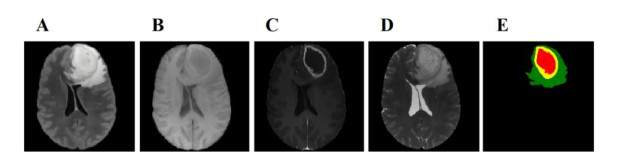
The accurate and fast segmentation method of tumor regions in brain Magnetic Resonance Imaging (MRI) is significant for clinical diagnosis, treatment and monitoring, given the aggressive and high mortality rate of brain tumors. However, due to the limitation of computational complexity, convolutional neural networks (CNNs) face challenges in being efficiently deployed on resource-limited devices, which restricts their popularity in practical medical applications. To address this issue, we propose a lightweight and efficient 3D convolutional neural network SDS-Net for multimodal brain tumor MRI image segmentation. SDS-Net combines depthwise separable convolution and traditional convolution to construct the 3D lightweight backbone blocks, lightweight feature extraction (LFE) and lightweight feature fusion (LFF) modules, which effectively utilizes the rich local features in multimodal images and enhances the segmentation performance of sub-tumor regions. In addition, 3D shuffle attention (SA) and 3D self-ensemble (SE) modules are incorporated into the encoder and decoder of the network. The SA helps to capture high-quality spatial and channel features from the modalities, and the SE acquires more refined edge features by gathering information from each layer. The proposed SDS-Net was validated on the BRATS datasets. The Dice coefficients were achieved 92.7, 80.0 and 88.9% for whole tumor (WT), enhancing tumor (ET) and tumor core (TC), respectively, on the BRTAS 2020 dataset. On the BRTAS 2021 dataset, the Dice coefficients were 91.8, 82.5 and 86.8% for WT, ET and TC, respectively. Compared with other state-of-the-art methods, SDS-Net achieved superior segmentation performance with fewer parameters and less computational cost, under the condition of 2.52 M counts and 68.18 G FLOPs.
Citation: Qian Wu, Yuyao Pei, Zihao Cheng, Xiaopeng Hu, Changqing Wang. SDS-Net: A lightweight 3D convolutional neural network with multi-branch attention for multimodal brain tumor accurate segmentation[J]. Mathematical Biosciences and Engineering, 2023, 20(9): 17384-17406. doi: 10.3934/mbe.2023773
The accurate and fast segmentation method of tumor regions in brain Magnetic Resonance Imaging (MRI) is significant for clinical diagnosis, treatment and monitoring, given the aggressive and high mortality rate of brain tumors. However, due to the limitation of computational complexity, convolutional neural networks (CNNs) face challenges in being efficiently deployed on resource-limited devices, which restricts their popularity in practical medical applications. To address this issue, we propose a lightweight and efficient 3D convolutional neural network SDS-Net for multimodal brain tumor MRI image segmentation. SDS-Net combines depthwise separable convolution and traditional convolution to construct the 3D lightweight backbone blocks, lightweight feature extraction (LFE) and lightweight feature fusion (LFF) modules, which effectively utilizes the rich local features in multimodal images and enhances the segmentation performance of sub-tumor regions. In addition, 3D shuffle attention (SA) and 3D self-ensemble (SE) modules are incorporated into the encoder and decoder of the network. The SA helps to capture high-quality spatial and channel features from the modalities, and the SE acquires more refined edge features by gathering information from each layer. The proposed SDS-Net was validated on the BRATS datasets. The Dice coefficients were achieved 92.7, 80.0 and 88.9% for whole tumor (WT), enhancing tumor (ET) and tumor core (TC), respectively, on the BRTAS 2020 dataset. On the BRTAS 2021 dataset, the Dice coefficients were 91.8, 82.5 and 86.8% for WT, ET and TC, respectively. Compared with other state-of-the-art methods, SDS-Net achieved superior segmentation performance with fewer parameters and less computational cost, under the condition of 2.52 M counts and 68.18 G FLOPs.

| [1] |
Z. Zhou, Z. He, Y. Jia, AFPNet: A 3D fully convolutional neural network with atrous-convolution feature pyramid for brain tumor segmentation via MRI images, Neurocomputing, 402 (2020), 235–244. https://10.1016/j.neucom.2020.03.097 doi: 10.1016/j.neucom.2020.03.097

|
| [2] |
R. Cao, X. Pei, N. Ge, C. Zheng, Clinical target volume auto-segmentation of esophageal cancer for radiotherapy after radical surgery based on deep learning, Technol. Cancer Res. Treat., 20 (2021), 15330338211034284. https://10.1177/15330338211034284 doi: 10.1177/15330338211034284
|
| [3] | J. Long, E. Shelhamer, T. Darrell, Fully convolutional networks for semantic segmentation, in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2015), 3431–3440. https://10.1109/CVPR.2015.7298965 |
| [4] | O. Ronneberger, P. Fischer, T. Brox, U-Net: Convolutional networks for biomedical image segmentation, in International Conference on Medical lmage Computing and Computer-Assisted Intervention, (2015), 234–241. https://10.1007/978-3-319-24574-4_28 |
| [5] | A. Hatamizadeh, Y. Tang, V. Nath, D. Yang, A. Myronenko, B. Landman, et al., UNETR: Transformers for 3D medical image segmentation, in 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), (2022), 1748–1758. https://10.1109/WACV51458.2022.00181 |
| [6] | A. Hou, L. Wu, H. Sun, Q. Yang, H. Ji, B. Cui, et al., Brain segmentation based on UNet++ with weighted parameters and convolutional neural network, in 2021 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), (2021), 644–648. https://10.1109/AEECA52519.2021.9574279 |
| [7] |
S. Li, J. Liu, Z. Song, Brain tumor segmentation based on region of interest-aided localization and segmentation U-Net, Int. J. Mach. Learn. Cybern., 13 (2022), 2435–2445. https://10.1007/s13042-022-01536-4 doi: 10.1007/s13042-022-01536-4
|
| [8] |
N. Sheng, D. Liu, J. Zhang, C. Che, J. Zhang, Second-order ResU-Net for automatic MRI brain tumor segmentation, Math. Biosci. Eng., 18 (2021), 4943–4960. https://10.3934/mbe.2021251 doi: 10.3934/mbe.2021251
|
| [9] | A. Jungo, R. Mckinley, R. Meier, U. Knecht, L. Vera, J. Pérez-Beteta, et al., Towards uncertainty-assisted brain tumor segmentation and survival prediction, in International MICCAI Brainlesion Workshop, (2018), 474–485. https://10.1007/978-3-319-75238-9_40 |
| [10] |
N. Cinar, A. Ozcan, M. Kaya, A hybrid DenseNet121-UNet model for brain tumor segmentation from MR Images, Biomed. Signal Process. Control, 76 (2022), 103647. https://10.1016/j.bspc.2022.103647 doi: 10.1016/j.bspc.2022.103647
|
| [11] |
L. Wu, S. Hu, C. Liu, MR brain segmentation based on DE-ResUnet combining texture features and background knowledge, Biomed. Signal Process. Control, 75 (2022), 103541. https://10.1016/j.bspc.2022.103541 doi: 10.1016/j.bspc.2022.103541
|
| [12] |
M. Jiang, F. Zhai, J. Kong, A novel deep learning model DDU-net using edge features to enhance brain tumor segmentation on MR images, Artif. Intell. Med., 121 (2021), 102180. https://10.1016/j.artmed.2021.102180 doi: 10.1016/j.artmed.2021.102180
|
| [13] | Ö. Çiçek, A. Abdulkadir, S. S. Lienkamp, T. Brox, O. Ronneberger, 3D U-Net: Learning dense volumetric segmentation from sparse annotation, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2016), 424–432. https://10.1007/978-3-319-46723-8_49 |
| [14] | R. Mehta, T. Arbel, 3D U-Net for brain tumour segmentation, in International MICCAI Brainlesion Workshop, (2019), 254–266. https://10.1007/978-3-030-11726-9_23 |
| [15] |
A. Abdollahi, B. Pradhan, A. Alamri, VNet: An end-to-end fully convolutional neural network for road extraction from high-resolution remote sensing data, IEEE Access, 8 (2020), 179424–179436. https://10.1109/ACCESS.2020.3026658 doi: 10.1109/ACCESS.2020.3026658
|
| [16] |
Z. Zhu, X. He, G. Qi, Y. Li, B. Cong, Y. Liu, Brain tumor segmentation based on the fusion of deep semantics and edge information in multimodal MRI, Inf. Fusion, 91 (2023), 376–387. https://10.1016/j.inffus.2022.10.022 doi: 10.1016/j.inffus.2022.10.022
|
| [17] |
Y. Li, Z. Wang, L. Yin, Z. Zhu, G. Qi, Y. Liu, X-Net: A dual encoding–decoding method in medical image segmentation, Vis. Comput., 39 (2023), 2223–2233. https://10.1007/s00371-021-02328-7 doi: 10.1007/s00371-021-02328-7
|
| [18] |
Y. Xu, X. He, G. Xu, G. Qi, K. Yu, L. Yin, et al., A medical image segmentation method based on multi-dimensional statistical features, Front. Neurosci., 16 (2022). https://10.3389/fnins.2022.1009581 doi: 10.3389/fnins.2022.1009581
|
| [19] |
D. Kong, X. Liu, Y. Wang, D. Li, J. Xue, 3D hierarchical dual-attention fully convolutional networks with hybrid losses for diverse glioma segmentation, Knowl. Based Syst., 237 (2022), 107692. https://10.1016/j.knosys.2021.107692 doi: 10.1016/j.knosys.2021.107692
|
| [20] | O. Oktay, J. Schlemper, L. L. Folgoc, M. J. Lee, M. P. Heinrich, K. Misawa, et al., Attention U-Net: Learning where to look for the pancreas, preprint, arXiv: 1804.03999. https://10.48550/arXiv.1804.03999 |
| [21] |
X. He, G. Qi, Z. Zhu, Y. Li, B. Cong, L. Bai, Medical image segmentation method based on multi-feature interaction and fusion over cloud computing, Simul. Model. Pract. Theory, 126 (2023), 102769. https://10.1016/j.simpat.2023.102769 doi: 10.1016/j.simpat.2023.102769
|
| [22] | A. G. Roy, N. Navab, C. Wachinger, Concurrent spatial and channel 'squeeze & excitation'in fully convolutional networks, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2018), 421–429. https://10.1007/978-3-030-00928-1_48 |
| [23] | Q. L. Zhang, Y. B. Yang, SA-Net: Shuffle attention for deep convolutional neural networks, in ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), (2021), 2235–2239. https://10.1109/ICASSP39728.2021.9414568 |
| [24] | A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, et al., Mobilenets: Efficient convolutional neural networks for mobile vision applications, preprint, arXiv: 1704.04861. https://10.48550/arXiv.1704.04861 |
| [25] | X. Zhang, X. Zhou, M. Lin, J. Sun, Shufflenet: An extremely efficient convolutional neural network for mobile devices, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 6848–6856. https://10.1109/CVPR.2018.00716 |
| [26] | K. Han, Y. Wang, Q. Tian, J. Guo, C. Xu, C. Xu, Ghostnet: More features from cheap operations, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2020), 1580–1589. https://10.1109/CVPR42600.2020.00165 |
| [27] |
X. Zhou, X. Li, K. Hu, Y. Zhang, Z. Chen, X. Gao, ERV-Net: An efficient 3D residual neural network for brain tumor segmentation, Expert Syst. Appl., 170 (2021), 114566. https://10.1016/j.eswa.2021.114566 doi: 10.1016/j.eswa.2021.114566
|
| [28] |
K. R. Reddy, R. Dhuli, A novel lightweight CNN architecture for the diagnosis of brain tumors using MR images, Diagnostics, 13 (2023), 312. https://10.3390/diagnostics13020312 doi: 10.3390/diagnostics13020312
|
| [29] |
Z. Luo, Z. Jia, Z. Yuan, J. Peng, HDC-Net: Hierarchical decoupled convolution network for brain tumor segmentation, IEEE J. Biomed. Health Inform., 25 (2021), 737–745. https://10.1109/JBHI.2020.2998146 doi: 10.1109/JBHI.2020.2998146
|
| [30] |
R. Zhang, S. Jia, M. J. Adamuand, W. Nie, Q. Li, T. Wu, HMNet: Hierarchical multi-scale brain tumor segmentation network, J. Clin. Med., 12 (2023), 538. https://10.3390/jcm12020538 doi: 10.3390/jcm12020538
|
| [31] | U. Baid, S. Ghodasara, S. Mohan, M. Bilello, E. Calabrese, E. Colak, et al., The RSNA-ASNR-MICCAI BraTS 2021 benchmark on brain tumor segmentation and radiogenomic classification, preprint, arXiv: 2107.02314. https://10.48550/arXiv.2107.02314 |
| [32] |
B. H. Menze, A. Jakab, S. Bauer, J. Kalpathy-Cramer, K. Farahani, J. Kirby, et al., The multimodal brain tumor image segmentation benchmark (BRATS), IEEE Trans. Med. Imaging, 34 (2015), 1993–2024. https://10.1109/TMI.2014.2377694 doi: 10.1109/TMI.2014.2377694
|
| [33] |
S. Bakas, H. Akbari, A. Sotiras, M. Bilello, M. Rozycki, J. S. Kirby, et al., Advancing the cancer genome atlas glioma MRI collections with expert segmentation labels and radiomic features, Sci. Data, 4 (2017), 170117. https://10.1038/sdata.2017.117 doi: 10.1038/sdata.2017.117
|
| [34] |
Y. Cao, W. Zhou, M. Zang, D. An, Y. Feng, B. Yu, MBANet: A 3D convolutional neural network with multi-branch attention for brain tumor segmentation from MRI images, Biomed. Signal Process. Control, 80 (2023), 104296. https://10.1016/j.bspc.2022.104296 doi: 10.1016/j.bspc.2022.104296
|
| [35] |
P. Wang, A. C. S. Chung, Relax and focus on brain tumor segmentation, Med. Image Anal., 75 (2022), 102259. https://10.1016/j.media.2021.102259 doi: 10.1016/j.media.2021.102259
|
| [36] | X. Li, W. Wang, X. Hu, J. Yang, Selective kernel networks, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 510–519. https://10.1109/CVPR.2019.00060 |
| [37] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in 2016 IEEE Conference on Computer Vision and Pattern Recognition(CVPR), (2016), 770–778. https://10.1109/CVPR.2016.90 |
| [38] |
A. Krizhevsky, I. Sutskever, G. E. Hinton, ImageNet classification with deep convolutional neural networks, Commun. ACM, 60 (2017), 84–90. https://10.1145/3065386 doi: 10.1145/3065386
|
| [39] | Y. X. Zhao, Y. M. Zhang, C. L. Liu, Bag of tricks for 3D MRI brain tumor segmentation, in International MICCAI Brainlesion Workshop, (2019), 210–220. https://10.1007/978-3-030-46640-4_20 |
| [40] |
D. Liu, N. Sheng, T. He, W. Wang, J. Zhang, J. Zhang, SGEResU-Net for brain tumor segmentation, Math. Biosci. Eng., 19 (2022), 5576–5590. https://10.3934/mbe.2022261 doi: 10.3934/mbe.2022261
|
| [41] | F. Isensee, P. F. Jäger, P. M. Full, P. Vollmuth, K. H. Maier-Hein, nnU-Net for brain tumor segmentation, in International MICCAI Brainlesion Workshop, (2021), 118–132. https://10.1007/978-3-030-72087-2_11 |
| [42] | W. Wang, C. Chen, M. Ding, H. Yu, S. Zha, J. Li, TransBTS: Multimodal brain tumor segmentation using transformer, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2021), 109–119. https://10.1007/978-3-030-87193-2_11 |
| [43] | Z. Xing, L. Yu, L. Wan, T. Han, L. Zhu, NestedFormer: Nested modality-aware transformer for brain tumor segmentation, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2022), 140–150. https://10.1007/978-3-031-16443-9_14 |
| [44] | N. Nuechterlein, S. Mehta, 3D-ESPNet with pyramidal refinement for volumetric brain tumor image segmentation, in International MICCAI Brainlesion Workshop, (2018), 245–253. https://10.1007/978-3-030-11726-9_22 |
| [45] | C. Chen, X. Liu, M. Ding, J. Zheng, J. Li, 3D dilated multi-fiber network for real-time brain tumor segmentation in MRI, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2019), 184–192. https://10.1007/978-3-030-32248-9_21 |
| [46] | H. Peiris, Z. Chen, G. Egan, M. Harandi, Reciprocal adversarial learning for brain tumor segmentation: A solution to BraTS challenge 2021 segmentation task, in International MICCAI Brainlesion Workshop, (2022), 171–181. https://10.1007/978-3-031-08999-2_13 |
| [47] |
Y. Jiang, Y. Zhang, X. Lin, J. Dong, T. Cheng, J. Liang, SwinBTS: A method for 3D multimodal brain tumor segmentation using swin transformer, Brain Sci., 12 (2022). https://10.3390/brainsci12060797 doi: 10.3390/brainsci12060797
|










Figures(11) / Tables(6)

Qian Wu, Yuyao Pei, Zihao Cheng, Xiaopeng Hu, Changqing Wang. SDS-Net: A lightweight 3D convolutional neural network with multi-branch attention for multimodal brain tumor accurate segmentation[J]. Mathematical Biosciences and Engineering, 2023, 20(9): 17384-17406. doi: 10.3934/mbe.2023773







 DownLoad:
DownLoad: