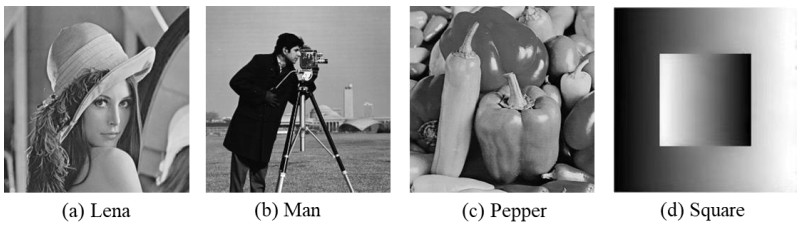
Inspired by the ROF model and the $ {L}^{1}/TV $ image denoising model, we propose a combined model to remove Gaussian noise and salt-and-pepper noise simultaneously. This model combines the $ {L}^{1} $ -data fidelity term, $ {L}^{2} $ -data fidelity term and a fractional-order total variation regularization term, and is termed the $ {L}^{1}{L}^{2}/{TV}^{\alpha } $ model. We have used the proximity algorithm to solve the proposed model. Through this method, the non-differentiable term is solved by using the fixed-point equations of the proximity operator. The numerical experiments show that the proposed model can effectively remove Gaussian noise and salt and pepper noise through implementation of the proximity algorithm. As we varied the fractional order $ \alpha $ from 0.8 to 1.9 in increments of 0.1, we observed that different images correspond to different optimal values of α.
Citation: Donghong Zhao, Ruiying Huang, Li Feng. Proximity algorithms for the $ {\mathit{L}}^{1}{\mathit{L}}^{2}/{\mathit{T}\mathit{V}}^{\mathit{\alpha }} $ image denoising model[J]. AIMS Mathematics, 2024, 9(6): 16643-16665. doi: 10.3934/math.2024807
Inspired by the ROF model and the $ {L}^{1}/TV $ image denoising model, we propose a combined model to remove Gaussian noise and salt-and-pepper noise simultaneously. This model combines the $ {L}^{1} $ -data fidelity term, $ {L}^{2} $ -data fidelity term and a fractional-order total variation regularization term, and is termed the $ {L}^{1}{L}^{2}/{TV}^{\alpha } $ model. We have used the proximity algorithm to solve the proposed model. Through this method, the non-differentiable term is solved by using the fixed-point equations of the proximity operator. The numerical experiments show that the proposed model can effectively remove Gaussian noise and salt and pepper noise through implementation of the proximity algorithm. As we varied the fractional order $ \alpha $ from 0.8 to 1.9 in increments of 0.1, we observed that different images correspond to different optimal values of α.

| [1] |
L. I. Rudin, S. Osher, E. Fatemi, Nonlinear total variation-based noise removal algorithms, Physical. D, 60 (1992), 259–268. https://doi.org/10.1016/0167-2789(92)90242-F doi: 10.1016/0167-2789(92)90242-F

|
| [2] |
A. Chambolle, V. Caselles, D. Cremers, M. Novaga, T. Pock, An introduction to total variation for image analysis, Radon Series Comp. Appl. Math., 9 (2010), 263–340. https://doi.org/10.1515/9783110226157.263 doi: 10.1515/9783110226157.263
|
| [3] |
Y. L. You, M. Kaveh, Fourth-order partial differential equations for noise removal, IEEE Trans. Image Process., 9 (2000), 1723–1730. https://doi.org/10.1109/83.869184 doi: 10.1109/83.869184
|
| [4] |
M. Lysaker, A. Lundervold, X. C. Tai, Noise removal using fourth-order partial differential equation with applications to medical magnetic resonance images in space and time, IEEE Trans. Image Process., 12 (2003), 1579–1590. https://doi.org/10.1109/TIP.2003.819229 doi: 10.1109/TIP.2003.819229
|
| [5] |
X. W. Liu, L. H. Huang, Z. Y. Gao, Adaptive fourth-order partial differential equation filter for image denoising, Appl. Math. Lett., 24 (2011), 1282–1288. https://doi.org/10.1016/j.aml.2011.01.028 doi: 10.1016/j.aml.2011.01.028
|
| [6] |
D. N. H. Thanh, V. B. S. Prasath, L. M. Hieu, A review on CT and X-Ray images denoising methods, Informatica, 43 (2019), 151–159. https://doi.org/10.31449/INF.V43I2.2179 doi: 10.31449/INF.V43I2.2179
|
| [7] | D. N. H. Thanh, V. B. S. Prasath, L.T. Thanh, Total variation L1 fidelity Salt-and-pepper denoising with adaptive regularization parameter, In: 2018 5th NAFOSTED Conference on information and computer science (NICS), 2018,400–405. https://doi.org/10.1109/NICS.2018.8606870 |
| [8] |
T. F. Chan, S. Esedo, Aspects of total variation regularized L1 function approximation, SIAM. J. Appl. Math., 65 (2005), 1817–1837. https://doi.org/10.1137/040604297 doi: 10.1137/040604297
|
| [9] |
W. Yin, D. Goldfard, S. Osher, The total variation regularized L1 model for multiscale decomposition, Multiscale Model. Simul., 6 (2007), 190–211. https://doi.org/10.1137/060663027 doi: 10.1137/060663027
|
| [10] |
T. Chen, W. Yin, X. S. Zhou, D. Comaniciu, T. S. Huang, Total variation models for variable lighting face regularization, IEEE Trans. Pattern Anal. Mach. Intell., 28 (2006), 1519–1524. https://doi.org/10.1109/TPAMI.2006.195 doi: 10.1109/TPAMI.2006.195
|
| [11] | C. Zach, T. Pock, H. Bischof, A duality based approach for real time TV-L1 optical flow, In: Lecture notes in computer science, Heidelberg: Springer, Berlin, 4713 (2007), 214–223. https://doi.org/10.1007/978-3-540-74936-3_22 |
| [12] |
K. Padmavathi, C.S. Asha, V. K. Maya, A novel medical image fusion by combining TV-L1 decomposed textures based on adaptive weighting scheme, Eng. Sci. Technol., 23 (2020), 225–239. https://doi.org/10.1016/j.jestch.2019.03.008 doi: 10.1016/j.jestch.2019.03.008
|
| [13] |
M. Hintermüller, A. Langer, Subspace correction methods for a class of nonsmooth and nonadditive convex variational problems with mixed L1- L2data-fidelity in image processing, SIAM. J. Imaging Sci., 6 (2013), 34–73. https://doi.org/10.1137/120894130 doi: 10.1137/120894130
|
| [14] |
Z. Gong, Z. Shen, K. C. Toh, Image restoration with mixed or unknown noises, Multiscale Model. Simul., 12 (2014), 58–87. https://doi.org/10.1137/130904533 doi: 10.1137/130904533
|
| [15] |
A. Langer, Automated parameter selection in the L1-L2-TV model for removing Gaussian plus impulse noise, Inverse probl., 33 (2017), 074002. https://doi.org/10.1088/1361-6420/33/7/074002 doi: 10.1088/1361-6420/33/7/074002
|
| [16] |
D. N. H. Thanh, L. T. Thanh, N. N. Hien, S. Prasath, Adaptive total variation L1 regularization for salt and pepper image denoising, Optik, 208 (2008), 163677. https://doi.org/10.1016/j.ijleo.2019.163677 doi: 10.1016/j.ijleo.2019.163677
|
| [17] |
R. W. Liu, L. Shi, S. C. H. Yu, D. Wang, Box-constrained second-order total generalized variation minimization with a combined L1,2 data-fidelity term for image reconstruction, J. Electron Imaging, 34 (2015), 033026. https://doi.org/10.1117/1.JEI.24.3.033026 doi: 10.1117/1.JEI.24.3.033026
|
| [18] |
K. Bredies, K. Kunisch, T. Pock, Total generalized variation, SIAM. J. Imaging Sci., 3 (2010), 492–526. https://doi.org/10.1137/090769521 doi: 10.1137/090769521
|
| [19] |
D. Chen, Y. Chen, D. Xue, Fractional-order total variation image restoration based on primal-dual algorithm, Abstr. Appl. Anal., 2013 (2013), 585310. https://doi.org/10.1155/2013/585310 doi: 10.1155/2013/585310
|
| [20] |
D. Chen, H. Sheng, Y. Chen, D. Xue, Fractional-order variational optical flow model for motion estimation, Philos. Trans. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci., 371 (2013), 20120148. https://doi.org/10.1098/rsta.2012.0148 doi: 10.1098/rsta.2012.0148
|
| [21] |
J. Zhang, Z. Wei, A class of fractional-order multi-scale variational models and alternating projection algorithm for image denoising, Appl. Math. Model., 35 (2011), 2516–2528. https://doi.org/10.1016/j.apm.2010.11.049 doi: 10.1016/j.apm.2010.11.049
|
| [22] |
J. Zhang, Z. Wei, L. Xiao, Adaptive fractional-order multi-scale method for image denoising, J. Math. Imaging. Vis., 43 (2012), 39–49. https://doi.org/10.1007/s10851-011-0285-z doi: 10.1007/s10851-011-0285-z
|
| [23] |
D. Chen, S. Sun, C. Zhang, Y. Chen, D. Xue, Fractional-order TV-L2 model for image denoising, Cent. Eur. J. Phys., 11 (2013), 1414–1422. https://doi.org/10.2478/s11534-013-0241-1 doi: 10.2478/s11534-013-0241-1
|
| [24] |
J. F. Cai, S. Osher, Z. W. Shen, Split Bregman methods and frame based image restoration, Multiscale Model. Simul., 8 (2009), 337–369. https://doi.org/10.1137/090753504 doi: 10.1137/090753504
|
| [25] |
Z. Qin, D. Goldfarb, S. Ma, An alternating direction method for total variation denoising, Optim. Methods Softw., 30 (2011), 594–615. https://doi.org/10.1080/10556788.2014.955100 doi: 10.1080/10556788.2014.955100
|
| [26] |
C. A. Micchelli, L. Shen, Y. Xu, Proximity algorithms for image models: denoising, Inverse Probl., 27 (2011), 045009. https://doi.org/10.1088/0266-5611/27/4/045009 doi: 10.1088/0266-5611/27/4/045009
|
| [27] |
Q. Li, C. A. Micchelli, L. Shen, Y. Xu, A proximity algorithm accelerated by Gauss-Seidel iterations for L1/TV denoising models, Inverse Probl., 28 (2012), 095003. https://doi.org/10.1088/0266-5611/28/9/095003 doi: 10.1088/0266-5611/28/9/095003
|
| [28] |
C. A. Micchelli, L. Shen, Y. Xu, X. Zeng, Proximity algorithms for the L1/TV image denoising model, Adv. Comput. Math., 38 (2013), 401–426. https://doi.org/10.1007/s10444-011-9243-y doi: 10.1007/s10444-011-9243-y
|
| [29] |
D. Chen, Y. Chen, D. Xue, Fractional-order total variation image denoising based on proximity algorithm, Appl. Math. Comput., 257 (2015), 537–545. https://doi.org/10.1016/j.amc.2015.01.012 doi: 10.1016/j.amc.2015.01.012
|
| [30] |
Y. H. Hu, C. Li, X. Q. Yang, On convergence rates of linear proximal algorithms for convex composite optimization with applications, SIAM J. Optim., 26 (2016), 1207–1235. https://doi.org/10.1137/140993090 doi: 10.1137/140993090
|
| [31] | J. J. Moreau, Fonctions convexes duales et points proximaux dans un espace hilbertien, Comptes rendus hebdomadaires des séances de l'Académie des sciences, 255 (1962), 2897–2899. |
| [32] |
P. L. Combettes, V. R. Wajs, Signal recovery by proximal forward-backward splitting, Multiscale Model. Simul., 4 (2005), 1168–1120. https://doi.org/10.1137/050626090 doi: 10.1137/050626090
|
| [33] |
X. Y. Yu, D. H. Zhao, A weberized total variance regularization-based image multiplicative noise model, Image Anal. Stereol., 42 (2023), 65–76. https://doi.org/10.5566/ias.2837 doi: 10.5566/ias.2837
|
| [34] |
J. M. Shapiro, Embedded image coding using zerotrees of wavelet coefficients, IEEE Trans. Signal Process., 41 (1993), 3445–3462. https://doi.org/10.1109/78.258085 doi: 10.1109/78.258085
|
| [35] | L. Rudin, P. L. Lions, S. Osher, Multiplicative denoising and deblurring: Theory and algorithms, In: Geometric level set methods in imaging, vision, and graphics, New York: Springer, 2003,103–119. https://doi.org/10.1007/0-387-21810-6_6 |








Figures(9) / Tables(5)

Donghong Zhao, Ruiying Huang, Li Feng. Proximity algorithms for the $ {\mathit{L}}^{1}{\mathit{L}}^{2}/{\mathit{T}\mathit{V}}^{\mathit{\alpha }} $ image denoising model[J]. AIMS Mathematics, 2024, 9(6): 16643-16665. doi: 10.3934/math.2024807







 DownLoad:
DownLoad: