), 662–670. https://doi.org/10.1109/WACV45572.2020.9093278 |
| [38] | L. Tao, X. Wang, T. Yamasaki, Self-supervised video representation learning using inter- intra contrastive framework, in MM'20: The 28th ACM International Conference on Multimedia, (2020), 2193–2201. https://doi.org/10.1145/3394171.3413694 |
| [39] | Z. Wu, Y. Xiong, S. X. Yu, D. Lin, Unsupervised feature learning via non-parametric instance discrimination, in 2018 IEEE Conference on Computer Vision and Pattern Recognition, (2018), 3733–3742. https://doi.org/10.1109/CVPR.2018.00393 |
| [40] | K. He, H. Fan, Y. Wu, S. Xie, R. B. Girshick, Momentum contrast for unsupervised visual representation learning, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2020), 9726–9735. https://doi.org/10.1109/CVPR42600.2020.00975 |
| [41] | H. Spitzer, K. Kiwitz, K. Amunts, S. Harmeling, T. Dickscheid, Improving cytoarchitectonic segmentation of human brain areas with self-supervised siamese networks, in Medical Image Computing and Computer Assisted Intervention-MICCAI 201-21st International Conference, (2018), 663–671. https://doi.org/10.1007/978-3-030-00931-1 |
| [42] |
X. Li, M. Jia, M. T. Islam, L. Yu, L. Xing, Self-supervised feature learning via exploiting multi-modal data for retinal disease diagnosis, IEEE Trans. Med. Imaging, 39 (2020), 4023–4033. https://doi.org/10.1109/TMI.2020.3008871 doi: 10.1109/TMI.2020.3008871
|
| [43] |
D. S. Kermany, M. Goldbaum, W. Cai, C. C. Valentim, H. Liang, S. L. Baxter, et al., Identifying medical diagnoses and treatable diseases by image-based deep learning, Cell, 172 (2018), 1122–1131. https://doi.org/10.1016/j.cell.2018.02.010 doi: 10.1016/j.cell.2018.02.010
|
| [44] | M. E. Mortenson, Mathematics For Computer Graphics Applications, Industrial Press Inc., 1999. |
| [45] | O. Ronneberger, P. Fischer, T. Brox, U-net: Convolutional networks for biomedical image segmentation, in Medical Image Computing and Computer-Assisted Intervention-MIC-CAI 2015-18th International Conference Munich, (2015), 234–241. https://doi.org/10.1007/978-3-319-24574-4 |
| [46] |
C. Chang, C. Lin, LIBSVM: A library for support vector machines, ACM Trans. Intell. Syst. Technol., 2 (2011), 1–27. https://doi.org/10.1145/1961189.1961199 doi: 10.1145/1961189.1961199
|
| [47] |
V. N. Vapnik, An overview of statistical learning theory, IEEE Trans. Neural Networks, 10 (1999), 988–999. https://doi.org/10.1109/72.788640 doi: 10.1109/72.788640
|
| [48] |
D. Lu, K. Popuri, G. W. Ding, R. Balachandar, M. F. Beg, Multiscale deep neural network ased analysis of FDG-PET images for the early diagnosis of Alzheimer's disease, Med. Image Anal., 46 (2018), 26–34. https://doi.org/10.1016/j.media.2018.02.002 doi: 10.1016/j.media.2018.02.002
|
| [49] |
Y. Y. Liu, M. Chen, H. Ishikawa, G. Wollstein, J. S. Schuman, J. M. Rehg, Automated macular pathology diagnosis in retinal OCT images using multi-scale spatial pyramid and local binary patterns in texture and shape encoding, Med. Image Anal., 15 (2011), 748–59. https://doi.org/10.1016/j.media.2011.06.005 doi: 10.1016/j.media.2011.06.005
|
| [50] |
P. P. Srinivasan, L. A. Kim, P. S. Mettu, S. W. Cousins, G. M. Comer, J. A. Izatt, et al., Fully automated detection of diabetic macular edema and dry age-related macular degeneration from optical coherence tomography images, Biomed. Optics Express, 5 (2014), 3568–577. https://doi.org/10.1364/BOE.5.003568 doi: 10.1364/BOE.5.003568
|
| [51] |
R. Rasti, H. Rabbani, A. Mehridehnavi, F. Hajizadeh, Macular OCT classification using a multi-scale convolutional neural network ensemble, IEEE Trans. Med. Imaging, 37 (2017), 1024–034. https://doi.org/10.1109/TMI.2017.2780115 doi: 10.1109/TMI.2017.2780115
|
| [52] |
X. Wang, H. Chen, A. R. Ran, L. Luo, P. P. Chan, C. C. Tham, et al., Towards multi-center glaucoma OCT image screening with semi-supervised joint structure and function multi-task learning, Med. Image Anal., 63 (2020), 101695. https://doi.org/10.1016/j.media.2020.101695 doi: 10.1016/j.media.2020.101695
|
| [53] |
H. Bogunović, S. M. Waldstein, T. Schlegl, G. Langs, A. Sadeghipour, X. Liu, et al., Prediction of Anti-VEGF treatment requirements in neovascular amd using a machine learning approach, Investi. Ophth. Vis. Sci., 58 (2017), 3240–3248. https://doi.org/10.1167/iovs.16-21053 doi: 10.1167/iovs.16-21053
|
| [54] |
Z. Zhou, M. Folkert, P. Iyengar, K. Westover, Y. Zhang, H. Choy, et al., Multi-objective radiomics model for predicting distant failure in lung SBRT, Phys. Med. Biol., 62 (2017), 4460. https://doi.org/10.1088/1361-6560/aa6ae5 doi: 10.1088/1361-6560/aa6ae5
|
| [55] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in 2016 IEEE Conference on Computer Vision and Pattern Recognition, (2016), 770–78. https://doi.org/10.1109/CVPR.2016.90 |
| [56] | R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, D. Batra, Grad-CAM: Visual explanations from deep networks via gradient-based localization, in IEEE International Conference on Computer Vision, (2017), 618–626. https://doi.org/10.1109/ICCV.2017.74 |






Figures(7) / Tables(5)

Dehua Feng, Xi Chen, Xiaoyu Wang, Xuanqin Mou, Ling Bai, Shu Zhang, Zhiguo Zhou. Predicting effectiveness of anti-VEGF injection through self-supervised learning in OCT images[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 2439-2458. doi: 10.3934/mbe.2023114







 DownLoad:
DownLoad: