Citation: David Cuesta-Frau, Pau Miró-Martínez, Sandra Oltra-Crespo, Antonio Molina-Picó, Pradeepa H. Dakappa, Chakrapani Mahabala, Borja Vargas, Paula González. Classification of fever patterns using a single extracted entropy feature: A feasibility study based on Sample Entropy[J]. Mathematical Biosciences and Engineering, 2020, 17(1): 235-249. doi: 10.3934/mbe.2020013

| [1] | D. Ogoina, Fever, fever patterns and diseases called fever-A review, J. Infect. Public Heal., 4 (2011), 108-124. |
| [2] | G. Kelly, Body temperature variability (part 1): A review of the history of body temperature and its variability due to site selection, biological rhythms, fitness, and aging, Altern. Med. Rev., 11 (2007), 278-293. |
| [3] | G. Kelly, Body temperature variability (part 2): Masking influences of body temperature variability and a review of body temperature variability in disease, Altern. Med. Rev., 12 (2007), 49-62. |
| [4] | T. E. Fletcher, C. P. Bleeker-Rovers and N. J. Beeching, Fever, Medicine, 45 (2017), 177-183, Acute Medicine Part 2 of 2. |
| [5] | T. Susilawati and W. McBride, Acute undifferentiated fever in Asia: A review of the literature,SE Asian J. Trop. Med. Public Health, 45 (2014), 719-726. |
| [6] | W. Chen, Thermometry and interpretation of body temperature, Biomed. Eng. Lett., 9 (2019), 3-17. |
| [7] | M. Varela-Entrecanales, D. Cuesta-Frau, J. A. Madrid, et al., Holter monitoring of central and peripheral temperature: Possible uses and feasibility study in outpatient settings, J. Clin. Monit. Comput., 23 (2009), 209-216. |
| [8] | D. Cuesta-Frau, P. Miró-Martínez, S. Oltra-Crespo, et al., Model selection for body temperature signal classification using both amplitude and ordinality-based entropy measures, Entropy, 20 (2018). |
| [9] | J. Jordán-Núnez, P. Miró-Martínez, B. Vargas, et al., Statistical models for fever forecasting based on advanced body temperature monitoring, J. Crit. Care, 37 (2017), 136-140. |
| [10] | A. M Drewry, B. Fuller, T. Bailey, et al., Body temperature patterns as a predictor of hospitalacquired sepsis in afebrile adult intensive care unit patients: A case-control study, Crit. Care, 17 (2013), R200. |
| [11] | V. Papaioannou, I. Chouvarda, N. Maglaveras, et al., Temperature variability analysis using Wavelets and Multiscale Entropy in patients with systemic inflammatory response syndrome, sepsis, and septic shock, Crit. Care, 16 (2012), R51. |
| [12] | V. E. Papaioannou, I. G. Chouvarda, N. K. Maglaveras, et al., Temperature Multiscale Entropy analysis: A promising marker for early prediction of mortality in septic patients, Physiol. Meas.,34 (2013), 1449. |
| [13] | D. Cuesta-Frau, M. Varela, P. Miró-Martínez, et al., Predicting survival in critical patients by use of body temperature regularity measurement based on Approximate Entropy, Medical & Biological Engineering & Computing, 45 (2007), 671-678. |
| [14] | P. H. Dakappa, K. Prasad, S. B. Rao, et al., Classification of infectious and noninfectious diseases using artificial neural networks from 24-hour continuous tympanic temperature data of patients with undifferentiated fever, Crit. Rev. Bio. Eng., 46 (2018), 173-183. |
| [15] | P. H. Dakappa, K. Prasad, S. B. Rao, et al., A Predictive Model to Classify Undifferentiated Fever Cases Based on Twenty-Four-Hour Continuous Tympanic Temperature Recording, J. Healthc. Eng., 2017 (2017), 6, URL 10.1155/2017/5707162. |
| [16] | M. Aboy, D. Cuesta-Frau, D. Austin, et al., Characterization of Sample Entropy in the context of biomedical signal analysis, in 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, 2007, 5942-5945. |
| [17] | J. Richman and J. R. Moorman, Physiological time-series analysis using Approximate Entropy and Sample Entropy, Am. J. Physiol. Heart Circ. Physiol., 278 (2000), H2039-2049. |
| [18] | S. M. Pincus, Approximate Entropy as a measure of system complexity, Proceed. Nat. Aca. Sci.,88 (1991), 2297-2301. |
| [19] | W. Chen, J. Zhuang, W. Yu, et al., Measuring complexity using FuzzyEn, ApEn, and SampEn,Med. Eng. Phys., 31 (2009), 61-68. |
| [20] | E. Cirugeda-Roldán, D. Cuesta-Frau, P. Miró-Martínez, et al., A new algorithm for quadratic Sample Entropy optimization for very short biomedical signals: Application to blood pressure records, Comput. Meth. Prog. Bio., 114 (2014), 231-239. |
| [21] | D. E. Lake and J. R. Moorman, Accurate estimation of entropy in very short physiological time series: The problem of atrial fibrillation detection in implanted ventricular devices, Am. J. Physiol.-Heart C., 300 (2011), H319-H325, PMID: 21037227. |
| [22] | S. Simons, P. Espino and D. Abásolo, Fuzzy entropy analysis of the electroencephalogram in patients with Alzheimer's disease: Is the method superior to Sample Entropy?, Entropy, 20 (2018). |
| [23] | D. Cuesta-Frau, P. Miro-Miró-Martínez, J. Jordán-Núnez, et al., Noisy EEG signals classification based on entropy metrics. Performance assessment using first and second generation statistics, Comput. Biol. Med., 87 (2017), 141-151. |
| [24] | D. Cuesta-Frau, D. Novák, V. Burda, et al., Characterization of artifact influence on the classification of glucose time series using sample entropy statistics, Entropy, 20 (2018). |
| [25] | D. Cuesta-Frau, D. Novák, V. Burda, et al., Influence of Duodenal-Jejunal Implantation on Glucose Dynamics: A Pilot Study Using Different Nonlinear Methods, Complexity, 2019 (2019), 10. |
| [26] | A. Lubetzky, D. Harel and E. Lubetzky, On the effects of signal processing on Sample Entropy for postural control, PLOS ONE, 13 (2018), e0193460. |
| [27] | H. Azami and J. Escudero, Coarse-graining approaches in univariate Multiscale Sample and Dispersion Entropy, Entropy, 20(2018), 138. |
| [28] | J. McCamley, W. Denton, A. Arnold, et al., On the calculation of Sample Entropy using continuous and discrete human gait data, Entropy, 20 (2018), 764. |
| [29] | D. Cuesta-Frau, M. Varela-Entrecanales, A. Molina-Picó, et al., Patterns with equal values in Permutation Entropy: Do they really matter for biosignal classification?, Complexity, 2018 (2018), 1-15. |
| [30] | D. Cuesta-Frau, J. C. Pérez-Cortés and G. Andreu-García, Clustering of electrocardiograph signals in computer-aided Holter analysis, Comput. Meth. Prog. Bio., 72 (2003), 179-196. |
| [31] | D. Cuesta-Frau, J. C. Pérez-Cortés and G. Andreu-García, et al., Feature extraction methods applied to the clustering of electrocardiographic signals. a comparative study, in 16 Th International Conference on Pattern Recognition IEEE Computer Society, 3 (2002), 961-964. |
| [32] | P. H. Dakappa, S. B. Rao, B. Ganaraja, et al., Unique temperature patterns in 24-h continuous tympanic temperature in tuberculosis, Trop. Doct., 0049475519829600, PMID: 30782109. |
| [33] | A. A. Rabinstein and K. Sandhu, Non-infectious fever in the neurological intensive care unit: Incidence, causes and predictors, J. Neurol. Neurosurg. Psychiat., 78 (2007), 1278-1280. |
| [34] | J. M. Yentes, N. Hunt, K. K. Schmid, et al., The appropriate use of Approximate Entropy and Sample Entropy with short data sets, An. Biomed. Eng., 41 (2013), 349-365. |
| [35] | A. Romanovsky, C. Simons and V. Kulchitsky, "biphasic" fevers often consist of more than two phases, Am. J. Physiol., 275 (1998), R323-331. |
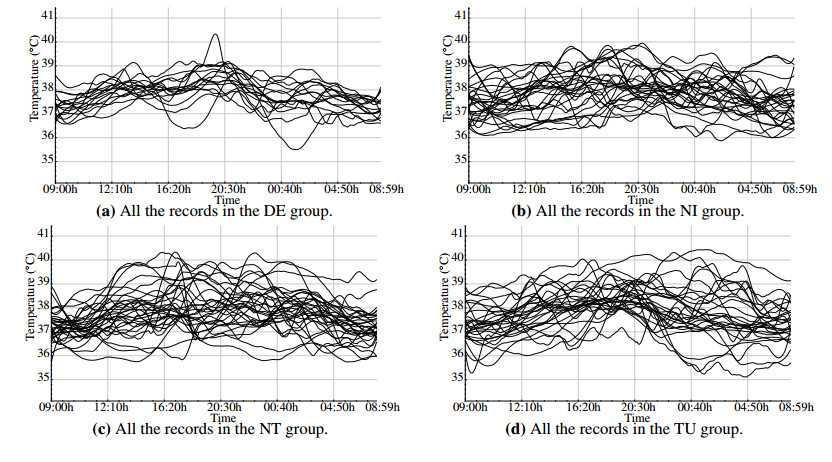
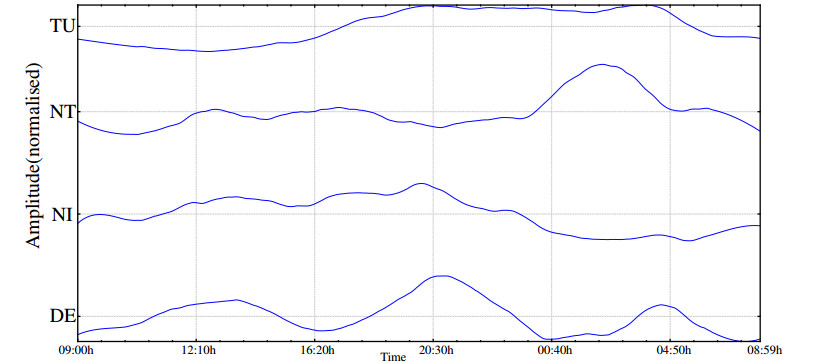
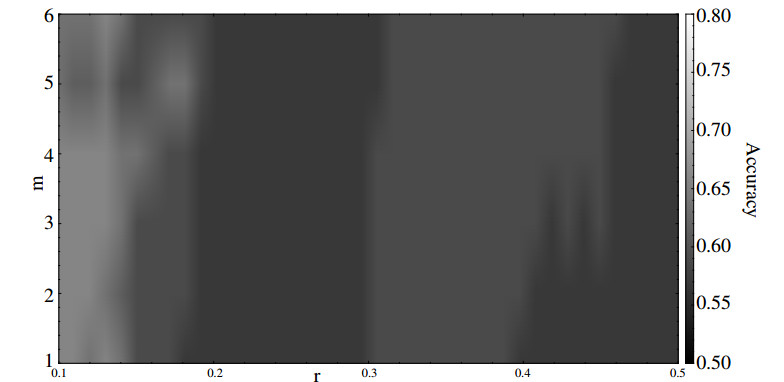
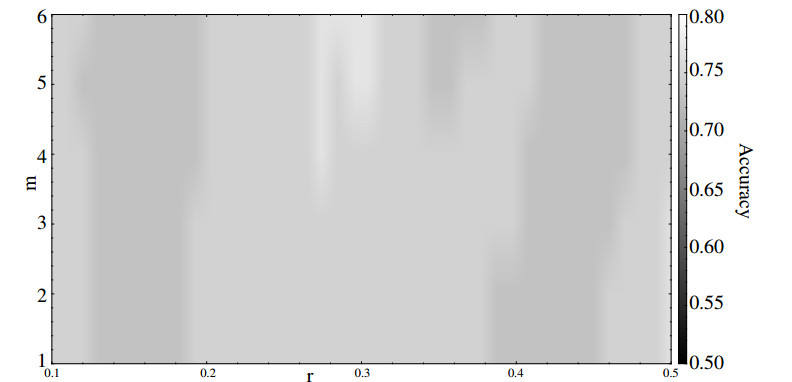
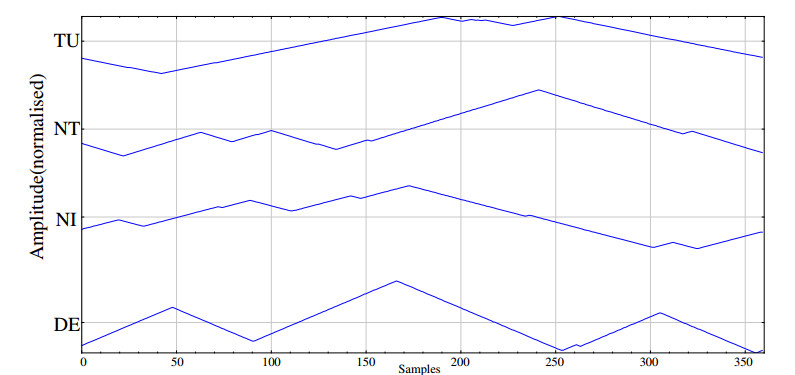
Figures(5) / Tables(3)

David Cuesta-Frau, Pau Miró-Martínez, Sandra Oltra-Crespo, Antonio Molina-Picó, Pradeepa H. Dakappa, Chakrapani Mahabala, Borja Vargas, Paula González. Classification of fever patterns using a single extracted entropy feature: A feasibility study based on Sample Entropy[J]. Mathematical Biosciences and Engineering, 2020, 17(1): 235-249. doi: 10.3934/mbe.2020013







 DownLoad:
DownLoad: