Total variation (TV) regularization is a powerful tool in image denoising, but it often exhibits limited performance in preserving edges. In contrast, non-convex TV regularization can more effectively preserve edges and contours, albeit posing challenges when solving. Recently, the convex non-convex (CNC) strategy has emerged as a potent approach that allows incorporating non-convex TV regularization terms while maintaining the overall convexity of the objective function. Its superior performance has been validated through various numerical experiments; however, theoretical analysis remains lacking. In this paper, we provided theoretical analysis of the performance of the CNC-TV denoising model. By utilizing the oracle inequality, we derived an improved upper bound on its performance compared to TV regularization. In addition, we devised an alternating direction method of multipliers (ADMM) algorithm to address the proposed model and verified its convergence properties. Our proposed model has been validated through numerical experiments in 1D and 2D denoising, demonstrating its exceptional performance.
Citation: Yating Zhu, Zixun Zeng, Zhong Chen, Deqiang Zhou, Jian Zou. Performance analysis of the convex non-convex total variation denoising model[J]. AIMS Mathematics, 2024, 9(10): 29031-29052. doi: 10.3934/math.20241409
Total variation (TV) regularization is a powerful tool in image denoising, but it often exhibits limited performance in preserving edges. In contrast, non-convex TV regularization can more effectively preserve edges and contours, albeit posing challenges when solving. Recently, the convex non-convex (CNC) strategy has emerged as a potent approach that allows incorporating non-convex TV regularization terms while maintaining the overall convexity of the objective function. Its superior performance has been validated through various numerical experiments; however, theoretical analysis remains lacking. In this paper, we provided theoretical analysis of the performance of the CNC-TV denoising model. By utilizing the oracle inequality, we derived an improved upper bound on its performance compared to TV regularization. In addition, we devised an alternating direction method of multipliers (ADMM) algorithm to address the proposed model and verified its convergence properties. Our proposed model has been validated through numerical experiments in 1D and 2D denoising, demonstrating its exceptional performance.

| [1] |
M. Elad, B. Kawar, G. Vaksman, Image denoising: the deep learning revolution and beyond–a survey paper, SIAM J. Imaging Sci., 16 (2023), 1594–1654. https://doi.org/10.1137/23M1545859 doi: 10.1137/23M1545859

|
| [2] |
L. I. Rudin, S. Osher, E. Fatemi, Nonlinear total variation based noise removal algorithms, Phys. D, 60 (1992), 259–268. https://doi.org/10.1016/0167-2789(92)90242-F doi: 10.1016/0167-2789(92)90242-F
|
| [3] | A. Chambolle, V. Caselles, D. Cremers, M. Novaga, T. Pock, An introduction to total variation for image analysis, In: Theoretical foundations and numerical methods for sparse recovery, Berlin, New York: De Gruyter, 2010,263–340. https://doi.org/10.1515/9783110226157.263 |
| [4] | M. Burger, S. Osher, A guide to the TV zoo, In: Level set and PDE based reconstruction methods in imaging, Cham: Springer, 2013, 1–70. https://doi.org/10.1007/978-3-319-01712-9_1 |
| [5] |
M. Pragliola, L. Calatroni, A. Lanza, F. Sgallari, On and beyond total variation regularization in imaging: the role of space variance, SIAM Rev., 65 (2023), 601–685. https://doi.org/10.48550/arXiv.2104.03650 doi: 10.48550/arXiv.2104.03650
|
| [6] |
D. H. Zhao, R. Y. Huang, L. Feng, Proximity algorithms for the $L^1L^2/TV^{\alpha}$ image denoising model, AIMS Math., 9 (2024), 16643–16665. https://doi.org/10.3934/math.2024807 doi: 10.3934/math.2024807
|
| [7] |
A. Ben-loghfyry, A. Hakim, A bilevel optimization problem with deep learning based on fractional total variation for image denoising, Multimed. Tools Appl., 83 (2024), 28595–28614. https://doi.org/10.1007/s11042-023-16583-4 doi: 10.1007/s11042-023-16583-4
|
| [8] |
A. Lanza, S. Morigi, F. Sgallari, Convex image denoising via non-convex regularization with parameter selection, J. Math. Imaging Vis., 56 (2016), 195–220. https://doi.org/10.1007/s10851-016-0655-7 doi: 10.1007/s10851-016-0655-7
|
| [9] |
I. Selesnick, A. Lanza, S. Morigi, F. Sgallari, Non-convex total variation regularization for convex denoising of signals, J. Math. Imaging Vis., 62 (2020), 825–841. https://doi.org/10.1007/s10851-019-00937-5 doi: 10.1007/s10851-019-00937-5
|
| [10] |
M. Kang, M. Jung, Nonconvex fractional order total variation based image denoising model under mixed stripe and Gaussian noise, AIMS Math., 9 (2024), 21094–21124. https://doi.org/10.3934/math.20241025 doi: 10.3934/math.20241025
|
| [11] |
I. W. Selesnick, A. Parekh, I. Bayram, Convex 1-D total variation denoising with non-convex regularization, IEEE Signal Process. Lett., 22 (2015), 141–144. https://doi.org/10.1109/LSP.2014.2349356 doi: 10.1109/LSP.2014.2349356
|
| [12] |
J. Darbon, M. Sigelle, Image restoration with discrete constrained total variation part Ⅱ: Levelable functions, convex priors and non-convex cases, J. Math. Imaging Vis., 26 (2006), 277–291. https://doi.org/10.1007/s10851-006-0644-3 doi: 10.1007/s10851-006-0644-3
|
| [13] |
H. L. Zhang, L. M. Tang, Z. Fang, C. C. Xiang, C. Y. Li, Nonconvex and nonsmooth total generalized variation model for image restoration, Signal Process., 143 (2018), 69–85. https://doi.org/10.1016/j.sigpro.2017.08.021 doi: 10.1016/j.sigpro.2017.08.021
|
| [14] |
M. Hintermüller, T. Wu, Nonconvex TV$^q$-models in image restoration: analysis and a trust-region regularization–based superlinearly convergent solver, SIAM J. Imaging Sci., 6 (2013), 1385–1415. https://doi.org/10.1137/110854746 doi: 10.1137/110854746
|
| [15] |
Z. Fang, L. M. Tang, L. Wu, H. X. Liu, A nonconvex TV$_q$- $l_1$ regularization model and the ADMM based algorithm, Sci. Rep., 12 (2022), 7942. https://doi.org/10.1038/s41598-022-11938-7 doi: 10.1038/s41598-022-11938-7
|
| [16] |
A. Lanza, S. Morigi, I. W. Selesnick, F. Sgallari, Sparsity-inducing nonconvex nonseparable regularization for convex image processing, SIAM J. Imaging Sci., 12 (2019), 1099–1134. https://doi.org/10.1137/18M1199149 doi: 10.1137/18M1199149
|
| [17] | A. Lanza, S. Morigi, I. W. Selesnick, F. Sgallari, Convex non-convex variational models, In: Handbook of mathematical models and algorithms in computer vision and imaging: mathematical imaging and vision, Cham: Springer, 2023, 3–59. https://doi.org/10.1007/978-3-030-98661-2_61 |
| [18] |
Y. L. Liu, H. Q. Du, Z. X. Wang, W. B. Mei, Convex MR brain image reconstruction via non-convex total variation minimization, Int. J. Imaging Syst. Technol., 28 (2018), 246–253. https://doi.org/10.1002/ima.22275 doi: 10.1002/ima.22275
|
| [19] |
M. R. Shen, J. C. Li, T. Zhang, J. Zou, Magnetic resonance imaging reconstruction via non-convex total variation regularization, Int. J. Imaging Syst. Technol., 31 (2021), 412–424. https://doi.org/10.1002/ima.22463 doi: 10.1002/ima.22463
|
| [20] |
J. L. Li, Z. Y. Xie, G. Q. Liu, L. Yang, J. Zou, Diffusion optical tomography reconstruction based on convex-nonconvex graph total variation regularization, Math. Methods Appl. Sci., 46 (2023), 4534–4545. https://doi.org/10.1002/mma.8777 doi: 10.1002/mma.8777
|
| [21] | Q. Li, A comprehensive survey of sparse regularization: fundamental, state-of-the-art methodologies and applications on fault diagnosis, Expert Syst. Appl., 229 (2023), 120517. |
| [22] |
H. B. Lin, F. T. Wu, G. L. He, Rolling bearing fault diagnosis using impulse feature enhancement and nonconvex regularization, Mech. Syst. Signal Process., 142 (2020), 106790. https://doi.org/10.1016/j.ymssp.2020.106790 doi: 10.1016/j.ymssp.2020.106790
|
| [23] |
J. P. Wang, G. L. Xu, C. L. Li, Z. S. Wang, F. J. Yan, Surface defects detection using non-convex total variation regularized RPCA with kernelization, IEEE Trans. Instrum. Meas., 70 (2021), 1–13. https://doi.org/10.1109/TIM.2021.3056738 doi: 10.1109/TIM.2021.3056738
|
| [24] |
T. H. Wen, Z. Chen, T. Zhang, J. Zou, Graph-based semi-supervised learning with non-convex graph total variation regularization, Expert Syst. Appl., 255 (2024), 124709. https://doi.org/10.1016/j.eswa.2024.124709 doi: 10.1016/j.eswa.2024.124709
|
| [25] | G. Scrivanti, É. Chouzenoux, J. C. Pesquet, A CNC approach for directional total variation, In: 2022 30th European Signal Processing Conference (EUSIPCO), 488–492. https://doi.org/10.23919/EUSIPCO55093.2022.9909763 |
| [26] |
H. Q. Du, Y. L. Liu, Minmax-concave total variation denoising, Signal Image Video Process., 12 (2018), 1027–1034. https://doi.org/10.1007/s11760-018-1248-2 doi: 10.1007/s11760-018-1248-2
|
| [27] | J. C. Hütter, P. Rigollet, Optimal rates for total variation denoising, In: Conference on Learning Theory, 49 (2016), 1115–1146. |
| [28] |
J. Q. Fan, R. Z. Li, Variable selection via nonconcave penalized likelihood and its oracle properties, J. Amer. Statist. Assoc., 96 (2001), 1348–1360. https://doi.org/10.1198/016214501753382273 doi: 10.1198/016214501753382273
|
| [29] |
A. H. Al-Shabili, Y. Feng, I. Selesnick, Sharpening sparse regularizers via smoothing, IEEE Open J. Signal Process., 2 (2021), 396–409. https://doi.org/10.1109/OJSP.2021.3104497 doi: 10.1109/OJSP.2021.3104497
|
| [30] |
I. Selesnick, Sparse regularization via convex analysi, IEEE Trans. Signal Process., 65 (2017), 4481–4494. https://doi.org/10.1109/TSP.2017.2711501 doi: 10.1109/TSP.2017.2711501
|
| [31] |
E. Mammen, S. van de Geer, Locally adaptive regression splines, Ann. Statist., 25 (1997), 387–413. https://doi.org/10.1214/aos/1034276635 doi: 10.1214/aos/1034276635
|
| [32] |
D. Needell, R. Ward, Near-optimal compressed sensing guarantees for total variation minimization, IEEE. Trans. Image Process., 22 (2013), 3941–3949. https://doi.org/10.1109/TIP.2013.2264681 doi: 10.1109/TIP.2013.2264681
|
| [33] | Y. X. Wang, J. Sharpnack, A. J. Smola, R. J. Tibshirani, Trend filtering on graphs, J. Mach. Learn. Res., 17 (2016), 1–41. |
| [34] | V. Sadhanala, Y. X. Wang, R. J. Tibshirani, Total variation classes beyond 1d: minimax rates, and the limitations of linear smoothers, In: Advances in Neural Information Processing Systems 29 (NIPS 2016), 2016. |
| [35] |
S. Chatterjee, S. Goswami, New risk bounds for 2D total variation denoising, IEEE Trans. Inform. Theory, 67 (2021), 4060–4091. https://doi.org/10.1109/TIT.2021.3059657 doi: 10.1109/TIT.2021.3059657
|
| [36] |
R. Varma, H. Lee, J. Kovačević, Y. Chi, Vector-valued graph trend filtering with non-convex penalties, IEEE Trans. Signal Inform. Process. Netw., 6 (2020), 48–62. https://doi.org/10.1109/TSIPN.2019.2957717 doi: 10.1109/TSIPN.2019.2957717
|
| [37] |
A. Guntuboyina, D. Lieu, S. Chatterjee, B. Sen, Adaptive risk bounds in univariate total variation denoising and trend filtering, Ann. Statist., 48 (2020), 205–229. https://doi.org/10.1214/18-AOS1799 doi: 10.1214/18-AOS1799
|
| [38] | F. Ortelli, S. van de Geer, Adaptive rates for total variation image denoising, J. Mach. Learn. Res., 21 (2020), 1–38. |
| [39] |
F. Ortelli, S. van de Geer, Prediction bounds for higher order total variation regularized least squares, Ann. Statist., 49 (2021), 2755–2773. https://doi.org/10.1214/21-AOS2054 doi: 10.1214/21-AOS2054
|
| [40] | N. Parikh, S. Boyd, Proximal algorithms, Found. Trends Optim., 1 (2014), 127–239. https://doi.org/10.1561/2400000003 |
| [41] |
S. Boyd, N. Parikh, E. Chu, B. Peleato, J. Eckstein, Distributed optimization and statistical learning via the alternating direction method of multipliers, Found. Trends Mach. Learn., 3 (2011), 1–122. http://dx.doi.org/10.1561/2200000016 doi: 10.1561/2200000016
|
| [42] | S. Boucheron, G. Lugosi, P. Massart, Concentration inequalities: a nonasymptotic theory of independence, Oxford University Press, 2013. https://doi.org/10.1093/acprof:oso/9780199535255.001.0001 |
| [43] |
N. Kumar, M. Sonkar, G. Bhatnagar, Efficient image restoration via non-convex total variation regularization and ADMM optimization, Appl. Math. Model., 132 (2024), 428–453. https://doi.org/10.1016/j.apm.2024.04.055 doi: 10.1016/j.apm.2024.04.055
|
| [44] |
S. J. Ma, J. Huang, A concave pairwise fusion approach to subgroup analysis, J. Amer. Statist. Assoc., 112 (2017), 410–423. https://doi.org/10.1080/01621459.2016.1148039 doi: 10.1080/01621459.2016.1148039
|
| [45] |
P. Tseng, Convergence of a block coordinate descent method for nondifferentiable minimization, J. Optim. Theory Appl., 109 (2001), 475–494. https://doi.org/10.1023/A:1017501703105 doi: 10.1023/A:1017501703105
|
| [46] |
L. Condat, A direct algorithm for 1-D total variation denoising, IEEE Signal Process. Lett., 20 (2013), 1054–1057. https://doi.org/10.1109/LSP.2013.2278339 doi: 10.1109/LSP.2013.2278339
|
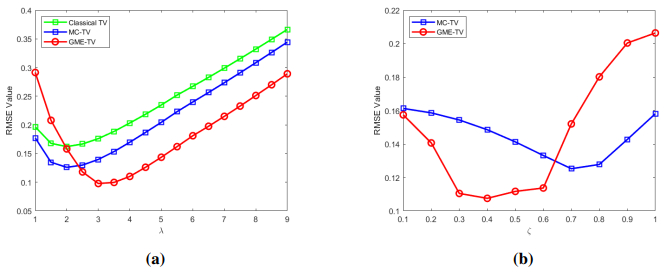





Figures(6)

Yating Zhu, Zixun Zeng, Zhong Chen, Deqiang Zhou, Jian Zou. Performance analysis of the convex non-convex total variation denoising model[J]. AIMS Mathematics, 2024, 9(10): 29031-29052. doi: 10.3934/math.20241409







 DownLoad:
DownLoad: