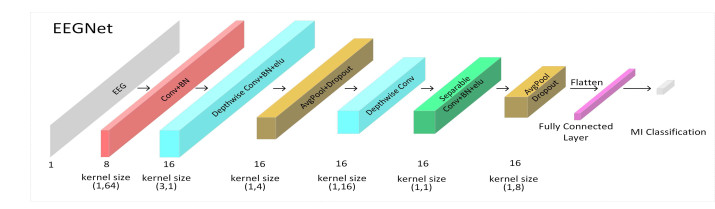
Motor Imagery EEG (MI-EEG) classification plays an important role in different Brain-Computer Interface (BCI) systems. Recently, deep learning has been widely used in the MI-EEG classification tasks, however this technology requires a large number of labeled training samples which are difficult to obtain, and insufficient labeled training samples will result in a degradation of the classification performance. To address the degradation problem, we investigate a Self-Supervised Learning (SSL) based MI-EEG classification method to reduce the dependence on a large number of labeled training samples. The proposed method includes a pretext task and a downstream classification one. In the pretext task, each MI-EEG is rearranged according to the temporal characteristic. A network is pre-trained using the original and rearranged MI-EEGs. In the downstream task, a MI-EEG classification network is firstly initialized by the network learned in the pretext task and then trained using a small number of the labeled training samples. A series of experiments are conducted on Data sets 1 and 2b of BCI competition IV and IVa of BCI competition III. In the case of one third of the labeled training samples, the proposed method can obtain an obvious improvement compared to the baseline network without using SSL. In the experiments under different percentages of the labeled training samples, the results show that the designed SSL strategy is effective and beneficial to improving the classification performance.
Citation: Yanghan Ou, Siqin Sun, Haitao Gan, Ran Zhou, Zhi Yang. An improved self-supervised learning for EEG classification[J]. Mathematical Biosciences and Engineering, 2022, 19(7): 6907-6922. doi: 10.3934/mbe.2022325
Motor Imagery EEG (MI-EEG) classification plays an important role in different Brain-Computer Interface (BCI) systems. Recently, deep learning has been widely used in the MI-EEG classification tasks, however this technology requires a large number of labeled training samples which are difficult to obtain, and insufficient labeled training samples will result in a degradation of the classification performance. To address the degradation problem, we investigate a Self-Supervised Learning (SSL) based MI-EEG classification method to reduce the dependence on a large number of labeled training samples. The proposed method includes a pretext task and a downstream classification one. In the pretext task, each MI-EEG is rearranged according to the temporal characteristic. A network is pre-trained using the original and rearranged MI-EEGs. In the downstream task, a MI-EEG classification network is firstly initialized by the network learned in the pretext task and then trained using a small number of the labeled training samples. A series of experiments are conducted on Data sets 1 and 2b of BCI competition IV and IVa of BCI competition III. In the case of one third of the labeled training samples, the proposed method can obtain an obvious improvement compared to the baseline network without using SSL. In the experiments under different percentages of the labeled training samples, the results show that the designed SSL strategy is effective and beneficial to improving the classification performance.

| [1] | P. Sandheep, S. Vineeth, M. Poulose, D. P. Subha, Performance analysis of deep learning CNN in classification of depression EEG signals, in TENCON 2019 - 2019 IEEE Region 10 Conference (TENCON), IEEE, (2019), 1339–1344. https://doi.org/10.1109/TENCON.2019.8929254 |
| [2] |
S. M. Usman, S. Khalid, R. Akhtar, Z. Bortolotto, Z. Bashir, H. Qiu, Using scalp EEG and intracranial EEG signals for predicting epileptic seizures: Review of available methodologies, Seizure, 71 (2019), 258–269. https://doi.org/10.1016/j.seizure.2019.08.006 doi: 10.1016/j.seizure.2019.08.006

|
| [3] |
F. Lotte, L. Bougrain, A. Cichocki, M. Clerc, M. Congedo, A. Rakotomamonjy, et al., A review of classification algorithms for EEG-based brain-computer interfaces: a 10 year update, J. Neural Eng., 15 (2018), 031005. https://doi.org/10.1088/1741-2552/aab2f2 doi: 10.1088/1741-2552/aab2f2
|
| [4] | B. J. Edelman, J. Meng, D. Suma, C. A. Zurn, E. Nagarajan, B. Baxter, et al., Noninvasive neuroimaging enhances continuous neural tracking for robotic device control, Sci. Rob., 4 (2019). https://doi.org/10.1126/scirobotics.aaw6844 |
| [5] |
Q. He, S. Du, Y. Zhang, G. Jiang, P. Xie, Classification of motor imagery based on single-channel frame and multi-channel frame, Yi Qi Yi Biao Xue Bao/Chin. J. Sci. Instrum., 39 (2018), 20–29. https://doi.org/10.19650/j.cnki.cjsi.J1803816 doi: 10.19650/j.cnki.cjsi.J1803816
|
| [6] |
J. M$\ddot{u}$ller-Gerking, G. Pfurtscheller, H. Flyvbjerg, Designing optimal spatial filters for single-trial EEG classification in a movement task, Clin. Neurophysiol., 110 (1999), 787–798. https://doi.org/10.1016/S1388-2457(98)00038-8 doi: 10.1016/S1388-2457(98)00038-8
|
| [7] | D. Huang, P. Lin, D. Fei, X. Chen, O. Bai, Decoding human motor activity from EEG single trials for a discrete two-dimensional cursor control, J. Neural Eng., 6 (2009). https://doi.org/10.1088/1741-2560/6/4/046005 |
| [8] | R. Chatterjee and T. Bandyopadhyay, EEG based motor imagery classification using SVM and MLP, in 2016 2nd International Conference on Computational Intelligence and Networks (CINE), (2016), 84–89. https://doi.org/10.1109/CINE.2016.22 |
| [9] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in 2016 IEEE Conference on Computer Vision and Pattern 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2016), 770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [10] | M. Tan and Q. V. Le, Efficientnet: Rethinking model scaling for convolutional neural networks, in Proceedings of the 36th International Conference on Machine Learning ICML (eds. K. Chaudhuri and R. Salakhutdinov), 97 (2019), 6105–6114. Available from: http://proceedings.mlr.press/v97/tan19a/tan19a.pdf. |
| [11] | X. Liu, Y. Shen, J. Liu, J. Yang, P. Xiong, F. Lin, Parallel spatial-temporal self-attention cnn-based motor imagery classification for bci, Front. Neurosci., 14 (2020). https://doi.org/10.3389/fnins.2020.587520 |
| [12] | P. Autthasan, R. Chaisaen, T. Sudhawiyangkul, S. Kiatthaveephong, P. Rangpong, N. Dilokthanakul, et al., MIN2net: End-to-end multi-task learning for subject-independent motor imagery EEG classification, IEEE Trans. Biomed. Eng., 2021. https://doi.org/10.1109/TBME.2021.3137184 |
| [13] |
R. T. Schirrmeister, J. T. Springenberg, L. D. J. Fiederer, M. Glasstetter, K. Eggensperger, M. Tangermann, et al., Deep learning with convolutional neural networks for EEG decoding and visualization, Hum. Brain Mapp., 38 (2017), 5391–5420. https://doi.org/10.1002/hbm.23730 doi: 10.1002/hbm.23730
|
| [14] | S. Ioffe and C. Szegedy, Batch normalization: Accelerating deep network training by reducing internal covariate shift, in Proceedings of the 32nd International Conference on Machine Learning ICML (eds. F. R. Bach and D. M. Blei), 37 (2015), 448–456. https://doi.org/10.48550/arXiv.1502.03167 |
| [15] | D. Clevert, T. Unterthiner, S. Hochreiter, Fast and accurate deep network learning by exponential linear units (elus), preprint, arXiv: 1511.07289. |
| [16] | H. Yang, S. Sakhavi, K. K. Ang, C. Guan, On the use of convolutional neural networks and augmented CSP features for multi-class motor imagery of EEG signals classification, in 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), IEEE, (2015), 2620–2623. https://doi.org/10.1109/EMBC.2015.7318929 |
| [17] | X. An, D. Kuang, X. Guo, Y. Zhao, L. He, A deep learning method for classification of EEG data based on motor imagery, in Intelligent Computing in Bioinformatics (eds. D. S. Huang, K. Han, M. Gromiha), ICIC 2014, Lecture Notes in Computer Science, Springer, 8590 (2014), 203–210. https://doi.org/10.1007/978-3-319-09330-7_25 |
| [18] |
M. Li, J. Han, J. Yang, Automatic feature extraction and fusion recognition of motor imagery EEG using multilevel multiscale CNN, Med. Biol. Eng. Comput., 59 (2021), 2037–2050. https://doi.org/10.1007/s11517-021-02396-w doi: 10.1007/s11517-021-02396-w
|
| [19] |
V. J. Lawhern, A. J. Solon, N. R. Waytowich, S. M. Gordon, C. P. Hung, B. J. Lance, EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces, J. Neural Eng., 15 (2018), 056013. https://doi.org/10.1088/1741-2552/aace8c doi: 10.1088/1741-2552/aace8c
|
| [20] | R. K. Malhotra and A. Y. Avidan, Sleep stages and scoring technique, in Atlas of Sleep Medicine, (2013), 77–99. https://doi.org/10.1016/B978-1-4557-1267-0.00003-5 |
| [21] | D. Hendrycks, M. Mazeika, S. Kadavath, D. Song, Using self-supervised learning can improve model robustness and uncertainty, in 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, Canada, (2019), 15637–15648. Available from: https://papers.nips.cc/paper/2019/file/a2b15837edac15df90721968986f7f8e-Paper.pdf. |
| [22] | M. Noroozi and P. Favaro, Unsupervised learning of visual representations by solving jigsaw puzzles, in Computer Vision - ECCV 2016 - 14th European Conference, Lecture Notes in Computer Science, Springer, (2016), 69–84. https://doi.org/10.1007/978-3-319-46466-4_5 |
| [23] | Y. Li, J. Zeng, S. Shan, X. Chen, Self-supervised representation learning from videos for facial action unit detection, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2019), 10924–10933. https://doi.org/10.1109/CVPR.2019.01118 |
| [24] | H. J. Banville, G. Moffat, I. Albuquerque, D. Engemann, A. Hyvärinen, A. Gramfort, Self-supervised representation learning from electroencephalography signals, in 2019 IEEE 29th International Workshop on Machine Learning for Signal Processing (MLSP), IEEE, (2019), 1–6. https://doi.org/10.1109/MLSP.2019.8918693 |
| [25] | A. Krizhevsky, I. Sutskever, G. E. Hinton, Imagenet classification with deep convolutional neural networks, in Advances in Neural Information Processing Systems 25: 26th Annual Conference on Neural Information Processing Systems 2012 (eds. P. L. Bartlett, F. C. N. Pereira, C. J. C. Burges, L. Bottou, K. Q. Weinberger), (2012), 1106–1114. https://doi.org/10.1145/3065386 |
| [26] | C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. E. Reed, D. Anguelov, et al., Going deeper with convolutions, in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2015), 1–9. https://doi.org/10.1109/CVPR.2015.7298594 |
| [27] | V. Nair, G. E. Hinton, Rectified linear units improve restricted boltzmann machines, in Proceedings of the 27th International Conference on Machine Learning (eds. J. Fürnkranz and T. Joachims), (2010), 807–814. Available from: https://icml.cc/Conferences/2010/papers/432.pdf. |
| [28] | A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, et al., Mobilenets: Efficient convolutional neural networks for mobile vision applications, preprint, arXiv: 1704.04861. |
| [29] | J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in 2018 IEEE Conference on Computer Vision and Pattern Recognition CVPR, (2018), 7132–7141. Available from: https://openaccess.thecvf.com/content_cvpr_2018/papers/Hu_Squeeze-and-Excitation_Networks_CVPR_2018_paper.pdf. |
| [30] |
G. Pfurtscheller and F. H. Lopes da Silva, Event-related EEG/MEG synchronization and desynchronization: basic principles, Clin. Neurophysiol., 110 (1999), 1842–1857. https://doi.org/10.1016/s1388-2457(99)00141-8 doi: 10.1016/s1388-2457(99)00141-8
|
| [31] | E. Dong, G. Zhu, C. Chen, Classification of four categories of EEG signals based on relevance vector machine, in 2017 IEEE International Conference on Mechatronics and Automation (ICMA), (2017), 1024–1029. https://doi.org/10.1109/ICMA.2017.8015957 |
| [32] |
Y. Meirovitch, H. Harris, E. Dayan, A. Arieli, T. Flash, Alpha and beta band event-related desynchronization reflects kinematic regularities, J. Neurosci., 35 (2015), 1627–1637. https://doi.org/10.1523/jneurosci.5371-13.2015 doi: 10.1523/jneurosci.5371-13.2015
|








Figures(9) / Tables(4)

Yanghan Ou, Siqin Sun, Haitao Gan, Ran Zhou, Zhi Yang. An improved self-supervised learning for EEG classification[J]. Mathematical Biosciences and Engineering, 2022, 19(7): 6907-6922. doi: 10.3934/mbe.2022325







 DownLoad:
DownLoad: