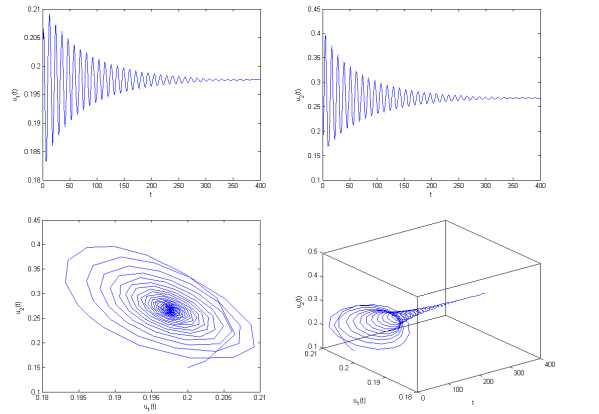
Recently, delayed dynamical model has witnessed a great interest from many scholars in biological and mathematical areas due to its potential application in describing the interaction of different biological populations. In this article, relying the previous studies, we set up two new predator-prey systems incorporating delay. By virtue of fixed point theory, inequality tactics and an appropriate function, we explore well-posedness (includes existence and uniqueness, boundedness and non-negativeness) of the solution of the two formulated delayed predator-prey systems. With the aid of bifurcation theorem and stability theory of delayed differential equations, we gain the parameter conditions on the emergence of stability and bifurcation phenomenon of the two formulated delayed predator-prey systems. By applying two controllers (hybrid controller and extended delayed feedback controller) we can efficaciously regulate the region of stability and the time of occurrence of bifurcation phenomenon for the two delayed predator-prey systems. The effect of delay on stabilizing the system and adjusting bifurcation is investigated. Computer simulation plots are provided to sustain the acquired prime outcomes. The conclusions of this article are completely new and can provide some momentous instructions in dominating and balancing the densities of predator and prey.
Citation: Wei Ou, Changjin Xu, Qingyi Cui, Yicheng Pang, Zixin Liu, Jianwei Shen, Muhammad Zafarullah Baber, Muhammad Farman, Shabir Ahmad. Hopf bifurcation exploration and control technique in a predator-prey system incorporating delay[J]. AIMS Mathematics, 2024, 9(1): 1622-1651. doi: 10.3934/math.2024080
Recently, delayed dynamical model has witnessed a great interest from many scholars in biological and mathematical areas due to its potential application in describing the interaction of different biological populations. In this article, relying the previous studies, we set up two new predator-prey systems incorporating delay. By virtue of fixed point theory, inequality tactics and an appropriate function, we explore well-posedness (includes existence and uniqueness, boundedness and non-negativeness) of the solution of the two formulated delayed predator-prey systems. With the aid of bifurcation theorem and stability theory of delayed differential equations, we gain the parameter conditions on the emergence of stability and bifurcation phenomenon of the two formulated delayed predator-prey systems. By applying two controllers (hybrid controller and extended delayed feedback controller) we can efficaciously regulate the region of stability and the time of occurrence of bifurcation phenomenon for the two delayed predator-prey systems. The effect of delay on stabilizing the system and adjusting bifurcation is investigated. Computer simulation plots are provided to sustain the acquired prime outcomes. The conclusions of this article are completely new and can provide some momentous instructions in dominating and balancing the densities of predator and prey.

| [1] |
E. Balc, Predation fear and its carry-over effect in a fractional order prey-predator model with prey refuge, Chaos Soliton. Fract., 175 (2023), 114016. https://doi.org/10.1016/j.chaos.2023.114016 doi: 10.1016/j.chaos.2023.114016

|
| [2] |
S. Pandey, U. Ghosh, D. Das, S. Chakraborty, A. Sarkar, Rich dynamics of a delay-induced stage-structure prey-predator model with cooperative behaviour in both species and the impact of prey refuge, Math. Comput. Simulat., 216 (2024), 49–76. https://doi.org/10.1016/j.matcom.2023.09.002 doi: 10.1016/j.matcom.2023.09.002
|
| [3] |
F. Rao, Y. Kang, Dynamics of a stochastic prey-predator system with prey refuge, predation fear and its carry-over effects, Chaos Soliton. Fract., 175 (2023), 113935. https://doi.org/10.1016/j.chaos.2023.113935 doi: 10.1016/j.chaos.2023.113935
|
| [4] |
K. Sarkar, S. Khajanchi, Spatiotemporal dynamics of a predator-prey system with fear effect, J. Franklin Inst., 360 (2023), 7380–7414. https://doi.org/10.1016/j.jfranklin.2023.05.034 doi: 10.1016/j.jfranklin.2023.05.034
|
| [5] |
J. L. Xiao, Y. H. Xia, Spatiotemporal dynamics in a diffusive predator-prey model with multiple Allee effect and herd behavior, J. Math. Anal. Appl., 529 (2024), 127569. https://doi.org/10.1016/j.jmaa.2023.127569 doi: 10.1016/j.jmaa.2023.127569
|
| [6] |
P. Mishra, D. Wrzosek, Pursuit-evasion dynamics for Bazykin-type predator-prey model with indirect predator taxis, J. Diff. Equat., 361 (2023), 391–416. https://doi.org/10.1016/j.jde.2023.02.063 doi: 10.1016/j.jde.2023.02.063
|
| [7] |
W. Choi, K. Kim, I. Ahn, Predator-prey models with prey-dependent diffusion on predators in spatially heterogeneous habitat, J. Math. Anal. Appl., 525 (2023), 127130. https://doi.org/10.1016/j.jmaa.2023.127130 doi: 10.1016/j.jmaa.2023.127130
|
| [8] |
Q. Li, Y. Y Zhang, Y. N. Xiao, Canard phenomena for a slow-fast predator-prey system with group defense of the prey, J. Math. Anal. Appl., 527 (2023), 127418. https://doi.org/10.1016/j.jmaa.2023.127418 doi: 10.1016/j.jmaa.2023.127418
|
| [9] |
D. Sen, S. Petrovskii, S. Ghorai, M. Banerjee, Rich bifurcation structure of prey-predator model induced by the Allee effect in the growth of generalist predator, Int. J. Bifurcat. Chaos, 30 (2020), 2050084. https://doi.org/10.1142/S0218127420500844 doi: 10.1142/S0218127420500844
|
| [10] |
S. Dey, M. Banerjee, S. Ghorai, Analytical detection of stationary turing pattern in a predator-prey system with generalist predator, Math. Model. Nat. Phenom., 17 (2022), 33. https://doi.org/10.1051/mmnp/2022032 doi: 10.1051/mmnp/2022032
|
| [11] |
J. Roy, M. Banerjee, Global stability of a predator-prey model with generalist predator, Appl. Math. Lett., 142 (2023), 108659. https://doi.org/10.1016/j.aml.2023.108659 doi: 10.1016/j.aml.2023.108659
|
| [12] |
R. Xu. Global stability and Hopf bifurcation of a predator-prey model with stage structure and delayed predator response, Nonlinear Dynam., 67 (2012), 1683–1693. https://doi.org/10.1007/s11071-011-0096-1 doi: 10.1007/s11071-011-0096-1
|
| [13] |
C. J. Xu, D. Mu, Z. X. Liu, Y. C. Pang, C. Aouiti, O. Tunc, et al., Bifurcation dynamics and control mechanism of a fractional-order delayed Brusselator chemical reaction model, MATCH-Commun. Math. Co., 89 (2023), 73–106. https://doi.org/10.46793/match.89-1.073X doi: 10.46793/match.89-1.073X
|
| [14] |
C. J. Xu, C. Aouiti, Z. X. Liu, P. L. Li, L. Y. Yao, Bifurcation caused by delay in a fractional-order coupled Oregonator model in chemistry, MATCH-Commun. Math. Co., 88 (2022), 371–396. https://doi.org/10.46793/match.88-2.371X doi: 10.46793/match.88-2.371X
|
| [15] |
C. J. Xu, W. Zhang, C. Aouiti, Z. X. Liu, P. L. Li, L. Y. Yao, Bifurcation dynamics in a fractional-order Oregonator model including time delay, MATCH-Commun. Math. Co., 87 (2022), 397–414. https://doi.org/10.46793/match.87-2.397X doi: 10.46793/match.87-2.397X
|
| [16] |
Q. Y. Cui, C. J. Xu, W. Ou, Y. C. Pang, Z. X. Liu, P. L. Li, et al., Bifurcation behavior and hybrid controller design of a 2D Lotka-Volterra commensal symbiosis system accompanying delay, Mathematics, 11 (2023), 4808. https://doi.org/10.3390/math11234808 doi: 10.3390/math11234808
|
| [17] |
C. J. Xu, X. H. Cui, P. L. Li, J. L. Yan, L. Y. Yao, Exploration on dynamics in a discrete predator-prey competitive model involving feedback controls, J. Biol. Dynam., 17 (2023), 2220349. https://doi.org/10.1080/17513758.2023.2220349 doi: 10.1080/17513758.2023.2220349
|
| [18] |
D. Mu, C. J. Xu, Z. X. Liu, Y. C. Pang, Further insight into bifurcation and hybrid control tactics of a chlorine dioxide-iodine-malonic acid chemical reaction model incorporating delays, MATCH Commun. Math. Comput. Chem., 89 (2023), 529–566. https://doi.org/10.46793/match.89-3.529M doi: 10.46793/match.89-3.529M
|
| [19] |
P. L. Li, X. Q. Peng, C. J. Xu, L. Q. Han, S. R. Shi, Novel extended mixed controller design for bifurcation control of fractional-order Myc/E2F/miR-17-92 network model concerning delay, Math. Method. Appl. Sci., 46 (2023), 18878–18898. https://doi.org/10.1002/mma.9597 doi: 10.1002/mma.9597
|
| [20] |
P. L. Li, R. Gao, C. J. Xu, J. W. Shen, S. Ahmad, Y. Li, Exploring the impact of delay on Hopf bifurcation of a type of BAM neural network models concerning three nonidentical delays, Neural Process Lett., 55 (2023), 11595–11635. https://doi.org/10.1007/s11063-023-11392-0 doi: 10.1007/s11063-023-11392-0
|
| [21] |
S. Li, C. D. Huang, X. Y. Song, Detection of Hopf bifurcations induced by pregnancy and maturation delays in a spatial predator-prey model via crossing curves method, Chaos Soliton. Fract., 175 (2023), 114012. https://doi.org/10.1016/j.chaos.2023.114012 doi: 10.1016/j.chaos.2023.114012
|
| [22] |
X. Z. Feng, X. Liu, C. Sun, Y. L. Jiang, Stability and Hopf bifurcation of a modified Leslie-Gower predator-prey model with Smith growth rate and B-D functional response, Chaos Soliton. Fract., 174 (2023), 113794. https://doi.org/10.1016/j.chaos.2023.113794 doi: 10.1016/j.chaos.2023.113794
|
| [23] | Z. Z. Zhang, H. Z. Yang, Hybrid control of Hopf bifurcation in a two prey one predator system with time delay, In: Proceeding of the 33rd Chinese Control Conference, IEEE, Nanjing, China, 2014, 6895–6900. https://doi.org/10.1109/chicc.2014.6896136 |
| [24] |
L. P. Zhang, H. N. Wang, M. Xu, Hybrid control of bifurcation in a predator-prey system with three delays, Acta Phys. Sin., 60 (2011), 010506. https://doi.org/10.7498/aps.60.010506 doi: 10.7498/aps.60.010506
|
| [25] |
Z. Liu, K. W. Chuang, Hybrid control of bifurcation in continuous nonlinear dynamical systems, Int. J. Bifurcat. Chaos, 15 (2005), 1895–3903. https://doi.org/10.1142/S0218127405014374 doi: 10.1142/S0218127405014374
|
| [26] |
J. Alidousti, Stability and bifurcation analysis for a fractional prey-predator scavenger model, Appl. Math. Model., 81 (2020), 342–355. https://doi.org/10.1016/j.apm.2019.11.025 doi: 10.1016/j.apm.2019.11.025
|
| [27] |
W. G. Zhou, C. D. Huang, M. Xiao, J. D. Cao, Hybrid tactics for bifurcation control in a fractional-order delayed predator-prey model, Physica A, 515 (2019), 183–191. https://doi.org/10.1016/j.physa.2018.09.185 doi: 10.1016/j.physa.2018.09.185
|
| [28] |
Y. Q. Zhang, P. L. Li, C. J. Xu, X. Q. Peng, R. Qiao, Investigating the effects of a fractional operator on the evolution of the ENSO model: Bifurcations, stability and numerical analysis, Fractal Fract., 7 (2023), 602. https://doi.org/10.3390/fractalfract7080602 doi: 10.3390/fractalfract7080602
|
| [29] |
P. L. Li, Y. J. Lu, C. J. Xu, J. Ren, Insight into Hopf bifurcation and control methods in fractional order BAM neural networks incorporating symmetric structure and delay, Cogn. Comput., 15 (2023), 1825–1867. https://doi.org/10.1007/s12559-023-10155-2 doi: 10.1007/s12559-023-10155-2
|
| [30] |
C. J. Xu, M. Farman, Dynamical transmission and mathematical analysis of Ebola virus using a constant proportional operator with a power law kernel, Fractals Fract., 7 (2023), 706. https://doi.org/10.3390/fractalfract7100706 doi: 10.3390/fractalfract7100706
|
| [31] |
C. J. Xu, Y. Y. Zhao, J. T. Lin, Y. C. Pang, Z. X. Liu, J. W. Shen, et al., Mathematical exploration on control of bifurcation for a plankton-oxygen dynamical model owning delay, J. Math. Chem., 2023, 1–31. https://doi.org/10.1007/s10910-023-01543-y doi: 10.1007/s10910-023-01543-y
|







Figures(8)

Wei Ou, Changjin Xu, Qingyi Cui, Yicheng Pang, Zixin Liu, Jianwei Shen, Muhammad Zafarullah Baber, Muhammad Farman, Shabir Ahmad. Hopf bifurcation exploration and control technique in a predator-prey system incorporating delay[J]. AIMS Mathematics, 2024, 9(1): 1622-1651. doi: 10.3934/math.2024080







 DownLoad:
DownLoad: