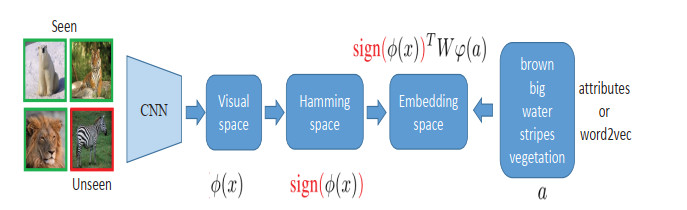
Approximate nearest neighbor (ANN) search has become an essential paradigm for large-scale image retrieval. Conventional ANN search requires the categories of query images to been seen in the training set. However, facing the rapid evolution of newly-emerging concepts on the web, it is too expensive to retrain the model via collecting labeled data with the new (unseen) concepts. Existing zero-shot hashing methods choose the semantic space or intermediate space as the embedding space, which ignore the inconsistency of visual space and semantic space and suffer from the hubness problem on the zero-shot image retrieval task. In this paper, we present an novel deep quantization network with visual-semantic alignment for efficient zero-shot image retrieval. Specifically, we adopt a multi-task architecture that is capable of $ 1) $ learning discriminative and polymeric image representations for facilitating the visual-semantic alignment; $ 2) $ learning discriminative semantic embeddings for knowledge transfer; and $ 3) $ learning compact binary codes for aligning the visual space and the semantic space. We compare the proposed method with several state-of-the-art methods on several benchmark datasets, and the experimental results validate the superiority of the proposed method.
Citation: Huixia Liu, Zhihong Qin. Deep quantization network with visual-semantic alignment for zero-shot image retrieval[J]. Electronic Research Archive, 2023, 31(7): 4232-4247. doi: 10.3934/era.2023215
Approximate nearest neighbor (ANN) search has become an essential paradigm for large-scale image retrieval. Conventional ANN search requires the categories of query images to been seen in the training set. However, facing the rapid evolution of newly-emerging concepts on the web, it is too expensive to retrain the model via collecting labeled data with the new (unseen) concepts. Existing zero-shot hashing methods choose the semantic space or intermediate space as the embedding space, which ignore the inconsistency of visual space and semantic space and suffer from the hubness problem on the zero-shot image retrieval task. In this paper, we present an novel deep quantization network with visual-semantic alignment for efficient zero-shot image retrieval. Specifically, we adopt a multi-task architecture that is capable of $ 1) $ learning discriminative and polymeric image representations for facilitating the visual-semantic alignment; $ 2) $ learning discriminative semantic embeddings for knowledge transfer; and $ 3) $ learning compact binary codes for aligning the visual space and the semantic space. We compare the proposed method with several state-of-the-art methods on several benchmark datasets, and the experimental results validate the superiority of the proposed method.

| [1] | W. Zhou, H. Li, Q. Tian, Recent advance in content-based image retrieval: a literature survey, preprint, arXiv: 1706.06064. |
| [2] |
J. H. Friedman, J. L. Bentley, R. A. Finkel, An algorithm for finding best matches in logarithmic expected time, ACM Trans. Math. Software, 3 (1977), 209–226. https://doi.org/10.1145/355744.355745 doi: 10.1145/355744.355745

|
| [3] | A. Gionis, P. Indyk, R. Motwani, Similarity search in high dimensions via hashing, in International Conference on Very Large Data Bases, 99 (1999), 518–529. Available from: https://www.cs.princeton.edu/courses/archive/spring13/cos598C/Gionis.pdf. |
| [4] |
Y. Gong, S. Lazebnik, A. Gordo, F. Perronnin, Iterative quantization: a procrustean approach to learning binary codes for large-scale image retrieval, IEEE Trans. Pattern Anal. Mach. Intell., 35 (2012), 2916–2929. https://doi.org/10.1109/TPAMI.2012.193 doi: 10.1109/TPAMI.2012.193
|
| [5] | W. J. Li, S. Wang, W. C. Kang, Feature learning based deep supervised hashing with pairwise labels, preprint, arXiv: 1511.03855. |
| [6] | Y. Weiss, A. Torralba, R. Fergus, Spectral hashing, in Advances in Neural Information Processing Systems, 21 (2008), 1753–1760. Available from: https://proceedings.neurips.cc/paper_files/paper/2008/file/d58072be2820e8682c0a27c0518e805e-Paper.pdf. |
| [7] | W. Liu, J. Wang, S. Kumar, S. F. Chang, Hashing with graphs, in Proceedings of the 28 th International Conference on Machine Learning, (2011), 1–8. Available from: https://storage.googleapis.com/pub-tools-public-publication-data/pdf/37599.pdf. |
| [8] | W. Liu, J. Wang, R. Ji, Y. G. Jiang, S. F. Chang, Supervised hashing with kernels, in 2012 IEEE Conference on Computer Vision and Pattern Recognition, (2012), 2074–2081. https://doi.org/10.1109/CVPR.2012.6247912 |
| [9] | F. Shen, C. Shen, W. Liu, H. T. Shen, Supervised discrete hashing, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2015), 37–45. |
| [10] | W. C. Kang, W. J. Li, Z. H. Zhou, Column sampling based discrete supervised hashing, in Proceedings of the AAAI Conference on Artificial Intelligence, 30 (2016), 1230–1236. https://doi.org/10.1609/aaai.v30i1.10176 |
| [11] | Z. Cao, M. Long, J. Wang, P. S. Yu, Hashnet: deep learning to hash by continuation, in Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2017), 5608–5617. |
| [12] | H. Zhu, M. Long, J. Wang, Y. Cao, Deep hashing network for efficient similarity retrieval, in Proceedings of the AAAI Conference on Artificial Intelligence, 30 (2016), 2415–2421. https://doi.org/10.1609/aaai.v30i1.10235 |
| [13] | H. Liu, R. Wang, S. Shan, X. Chen, Deep supervised hashing for fast image retrieval, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 2064–2072. |
| [14] | G. Irie, H. Arai, Y. Taniguchi, Alternating co-quantization for cross-modal hashing, in Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2015), 1886–1894. |
| [15] | M. Long, Y. Cao, J. Wang, P. S. Yu, Composite correlation quantization for efficient multimodal retrieval, in Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval, (2016), 579–588. https://doi.org/10.1145/2911451.2911493 |
| [16] | Y. Cao, M. Long, J. Wang, S. Liu, Deep visual-semantic quantization for efficient image retrieval, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 1328–1337. |
| [17] | Y. Cao, M. Long, J. Wang, S. Liu, Collective deep quantization for efficient cross-modal retrieval, in Thirty-First AAAI Conference on Artificial Intelligence, 31 (2017), 3974–3980. https://doi.org/10.1609/aaai.v31i1.11218 |
| [18] |
E. Yang, C. Deng, C. Li, W. Liu, J. Li, D. Tao, Shared predictive cross-modal deep quantization, IEEE Trans. Neural Networks Learn. Syst., 29 (2018), 5292–5303. https://doi.org/10.1109/TNNLS.2018.2793863 doi: 10.1109/TNNLS.2018.2793863
|
| [19] |
Y. Fu, T. Xiang, Y. Jiang, X. Xue, L. Sigal, S. Gong, Recent advances in zero-shot recognition: toward data-efficient understanding of visual content, IEEE Signal Process Mag., 35 (2017), 112–125. https://doi.org/10.1109/MSP.2017.2763441 doi: 10.1109/MSP.2017.2763441
|
| [20] | L. Zhang, T. Xiang, S. Gong, Learning a deep embedding model for zero-shot learning, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 2021–2030. |
| [21] | Y. Li, Z. Jia, J. Zhang, K. Huang, T. Tan, Deep semantic structural constraints for zero-shot learning, in Proceedings of the AAAI Conference on Artificial Intelligence, 32 (2018), 7049–7056. https://doi.org/10.1609/aaai.v32i1.12244 |
| [22] | A. Farhadi, I. Endres, D. Hoiem, D. A. Forsyth, Describing objects by their attributes, in 2009 IEEE Conference on Computer Vision and Pattern Recognition, (2009), 1778–1785. https://doi.org/10.1109/CVPR.2009.5206772 |
| [23] | T. Mikolov, K. Chen, G. Corrado, J. Dean, Efficient estimation of word representations in vector space, preprint, arXiv: 1301.3781. |
| [24] |
G. A. Miller, Wordnet: a lexical database for English, Commun. ACM, 38 (1995), 39–41. https://doi.org/10.1145/219717.219748 doi: 10.1145/219717.219748
|
| [25] | Y. Guo, G. Ding, J. Han, Y. Gao, Sitnet: discrete similarity transfer network for zero-shot hashing, in Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence (IJCAI-17), (2017), 1767–1773. Available from: https://www.ijcai.org/proceedings/2017/0245.pdf. |
| [26] | Y. Yang, Y. Luo, W. Chen, F. Shen, J. Shao, H. T. Shen, Zero-shot hashing via transferring supervised knowledge, in Proceedings of the 24th ACM International Conference on Multimedia, (2016), 1286–1295. https://doi.org/10.1145/2964284.2964319 |
| [27] | Y. Xu, Y. Yang, F. Shen, X. Xu, Y. Zhou, H. T. Shen, Attribute hashing for zero-shot image retrieval, in 2017 IEEE International Conference on Multimedia and Expo (ICME), (2017), 133–138. https://doi.org/10.1109/ICME.2017.8019425 |
| [28] | H. Jiang, R. Wang, S. Shan, X. Chen, Learning class prototypes via structure alignment for zero-shot recognition, in Computer Vision – ECCV 2018, (2018), 121–138. https://doi.org/10.1007/978-3-030-01249-6_8 |
| [29] | Q. Li, Z. Sun, R. He, T. Tan, Deep supervised discrete hashing, in Advances in Neural Information Processing Systems, 30 (2017), 2479–2488. Available from: https://proceedings.neurips.cc/paper_files/paper/2017/file/e94f63f579e05cb49c05c2d050ead9c0-Paper.pdf. |
| [30] | Y. Cao, M. Long, J. Wang, Correlation hashing network for efficient cross-modal retrieval, preprint, arXiv: 1602.06697. |
| [31] |
T. Ge, K. He, Q. Ke, J. Sun, Optimized product quantization, IEEE Trans. Pattern Anal. Mach. Intell., 36 (2013), 744–755. https://doi.org/10.1109/TPAMI.2013.240 doi: 10.1109/TPAMI.2013.240
|
| [32] |
A. Krizhevsky, I. Sutskever, G. E. Hinton, Imagenet classification with deep convolutional neural networks, Commun. ACM, (2017), 84–90. https://doi.org/10.1145/3065386 doi: 10.1145/3065386
|
| [33] | Y. Liu, H. Li, X. Wang, Rethinking feature discrimination and polymerization for large-scale recognition, preprint, arXiv: 1710.00870. |
| [34] | A. Lazaridou, G. Dinu, M. Baroni, Hubness and pollution: delving into cross-space mapping for zero-shot learning, in Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, 1 (2015), 270–280. https://doi.org/10.3115/v1/P15-1027 |
| [35] | A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, et al., Automatic differentiation in pytorch, 2017. Available from: https://openreview.net/forum?id = BJJsrmfCZ. |
| [36] |
J. Besag, On the statistical analysis of dirty pictures, J. R. Stat. Soc., 48 (1986), 48–259. https://doi.org/10.1111/j.2517-6161.1986.tb01412.x doi: 10.1111/j.2517-6161.1986.tb01412.x
|
| [37] |
C. H. Lampert, H. Nickisch, S. Harmeling, Attribute-based classification for zero-shot visual object categorization, IEEE Trans. Pattern Anal. Mach. Intell., 36 (2013), 453–465. https://doi.org/10.1109/TPAMI.2013.140 doi: 10.1109/TPAMI.2013.140
|
| [38] | J. Deng, W. Dong, R. Socher, L. Li, K. Li, F. Li, Imagenet: a large-scale hierarchical image database, in 2009 IEEE Conference on Computer Vision and Pattern Recognition, (2009), 248–255. https://doi.org/10.1109/CVPR.2009.5206848 |

Figures(2) / Tables(4)
Huixia Liu, Zhihong Qin. Deep quantization network with visual-semantic alignment for zero-shot image retrieval[J]. Electronic Research Archive, 2023, 31(7): 4232-4247. doi: 10.3934/era.2023215







 DownLoad:
DownLoad: