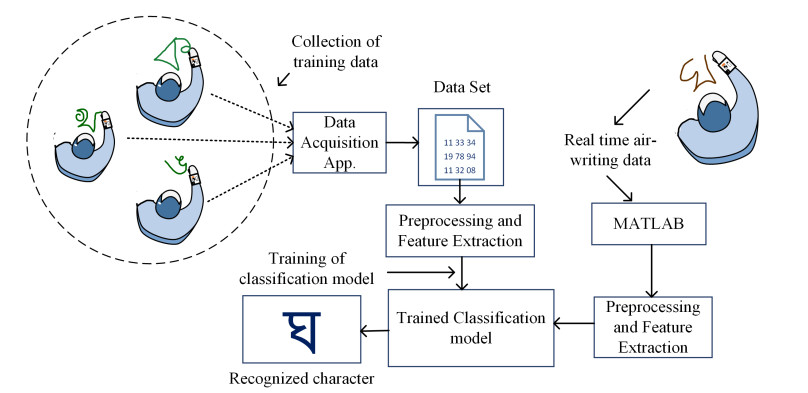
Air-writing is a widely used technique for writing arbitrary characters or numbers in the air. In this study, a data collection technique was developed to collect hand motion data for Bengali air-writing, and a motion sensor-based data set was prepared. The feature set as then utilized to determine the most effective machine learning (ML) model among the existing well-known supervised machine learning models to classify Bengali characters from air-written data. Our results showed that medium Gaussian SVM had the highest accuracy (96.5%) in the classification of Bengali character from air writing data. In addition, the proposed system achieved over 81% accuracy in real-time classification. The comparison with other studies showed that the existing supervised ML models predicted the created data set more accurately than many other models that have been suggested for other languages.
Citation: Mohammed Abdul Kader, Muhammad Ahsan Ullah, Md Saiful Islam, Fermín Ferriol Sánchez, Md Abdus Samad, Imran Ashraf. A real-time air-writing model to recognize Bengali characters[J]. AIMS Mathematics, 2024, 9(3): 6668-6698. doi: 10.3934/math.2024325
Air-writing is a widely used technique for writing arbitrary characters or numbers in the air. In this study, a data collection technique was developed to collect hand motion data for Bengali air-writing, and a motion sensor-based data set was prepared. The feature set as then utilized to determine the most effective machine learning (ML) model among the existing well-known supervised machine learning models to classify Bengali characters from air-written data. Our results showed that medium Gaussian SVM had the highest accuracy (96.5%) in the classification of Bengali character from air writing data. In addition, the proposed system achieved over 81% accuracy in real-time classification. The comparison with other studies showed that the existing supervised ML models predicted the created data set more accurately than many other models that have been suggested for other languages.

| [1] | A. Dash, A. Sahu, R. Shringi, J. Gamboa, M. Z. Afzal, M. I. Malik, et al., Airscript-creating documents in air, In: 2017 14th IAPR international conference on document analysis and recognition (ICDAR), 2017,908–913. https://doi.org/10.1109/ICDAR.2017.153 |
| [2] | X. Lin, Y. Chen, X. Chang, X. Liu, X. Wang, Show: Smart handwriting on watches, In: Proceedings of the ACM on interactive, mobile, wearable and ubiquitous technologies, 1 (2018), 151. https://doi.org/10.1145/3161412 |
| [3] | The Bengali language and the history of its evolution, LingoStar, 2021. Available from: https://lingo-star.com/bengali-language/?v = 4326ce96e26c. |
| [4] |
M. S. Alam, K. C. Kwon, M. A. Alam, M. Y. Abbass, S. M. Imtiaz, N. Kim, Trajectory-based air-writing recognition using deep neural network and depth sensor, Sensors, 20 (2020), 376. https://doi.org/10.3390/s20020376 doi: 10.3390/s20020376

|
| [5] | O. De, P. Deb, S. Mukherjee, S. Nandy, T. Chakraborty, S. Saha, Computer vision based framework for digit recognition by hand gesture analysis, In: 2016 IEEE 7th annual information technology, electronics and mobile communication conference (IEMCON), 2016. https://doi.org/10.1109/IEMCON.2016.7746361 |
| [6] |
S. Poularakis, I. Katsavounidis, Low-complexity hand gesture recognition system for continuous streams of digits and letters, IEEE T. Cybernetics, 46 (2016), 2094–2108. https://doi.org/10.1109/TCYB.2015.2464195 doi: 10.1109/TCYB.2015.2464195
|
| [7] | C. Qu, D. Zhang, J. Tian, Online kinect handwritten digit recognition based on dynamic time warping and support vector machine, J. Inform. Comput. Sci., 12 (2015), 413–422. |
| [8] |
S. Mohammadi, R. Maleki, Air-writing recognition system for Persian numbers with a novel classifier, The Visual Comput., 36 (2020), 1001–1015. https://doi.org/10.1007/s00371-019-01717-3 doi: 10.1007/s00371-019-01717-3
|
| [9] | P. Kumar, R. Saini, S. K. Behera, D. P. Dogra, P. P. Roy, Real-time recognition of sign language gestures and air-writing using leap motion, In: 2017 fifteenth IAPR international conference on machine vision applications (MVA), 2017. https://doi.org/10.23919/MVA.2017.7986825 |
| [10] |
P. Kumar, R. Saini, P. P. Roy, D. P. Dogra, Study of text segmentation and recognition using leap motion sensor. IEEE Sens. J., 17 (2017), 1293–1301. https://doi.org/10.1109/JSEN.2016.2643165 doi: 10.1109/JSEN.2016.2643165
|
| [11] |
X. Qu, W. Wang, K. Lu, J. Zhou, Data augmentation and directional feature maps extraction for in-air handwritten Chinese character recognition based on convolutional neural network, Pattern Recogn. Lett., 111 (2018), 9–15. https://doi.org/10.1016/j.patrec.2018.04.001 doi: 10.1016/j.patrec.2018.04.001
|
| [12] |
J. Gan, W. Wang, K. Lu, In-air handwritten Chinese text recognition with temporal convolutional recurrent network, Pattern Recogn., 97 (2020) 107025. https://doi.org/10.1016/j.patcog.2019.107025 doi: 10.1016/j.patcog.2019.107025
|
| [13] |
P. Wang, J. Lin, F. Wang, J. Xiu, Y. Lin, N. Yan, et al., A gesture air-writing tracking method that uses 24 GHz SIMO radar SoC, IEEE Access, 8 (2020), 152728–152741. https://doi.org/10.1109/ACCESS.2020.3017869 doi: 10.1109/ACCESS.2020.3017869
|
| [14] | M. Arsalan, A. Santra, K. Bierzynski, V. Issakov, Air-writing with sparse network of radars using spatio-temporal learning, In: 2020 25th international conference on pattern recognition (ICPR), 2021. https://doi.org/10.1109/ICPR48806.2021.9413332 |
| [15] |
F. Khan, S. K. Leem, S. H. Cho, In-air continuous writing using UWB impulse radar sensors, IEEE Access, 8 (2020), 99302–99311. https://doi.org/10.1109/ACCESS.2020.2994281 doi: 10.1109/ACCESS.2020.2994281
|
| [16] |
M. K. Chakravarthi, R. K. Tiwari, S. Handa, Accelerometer based static gesture recognition and mobile monitoring system using neural networks, Procedia Comput. Sci., 70 (2015), 683–687. https://doi.org/10.1016/j.procs.2015.10.105 doi: 10.1016/j.procs.2015.10.105
|
| [17] |
Y. Yin, L. Xie, T. Gu, Y. Lu, S. Lu, AirContour: Building contour-based model for in-air writing gesture recognition, ACM T. Sensor. Network, 15 (2019), 44. https://doi.org/10.1145/3343855 doi: 10.1145/3343855
|
| [18] | S. Xu, Y. Xue, Air-writing characters modelling and recognition on modified CHMM, In: 2016 IEEE international conference on systems, man, and cybernetics (SMC), 2016. https://doi.org/10.1109/SMC.2016.7844452 |
| [19] |
J. S. Wang, F. C. Chuang, An accelerometer-based digital pen with a trajectory recognition algorithm for handwritten digit and gesture recognition, IEEE T. Ind. Electron., 59 (2012), 2998–3007. https://doi.org/10.1109/TIE.2011.2167895 doi: 10.1109/TIE.2011.2167895
|
| [20] | P. Roy, S. Ghosh, U. Pal, A CNN based framework for unistroke numeral recognition in air-writing, In: 2018 16th international conference on frontiers in handwriting recognition (ICFHR), 2018. https://doi.org/10.1109/ICFHR-2018.2018.00077 |
| [21] | Coursera, Data processing and feature engineering with MATLAB, Available form: https://www.coursera.org/learn/feature-engineering-matlab. |
| [22] | Entropy calculation, information gain & decision tree learning, 2020. Available form: https://medium.com/analytics-vidhya/entropy-calculation-information-gain-decision-tree-learning-771325d16f |
| [23] | T. Giannakopoulos, A. Pikrakis, Introduction to audio analysis: A MATLAB® approach, 1st Eds, Cambridge, Massachusetts, US: Academic Press, 2014. |
| [24] | E. Scheirer, M. Slaney, Construction and evaluation of a robust multifeature speech/music discriminator, In: 1997 IEEE international conference on acoustics, speech, and signal processing, 1997. https://doi.org/10.1109/ICASSP.1997.596192 |
| [25] | M. Müller, Fundamentals of music processing: Audio, analysis, algorithms, applications, Springer Cham, 2015. https://doi.org/10.1007/978-3-319-21945-5 |
| [26] | M. A. Kader, M. A. Ullah, M. S. Islam, A real-time classification model for Bengali character recognition in air-writing, In: Computer vision and image analysis for industry 4.0, 1st Eds, Chapman and Hall/CRC, 2023. |
| [27] | Javatpoint, Regression vs. classification in machine learning, Available from https://www.javatpoint.com/regression-vs-classification-in-machine-learning. |
| [28] | A. Burkov, The hundred-page machine learning book, 1st Eds, Quebec City, QC, Canada: Andriy Burkov, 2019. |
| [29] | M. Mohammed, M. B. Khan, E. B. M. Bashier, Machine learning: Algorithms and applications, 1st Eds, Boca Raton: CRC Press, 2016. https://doi.org/10.1201/9781315371658 |
| [30] | B. Dickson, Machine learning: What is dimensionality reduction? 2021. Available from: https://bdtechtalks.com/2021/05/13/machine-learning-dimensionality-reduction/. |
| [31] |
S. Mukherjee, S. A. Ahmed, D. P. Dogra, S. Kar, P. P. Roy, Fingertip detection and tracking for recognition of air-writing in videos, Expert Syst. Appl., 136 (2019), 217–229. https://doi.org/10.1016/j.eswa.2019.06.034 doi: 10.1016/j.eswa.2019.06.034
|
| [32] | V. Joseph, A. Talpade, N. Suvarna, Z. Mendonca, Visual gesture recognition for text writing in air, In: 2018 second international conference on intelligent computing and control systems (ICICCS), 2018. https://doi.org/10.1109/ICCONS.2018.8663176 |
| [33] |
J. Gan, W. Wang, K. Lu, A new perspective: Recognizing online handwritten Chinese characters via 1-dimensional CNN, Inform. Sci., 478 (2019), 375–390. https://doi.org/10.1016/j.ins.2018.11.035 doi: 10.1016/j.ins.2018.11.035
|
| [34] | S. Hayakawa I. Goncharenko, Y. Gu, Air writing in Japanese: A CNN-based character recognition system using hand tracking, In: 2022 IEEE 4th global conference on life sciences and technologies (LifeTech), 2022. https://doi.org/10.1109/LifeTech53646.2022.9754825 |
| [35] | C. Wang C. Y. Su, C. L. Lin, A novel recognition system for digits writing in the air using coordinated path ordering, In: HotMobile '15: Proceedings of the 16th international workshop on mobile computing systems and applications, 2015, 9–14. https://doi.org/10.1109/ICIIBMS.2015.7439500 |
| [36] | C. Xu, P. H. Pathak, P. Mohapatra, Finger-writing with smartwatch: A case for finger and hand gesture recognition using smartwatch, In: Proceedings of the 16th International Workshop on Mobile Computing Systems and Applications, 2015, 9-14. https://doi.org/10.1145/2699343.2699350 |
| [37] | Y. Luo, J. Liu, S. Shimamoto, Wearable air-writing recognition system employing dynamic time warping, In: 2021 IEEE 18th annual consumer communications & networking conference (CCNC), 2021. https://doi.org/10.1109/CCNC49032.2021.9369458 |
| [38] |
Z. Fu, J. Xu, Z. Zhu, A. X. Liu, X. Sun, Writing in the air with WiFi signals for virtual reality devices IEEE T. Mobile Comput., 18 (2019), 473–484. https://doi.org/10.1109/TMC.2018.2831709 doi: 10.1109/TMC.2018.2831709
|
| [39] |
P. Kumar, R. Saini, P. P. Roy, U. Pal, A lexicon-free approach for 3D handwriting recognition using classifier combination, Pattern Recogn. Lett., 103 (2018), 1–7. https://doi.org/10.1016/j.patrec.2017.12.014 doi: 10.1016/j.patrec.2017.12.014
|





















Figures(22) / Tables(5)

Mohammed Abdul Kader, Muhammad Ahsan Ullah, Md Saiful Islam, Fermín Ferriol Sánchez, Md Abdus Samad, Imran Ashraf. A real-time air-writing model to recognize Bengali characters[J]. AIMS Mathematics, 2024, 9(3): 6668-6698. doi: 10.3934/math.2024325








 DownLoad:
DownLoad: