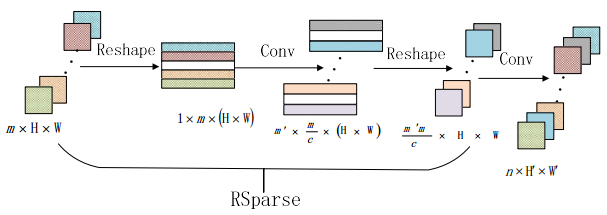
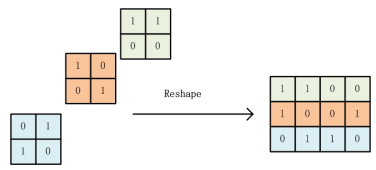
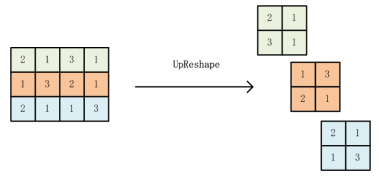
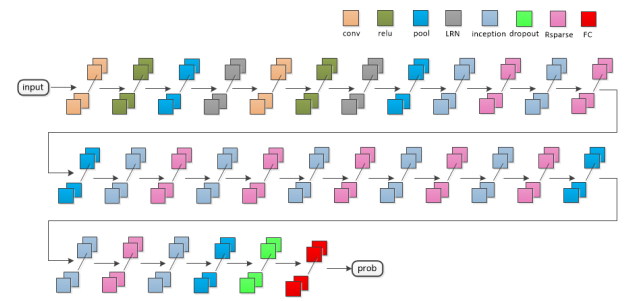
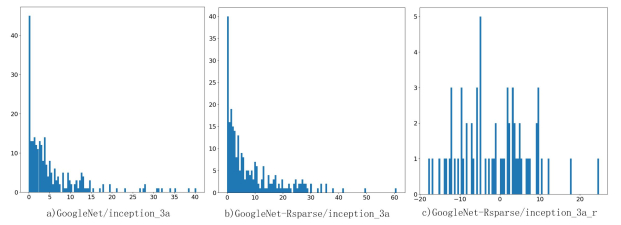
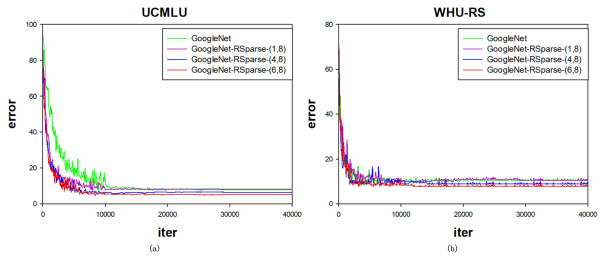
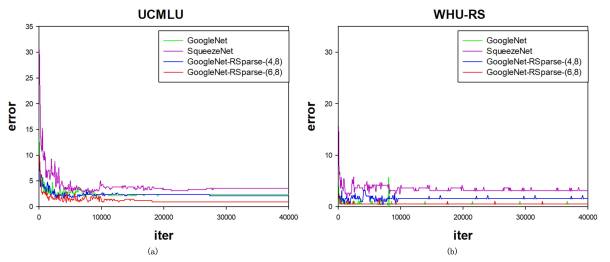
Deep learning tools have been a new way for privacy attacks on remote sensing images. However, since labeled data of privacy objects in remote sensing images are less, the samples for training are commonly small. Besides, traditional deep neural networks have a huge amount of parameters which leads to over complexity of models and have a great heavy of computation. They are not suitable for small sample image classification task. A sparse method for deep neural network is proposed to reduce the complexity of deep learning model with small samples. A singular value decomposition algorithm is employed to reduce the dimensions of the output feature map of the upper convolution layers, which can alleviate the input burden of the current convolution layer, and decrease a large number of parameters of the deep neural networks, and then restrain the number of redundant or similar feature maps generated by the over-complete schemes in deep learning. Experiments with two remote sensing image data sets UCMLU and WHURS show that the image classification accuracy with our sparse model is better than the plain model, which is improving the accuracy by 3%, besides, its convergence speed is faster.
Citation: Eric Ke Wang, Nie Zhe, Yueping Li, Zuodong Liang, Xun Zhang, Juntao Yu, Yunming Ye. A sparse deep learning model for privacy attack on remote sensing images[J]. Mathematical Biosciences and Engineering, 2019, 16(3): 1300-1312. doi: 10.3934/mbe.2019063
Deep learning tools have been a new way for privacy attacks on remote sensing images. However, since labeled data of privacy objects in remote sensing images are less, the samples for training are commonly small. Besides, traditional deep neural networks have a huge amount of parameters which leads to over complexity of models and have a great heavy of computation. They are not suitable for small sample image classification task. A sparse method for deep neural network is proposed to reduce the complexity of deep learning model with small samples. A singular value decomposition algorithm is employed to reduce the dimensions of the output feature map of the upper convolution layers, which can alleviate the input burden of the current convolution layer, and decrease a large number of parameters of the deep neural networks, and then restrain the number of redundant or similar feature maps generated by the over-complete schemes in deep learning. Experiments with two remote sensing image data sets UCMLU and WHURS show that the image classification accuracy with our sparse model is better than the plain model, which is improving the accuracy by 3%, besides, its convergence speed is faster.

| [1] | K. H.Wang, C. M. Chen, W. Fang et al., On the security of a new ultra-lightweight authentication protocol in iot environment for rfid tags, J. Supercomput., 74 (2017), 65-70. |
| [2] | C. M. Chen, B. Xiang, K. H. Wang, et al., A Robust mutual authentication with a key agreement scheme for session initiation protocol, Appl. Sci., 8 (2018). |
| [3] | E. Hazan, A. Klivans and Y. Yuan, Hyperparameter optimization: a spectral approach. ICLR 2018. |
| [4] | Y. Bengio, Deep learning of representations for unsupervised and transfer learning, ICML Unsupervised and Transfer Learning, 27 (2012), 17-36. |
| [5] | G. Mesnil, Y. Dauphin, X. Glorot, et al., Unsupervised and Transfer Learning Challenge: a Deep Learning Approach. ICML Unsupervised and Transfer Learning, 27 (2012), 97-110. |
| [6] | Y. Lecun, J. S. Denker and S. A. Solla, Optimal brain damage. international conference on neural information processing systems. MIT Press, San Mateo, CA: Morgan Kaufmann, (1989), 598- 605. |
| [7] | S. Han, H. Mao and W. J. Dally, Deep compression: compressing deep neural networks with pruning, trained quantization and huffman coding, Fiber, 56 (2015), 3-7. |
| [8] | F. N. Iandola, S. Han, M. W. Moskewicz, et al., SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and ¡ 0.5 MB model size. arXiv preprint arXiv: 1602.07360, 2016. |
| [9] | A. G. Howard, M. Zhu, B. Chen, et al., Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv: 1704.04861, 2017. |
| [10] | Y. Jia, E. Shelhamer, J. Donahue, et al., Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, ACM (2014), 675-678. |
| [11] | A. Vedaldi and K. Lenc, Matconvnet: Convolutional neural networks for matlab. In: Proceedings of the 23rd ACM international conference on Multimedia, 2015. |
| [12] | I. V. Oseledets. Tensor-Train decomposition. SIAM J. Sci. Comput., 33 (2011), 2295-2317. |
| [13] | E. Denton, W. Zaremba, J. Bruna, et al., Exploiting linear structure within convolutional networks for efficient evaluation. In: Advances in Neural Information Processing Systems, 2014. |
| [14] | M. Jaderberg, A. Vedaldi, and A. Zisserman, Speeding up convolutional neural networks with low rank expansions. Computer Science. In: Proc. BMVC, 2014. |
| [15] | B. Liu, W. Min, H. Foroosh, et al., Sparse convolutional neural networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2015), 806-814. |
| [16] | C. Kuo and C. Jay, Understanding convolutional neural networks with a mathematical model, J. Vis. Commun. Image R., 41 (2016). |
| [17] | Z. Wang, X. Wang, G. Wang, Learning Fine-grained Features via a CNN Tree for Large-scale Classification. Computer Science, 2015. |
| [18] | O. Alter, P. O. Brown and D. Botstein, Singular value decomposition for genome-wide expression data processing and modeling. P. Natl Acad. Sci. USA, 97 (2000), 10101-10106. |

Figures(8) / Tables(3)

Eric Ke Wang, Nie Zhe, Yueping Li, Zuodong Liang, Xun Zhang, Juntao Yu, Yunming Ye. A sparse deep learning model for privacy attack on remote sensing images[J]. Mathematical Biosciences and Engineering, 2019, 16(3): 1300-1312. doi: 10.3934/mbe.2019063







 DownLoad:
DownLoad: