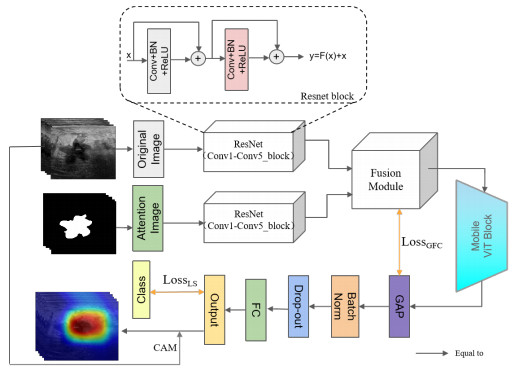
Ultrasonography is a widely used medical imaging technique for detecting breast cancer. While manual diagnostic methods are subject to variability and time-consuming, computer-aided diagnostic (CAD) methods have proven to be more efficient. However, current CAD approaches neglect the impact of noise and artifacts on the accuracy of image analysis. To enhance the precision of breast ultrasound image analysis for identifying tissues, organs and lesions, we propose a novel approach for improved tumor classification through a dual-input model and global average pooling (GAP)-guided attention loss function. Our approach leverages a convolutional neural network with transformer architecture and modifies the single-input model for dual-input. This technique employs a fusion module and GAP operation-guided attention loss function simultaneously to supervise the extraction of effective features from the target region and mitigate the effect of information loss or redundancy on misclassification. Our proposed method has three key features: (i) ResNet and MobileViT are combined to enhance local and global information extraction. In addition, a dual-input channel is designed to include both attention images and original breast ultrasound images, mitigating the impact of noise and artifacts in ultrasound images. (ii) A fusion module and GAP operation-guided attention loss function are proposed to improve the fusion of dual-channel feature information, as well as supervise and constrain the weight of the attention mechanism on the fused focus region. (iii) Using the collected uterine fibroid ultrasound dataset to train ResNet18 and load the pre-trained weights, our experiments on the BUSI and BUSC public datasets demonstrate that the proposed method outperforms some state-of-the-art methods. The code will be publicly released at https://github.com/425877/Improved-Breast-Ultrasound-Tumor-Classification.
Citation: Xiao Zou, Jintao Zhai, Shengyou Qian, Ang Li, Feng Tian, Xiaofei Cao, Runmin Wang. Improved breast ultrasound tumor classification using dual-input CNN with GAP-guided attention loss[J]. Mathematical Biosciences and Engineering, 2023, 20(8): 15244-15264. doi: 10.3934/mbe.2023682
Ultrasonography is a widely used medical imaging technique for detecting breast cancer. While manual diagnostic methods are subject to variability and time-consuming, computer-aided diagnostic (CAD) methods have proven to be more efficient. However, current CAD approaches neglect the impact of noise and artifacts on the accuracy of image analysis. To enhance the precision of breast ultrasound image analysis for identifying tissues, organs and lesions, we propose a novel approach for improved tumor classification through a dual-input model and global average pooling (GAP)-guided attention loss function. Our approach leverages a convolutional neural network with transformer architecture and modifies the single-input model for dual-input. This technique employs a fusion module and GAP operation-guided attention loss function simultaneously to supervise the extraction of effective features from the target region and mitigate the effect of information loss or redundancy on misclassification. Our proposed method has three key features: (i) ResNet and MobileViT are combined to enhance local and global information extraction. In addition, a dual-input channel is designed to include both attention images and original breast ultrasound images, mitigating the impact of noise and artifacts in ultrasound images. (ii) A fusion module and GAP operation-guided attention loss function are proposed to improve the fusion of dual-channel feature information, as well as supervise and constrain the weight of the attention mechanism on the fused focus region. (iii) Using the collected uterine fibroid ultrasound dataset to train ResNet18 and load the pre-trained weights, our experiments on the BUSI and BUSC public datasets demonstrate that the proposed method outperforms some state-of-the-art methods. The code will be publicly released at https://github.com/425877/Improved-Breast-Ultrasound-Tumor-Classification.

| [1] |
N. Wu, J. Phang, J. Park, Y. Shen, Z. Huang, M. Zorin, Deep neural networks improve radiologists' performance in breast cancer screening, IEEE Trans. Med. Imaging, 39 (2019), 1184–1194. https://doi.org/10.1109/TMI.2019.2945514 doi: 10.1109/TMI.2019.2945514

|
| [2] |
D. M. van der Kolk, G. H. de Bock, B. K. Leegte, M. Schaapveld, M. J. Mourits, J. de Vries, et al., Penetrance of breast cancer, ovarian cancer and contralateral breast cancer in BRCA1 and BRCA2 families: high cancer incidence at older age, Breast Cancer Res. Treat., 124 (2010), 643–651. https://doi.org/10.1007/s10549-010-0805-3 doi: 10.1007/s10549-010-0805-3
|
| [3] |
Q. Xia, Y. Cheng, J. Hu, J. Huang, Y. Yu, H. Xie, et al., Differential diagnosis of breast cancer assisted by s-detect artificial intelligence system, Math. Biosci. Eng., 18 (2021), 3680–3689. https://doi.org/10.3934/mbe.2021184 doi: 10.3934/mbe.2021184
|
| [4] |
S. Williamson, K. Vijayakumar, V. J. Kadam, Predicting breast cancer biopsy outcomes from bi-rads findings using random forests with chi-square and mi features, Multimedia Tools Appl., 81 (2022), 36869–36889. https://doi.org/10.1007/s11042-021-11114-5 doi: 10.1007/s11042-021-11114-5
|
| [5] |
D. J. Gavaghan, J. P. Whiteley, S. J. Chapman, J. M. Brady, P. Pathmanathan, Predicting tumor location by modeling the deformation of the breast, IEEE Trans. Biomed. Eng., 55 (2008), 2471–2480. https://doi.org/10.1109/TBME.2008.925714 doi: 10.1109/TBME.2008.925714
|
| [6] |
M. M. Ghiasi, S. Zendehboudi, Application of decision tree-based ensemble learning in the classification of breast cancer, Comput. Biol. Med., 128 (2021), 104089. https://doi.org/10.1016/j.compbiomed.2020.104089 doi: 10.1016/j.compbiomed.2020.104089
|
| [7] |
S. Liu, J. Zeng, H. Gong, H. Yang, J. Zhai, Y. Cao, et al., Quantitative analysis of breast cancer diagnosis using a probabilistic modelling approach, Comput. Biol. Med., 92 (2018), 168–175. https://doi.org/10.1016/j.compbiomed.2017.11.014 doi: 10.1016/j.compbiomed.2017.11.014
|
| [8] |
Y. Dong, J. Wan, L. Si, Y. Meng, Y. Dong, S. Liu, et al., Deriving polarimetry feature parameters to characterize microstructural features in histological sections of breast tissues, IEEE Trans. Biomed. Eng., 68 (2020), 881–892. https://doi.org/10.1109/TBME.2020.3019755 doi: 10.1109/TBME.2020.3019755
|
| [9] |
I. Elyasi, M. A. Pourmina, M. S. Moin, Speckle reduction in breast cancer ultrasound images by using homogeneity modified bayes shrink, Measurement, 91 (2016), 55–65. https://doi.org/10.1016/j.measurement.2016.05.025 doi: 10.1016/j.measurement.2016.05.025
|
| [10] |
H. H. Xu, Y. C. Gong, X. Y. Xia, D. Li, Z. Z. Yan, J. Shi, et al., Gabor-based anisotropic diffusion with lattice boltzmann method for medical ultrasound despeckling., Math. Biosci. Eng., 16 (2019), 7546–7561. https://doi.org/10.3934/mbe.2019379 doi: 10.3934/mbe.2019379
|
| [11] |
J. Levman, T. Leung, P. Causer, D. Plewes, A. L. Martel, Classification of dynamic contrast-enhanced magnetic resonance breast lesions by support vector machines, IEEE Trans. Biomed. Eng., 27 (2008), 688–696. https://doi.org/10.1109/TMI.2008.916959 doi: 10.1109/TMI.2008.916959
|
| [12] |
A. Ed-daoudy, K. Maalmi, Breast cancer classification with reduced feature set using association rules and support vector machine, Network Modeling Analysis in Health Informatics and Bioinformatics, 9 (2020), 1–10. https://doi.org/10.1007/s13721-020-00237-8 doi: 10.1007/s13721-020-00237-8
|
| [13] | R. Ranjbarzadeh, S. Dorosti, S. J. Ghoushchi, A. Caputo, E. B. Tirkolaee, S. S. Ali, et al., Breast tumor localization and segmentation using machine learning techniques: Overview of datasets, findings, and methods, Comput. Biol. Med., (2022), 106443. https://doi.org/10.1016/j.compbiomed.2022.106443 |
| [14] | P. Sathiyanarayanan, S. Pavithra, M. S. Saranya, M. Makeswari, Identification of breast cancer using the decision tree algorithm, in 2019 IEEE International Conference on System, Computation, Automation and Networking (ICSCAN), IEEE, (2019), 1–6. https://doi.org/10.1109/ICSCAN.2019.8878757 |
| [15] |
J. X. Tian, J. Zhang, Breast cancer diagnosis using feature extraction and boosted c5. 0 decision tree algorithm with penalty factor, Math. Biosci. Eng., 19 (2022), 2193–205. https://doi.org/10.3934/mbe.2022102 doi: 10.3934/mbe.2022102
|
| [16] |
S. Wang, Y. Wang, D. Wang, Y. Yin, Y. Wang, Y. Jin, An improved random forest-based rule extraction method for breast cancer diagnosis, Appl. Soft Comput., 86 (2020), 105941. https://doi.org/10.1016/j.asoc.2019.105941 doi: 10.1016/j.asoc.2019.105941
|
| [17] | T. Octaviani, d. Z. Rustam, Random forest for breast cancer prediction, in AIP Conference Proceedings, AIP Publishing LLC, 2168 (2019), 020050. https://doi.org/10.1063/1.5132477 |
| [18] | S. Das, O. R. R. Aranya, N. N. Labiba, Brain tumor classification using convolutional neural network, in 2019 1st International Conference on Advances in Science, Engineering and Robotics Technology (ICASERT), IEEE, (2019), 1–5. https://doi.org/10.1007/978-981-10-9035-6_33 |
| [19] |
R. Hao, K. Namdar, L. Liu, F. Khalvati, A transfer learning–based active learning framework for brain tumor classification, Front. Artif. Intell., 4 (2021), 635766. https://doi.org/10.3389/frai.2021.635766 doi: 10.3389/frai.2021.635766
|
| [20] |
Q. Zhang, C. Bai, Z. Liu, L. T. Yang, H. Yu, J. Zhao, et al., A gpu-based residual network for medical image classification in smart medicine, Inf. Sci., 536 (2020), 91–100. https://doi.org/10.1016/j.ins.2020.05.013 doi: 10.1016/j.ins.2020.05.013
|
| [21] |
Y. Dai, Y. Gao, F. Liu, Transmed: Transformers advance multi-modal medical image classification, Diagnostics, 11 (2021), 1384. https://doi.org/10.3390/diagnostics11081384 doi: 10.3390/diagnostics11081384
|
| [22] |
S. Aladhadh, M. Alsanea, M. Aloraini, T. Khan, S. Habib, M. Islam, An effective skin cancer classification mechanism via medical vision transformer, Sensors, 22 (2022), 4008. https://doi.org/10.3390/s22114008 doi: 10.3390/s22114008
|
| [23] | S. Yu, K. Ma, Q. Bi, C. Bian, M. Ning, N. He, et al., Mil-vt: Multiple instance learning enhanced vision transformer for fundus image classification, in Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part VIII 24, Springer, (2021), 45–54. https://doi.org/10.1007/978-3-030-87237-3_5 |
| [24] | F. Almalik, M. Yaqub, K. Nandakumar, Self-ensembling vision transformer (sevit) for robust medical image classification, in Medical Image Computing and Computer Assisted Intervention–MICCAI 2022: 25th International Conference, Singapore, September 18–22, 2022, Proceedings, Part III, Springer, (2022), 376–386. https://doi.org/10.1007/978-3-031-16437-8_36 |
| [25] |
Y. Wu, S. Qi, Y. Sun, S. Xia, Y. Yao, W. Qian, A vision transformer for emphysema classification using ct images, Phys. Med. Biol., 66 (2021), 245016. https://doi.org/10.1088/1361-6560/ac3dc8 doi: 10.1088/1361-6560/ac3dc8
|
| [26] | B. Hou, G. Kaissis, R. M. Summers, B. Kainz, Ratchet: Medical transformer for chest x-ray diagnosis and reporting, in Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part VII 24, Springer, (2021), 293–303. https://doi.org/10.1007/978-3-030-87234-2_28 |
| [27] | F. A. Spanhol, L. S. Oliveira, C. Petitjean, L. Heutte, Breast cancer histopathological image classification using convolutional neural networks, in 2016 International Joint Conference on Neural Networks (IJCNN), IEEE, (2016), 2560–2567. https://doi.org/10.1109/IJCNN.2016.7727519 |
| [28] | W. Lotter, G. Sorensen, D. Cox, A multi-scale cnn and curriculum learning strategy for mammogram classification, in Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Springer, (2017), 169–177. https://doi.org/10.1007/978-3-319-67558-9_20 |
| [29] | A. A. Nahid, M. A. Mehrabi, Y. Kong, Histopathological breast cancer image classification by deep neural network techniques guided by local clustering, Biomed Res. Int., 2018 (2018). https://doi.org/10.1155/2018/2362108 |
| [30] |
H. K. Mewada, A. V. Patel, M. Hassaballah, M. H. Alkinani, K. Mahant, Spectral–spatial features integrated convolution neural network for breast cancer classification, Sensors, 20 (2020), 4747. https://doi.org/10.3390/s20174747 doi: 10.3390/s20174747
|
| [31] |
W. Al-Dhabyani, M. Gomaa, H. Khaled, A. Fahmy, Dataset of breast ultrasound images, Data Brief, 28 (2020), 104863. https://doi.org/10.1016/j.dib.2019.104863 doi: 10.1016/j.dib.2019.104863
|
| [32] | P. S. Rodrigues, Breast ultrasound image, Mendeley Data, 1 (2017). https://doi.org/10.17632/wmy84gzngw.1 |
| [33] |
J. Virmani, R. Agarwal, Deep feature extraction and classification of breast ultrasound images, Multimedia Tools Appl., 79 (2020), 27257–27292. https://doi.org/10.1007/s11042-020-09337-z doi: 10.1007/s11042-020-09337-z
|
| [34] |
W. Al-Dhabyani, M. Gomaa, H. Khaled, F. Aly, Deep learning approaches for data augmentation and classification of breast masses using ultrasound images, Int. J. Adv. Comput. Sci. Appl., 10 (2019), 1–11. https://doi.org/10.14569/IJACSA.2019.0100579 doi: 10.14569/IJACSA.2019.0100579
|
| [35] |
N. Vigil, M. Barry, A. Amini, M. Akhloufi, X. P. Maldague, L. Ma, et al., Dual-intended deep learning model for breast cancer diagnosis in ultrasound imaging, Cancers, 14 (2022), 2663. https://doi.org/10.3390/cancers14112663 doi: 10.3390/cancers14112663
|
| [36] | T. Xiao, L. Liu, K. Li, W. Qin, S. Yu, Z. Li, Comparison of transferred deep neural networks in ultrasonic breast masses discrimination, Biomed Res. Int., 2018 (2018). https://doi.org/10.1155/2018/4605191 |
| [37] |
W. X. Liao, P. He, J. Hao, X. Y. Wang, R. L. Yang, D. An, et al., Automatic identification of breast ultrasound image based on supervised block-based region segmentation algorithm and features combination migration deep learning model, IEEE J. Biomed. Health. Inf., 24 (2019), 984–993. https://doi.org/10.1109/JBHI.2019.2960821 doi: 10.1109/JBHI.2019.2960821
|
| [38] |
W. K. Moon, Y. W. Lee, H. H. Ke, S. H. Lee, C. S. Huang, R. F. Chang, Computer-aided diagnosis of breast ultrasound images using ensemble learning from convolutional neural networks, Comput. Methods Programs Biomed., 190 (2020), 105361. https://doi.org/10.1016/j.cmpb.2020.105361 doi: 10.1016/j.cmpb.2020.105361
|
| [39] |
S. Acharya, A. Alsadoon, P. Prasad, S. Abdullah, A. Deva, Deep convolutional network for breast cancer classification: enhanced loss function (elf), J. Supercomput., 76 (2020), 8548–8565. https://doi.org/10.1007/s11227-020-03157-6 doi: 10.1007/s11227-020-03157-6
|
| [40] |
E. Y. Kalafi, A. Jodeiri, S. K. Setarehdan, N. W. Lin, K. Rahmat, N. A. Taib, et al., Classification of breast cancer lesions in ultrasound images by using attention layer and loss ensemble in deep convolutional neural networks, Diagnostics, 11 (2021), 1859. https://doi.org/10.3390/diagnostics11101859 doi: 10.3390/diagnostics11101859
|
| [41] | G. S. Tran, T. P. Nghiem, V. T. Nguyen, C. M. Luong, J. C. Burie, Improving accuracy of lung nodule classification using deep learning with focal loss, J. Healthcare Eng., 2019 (2019). https://doi.org/10.1155/2019/5156416 |
| [42] |
L. Ma, R. Shuai, X. Ran, W. Liu, C. Ye, Combining dc-gan with resnet for blood cell image classification, Med. Biol. Eng. Comput., 58 (2020), 1251–1264. https://doi.org/10.1007/s11517-020-02163-3 doi: 10.1007/s11517-020-02163-3
|
| [43] |
C. Zhao, R. Shuai, L. Ma, W. Liu, D. Hu, M. Wu, Dermoscopy image classification based on stylegan and densenet201, IEEE Access, 9 (2021), 8659–8679. https://doi.org/10.1109/ACCESS.2021.3049600 doi: 10.1109/ACCESS.2021.3049600
|
| [44] |
D. Sarwinda, R. H. Paradisa, A. Bustamam, P. Anggia, Deep learning in image classification using residual network (resnet) variants for detection of colorectal cancer, Procedia Comput. Sci., 179 (2021), 423–431. https://doi.org/10.1016/j.procs.2021.01.025 doi: 10.1016/j.procs.2021.01.025
|
| [45] | Y. Chen, Q. Zhang, Y. Wu, B. Liu, M. Wang, Y. Lin, Fine-tuning resnet for breast cancer classification from mammography, in Proceedings of the 2nd International Conference on Healthcare Science and Engineering 2nd, Springer, (2019), 83–96. https://doi.org/10.1007/978-981-13-6837-0_7 |
| [46] | F. Almalik, M. Yaqub, K. Nandakumar, Self-ensembling vision transformer (sevit) for robust medical image classification, in Medical Image Computing and Computer Assisted Intervention-MICCAI 2022, Springer, (2022), 376–386. https://doi.org/10.1007/978-3-031-16437-8_36 |
| [47] | B. Gheflati, H. Rivaz, Vision transformers for classification of breast ultrasound images, in 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), IEEE, (2022), 480–483. https://doi.org/10.1109/EMBC48229.2022.9871809 |
| [48] |
L. Yuan, X. Wei, H. Shen, L. L. Zeng, D. Hu, Multi-center brain imaging classification using a novel 3d cnn approach, IEEE Access, 6 (2018), 49925–49934. https://doi.org/10.1109/ACCESS.2018.2868813 doi: 10.1109/ACCESS.2018.2868813
|
| [49] |
J. Zhang, Y. Xie, Y. Xia, C. Shen, Attention residual learning for skin lesion classification, IEEE Trans. Med. Imaging, 38 (2019), 2092–2103. https://doi.org/10.1109/TMI.2019.2893944 doi: 10.1109/TMI.2019.2893944
|
| [50] |
B. Xu, J. Liu, X. Hou, B. Liu, J. Garibaldi, I. O. Ellis, et al., Attention by selection: A deep selective attention approach to breast cancer classification, IEEE Trans. Med. Imaging, 39 (2019), 1930–1941. https://doi.org/10.1109/TMI.2019.2962013 doi: 10.1109/TMI.2019.2962013
|
| [51] | Z. Zhang, M. Sabuncu, Generalized cross entropy loss for training deep neural networks with noisy labels, Adv. Neural Inf. Process. Syst., 31 (2018). |
| [52] | R. R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, D. Batra, Grad-cam: Visual explanations from deep networks via gradient-based localization, in Proceedings of the IEEE International Conference on Computer Vision, (2017), 618–626. https://doi.org/10.1109/ICCV.2017.74 |
| [53] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2016), 770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [54] | A. Howard, M. Sandler, G. Chu, L. C. Chen, B. Chen, M. Tan, et al., Searching for mobilenetv3, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2019), 1314–1324. https://doi.org/10.1109/ICCV.2019.00140 |
| [55] | X. Zhang, X. Zhou, M. Lin, J. Sun, Shufflenet: An extremely efficient convolutional neural network for mobile devices, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 6848–6856. https://doi.org/10.1109/CVPR.2018.00716 |
| [56] |
S. H. Gao, M. M. Cheng, K. Zhao, X. Y. Zhang, M. H. Yang, P. Torr, Res2net: A new multi-scale backbone architecture, IEEE Trans. Pattern Anal. Mach. Intell., 43 (2019), 652–662. https://doi.org/10.1109/TPAMI.2019.2938758 doi: 10.1109/TPAMI.2019.2938758
|
| [57] | Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, et al., Swin transformer: Hierarchical vision transformer using shifted windows, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2021), 10012–10022. |
| [58] | A. Trockman, J. Z. Kolter, Patches are all you need?, preprint, arXiv: 2201.09792. https://doi.org/10.48550/arXiv.2201.09792 |
| [59] | Z. Peng, W. Huang, S. Gu, L. Xie, Y. Wang, J. Jiao, et al., Conformer: Local features coupling global representations for visual recognition, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2021), 367–376. https://doi.org/10.1109/ICCV48922.2021.00042 |







Figures(8) / Tables(5)

Xiao Zou, Jintao Zhai, Shengyou Qian, Ang Li, Feng Tian, Xiaofei Cao, Runmin Wang. Improved breast ultrasound tumor classification using dual-input CNN with GAP-guided attention loss[J]. Mathematical Biosciences and Engineering, 2023, 20(8): 15244-15264. doi: 10.3934/mbe.2023682







 DownLoad:
DownLoad: