Citation: Abdelilah Hakim, Anouar Ben-Loghfyry. A total variable-order variation model for image denoising[J]. AIMS Mathematics, 2019, 4(5): 1320-1335. doi: 10.3934/math.2019.5.1320

| [1] |
R. Acar and C. R. Vogel, Analysis of bounded variation penalty methods for ill-posed problems, Inverse problems, 10 (1994), 1217-1229. doi: 10.1088/0266-5611/10/6/003

|
| [2] | B. Ahmad, M. Alghanmi, S. K. Ntouyas, et al. A study of fractional differential equations and inclusions involving generalized caputo-type derivative equipped with generalized fractional integral boundary conditions, Aims Press, 2018. |
| [3] |
J. Bai and X.-C. Feng, Fractional-order anisotropic diffusion for image denoising, IEEE T. Image Process., 16 (2007), 2492-2502. doi: 10.1109/TIP.2007.904971
|
| [4] |
A. Laghrib, A. Ben-loghfyry, A. Hadri, et al. A nonconvex fractional order variational model for multi-frame image super-resolution, Signal Process-Image, 67 (2018), 1-11. doi: 10.1016/j.image.2018.05.011
|
| [5] |
A. Chambolle and P.-L. Lions, Image recovery via total variation minimization and related problems, Numerische Mathematik, 76 (1997), 167-188. doi: 10.1007/s002110050258
|
| [6] | T. F. Chan, S. Esedoglu and F. Park, A fourth order dual method for staircase reduction in texture extraction and image restoration problems. In:2010 IEEE International Conference on Image Processing, (2010), 4137-4140. |
| [7] |
T. F. Chan, A. M. Yip and F. E. Park, Simultaneous total variation image inpainting and blind deconvolution, Int. J. Imag. Syst. Tech., 15 (2005), 92-102. doi: 10.1002/ima.20041
|
| [8] |
F. Dong and Y. Chen, A fractional-order derivative based variational framework for image denoising, Inverse Probl. Imag., 10 (2016), 27-50. doi: 10.3934/ipi.2016.10.27
|
| [9] |
C. Frohn-Schauf, S. Henn and K. Witsch, Multigrid based total variation image registration, Computing and Visualization in Science, 11 (2008), 101-113. doi: 10.1007/s00791-007-0060-2
|
| [10] |
P. Getreuer, Total variation inpainting using split bregman, Image Processing On Line, 2 (2012), 147-157. doi: 10.5201/ipol.2012.g-tvi
|
| [11] | S. N. Ghate, S. Achaliya and S. Raveendran, An algorithm of total variation for image inpainting, IJCER, 1 (2012), 124-130. |
| [12] | M. Macias and D. Sierociuk, An alternative recursive fractional variable-order derivative definition and its analog validation. In:ICFDA'14 International Conference on Fractional Differentiation and Its Applications, IEEE, 2014. |
| [13] | W. Malesza, M. Macias and D. Sierociuk, Matrix approach and analog modeling for solving fractional variable order differential equations. In:Advances in Modelling and Control of Noninteger-Order Systems, Springer, 2015. |
| [14] | P. Ostalczyk, Stability analysis of a discrete-time system with a variable-, fractional-order controller, B. Pol. Acad. Sci.-Tech., 58 (2010), 613-619. |
| [15] | D. C. Paquin, D. Levy and L. Xing, Multiscale image registration, Int. J. Radiat. Oncol., 66 (2006), S647. |
| [16] | I. Podlubny, Fractional differential equations:an introduction to fractional derivatives, fractional differential equations, to methods of their solution and some of their applications, Elsevier, 1998. |
| [17] |
C. Poschl and O. Scherzer, Characterization of minimizers of convex regularization functionals, Contemporary mathematics, 451 (2008), 219-248. doi: 10.1090/conm/451/08784
|
| [18] |
L. I. Rudin, S. Osher and E. Fatemi, Nonlinear total variation based noise removal algorithms, Physica D:nonlinear phenomena, 60 (1992), 259-268. doi: 10.1016/0167-2789(92)90242-F
|
| [19] |
D. Sierociuk, W. Malesza and M. Macias, On the recursive fractional variable-order derivative:equivalent switching strategy, duality, and analog modeling, Circ. Syst. Signal Pr., 34 (2015), 1077-1113. doi: 10.1007/s00034-014-9895-1
|
| [20] | D. Sierociuk and M. Twardy, Duality of variable fractional order difference operators and its application in identification, B. Pol. Acad. Sci.-Tech., 62 (2014), 809-815. |
| [21] |
J. Zhang and K. Chen, A total fractional-order variation model for image restoration with nonhomogeneous boundary conditions and its numerical solution, SIAM J. Imaging Sci., 8 (2015), 2487-2518. doi: 10.1137/14097121X
|
| [22] |
Z. Zhang, An undetermined time-dependent coefficient in a fractional diffusion equation, Inverse Probl. Imag., 11 (2017), 875-900. doi: 10.3934/ipi.2017041
|
| [23] | D. Zosso and A. Bustin, A primal-dual projected gradient algorithm for efficient beltrami regularization, Comput. Vis. Image Und., (2014), 14-52. |
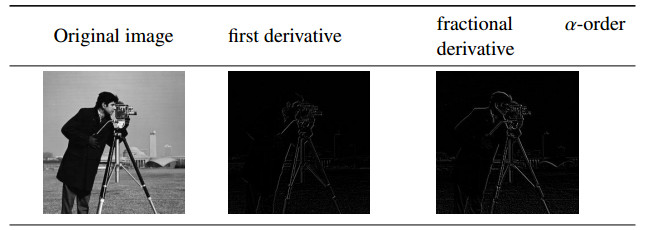

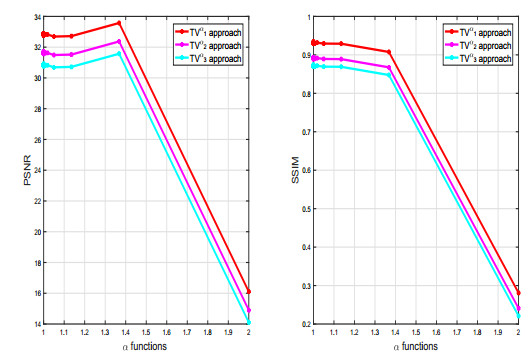




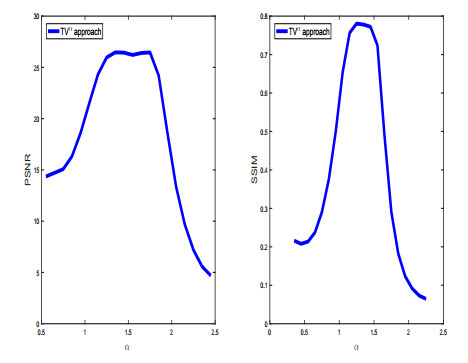
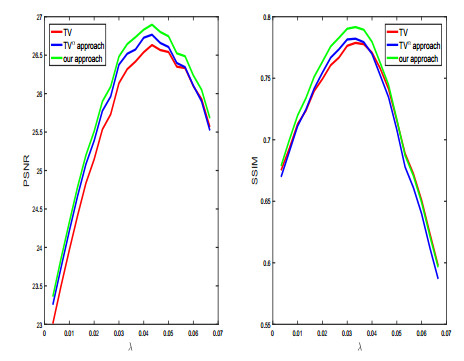
Figures(10) / Tables(2)

Abdelilah Hakim, Anouar Ben-Loghfyry. A total variable-order variation model for image denoising[J]. AIMS Mathematics, 2019, 4(5): 1320-1335. doi: 10.3934/math.2019.5.1320







 DownLoad:
DownLoad: