Factorization reduces computational complexity, and is therefore an important tool in statistical machine learning of high dimensional systems. Conventional molecular modeling, including molecular dynamics and Monte Carlo simulations of molecular systems, is a large research field based on approximate factorization of molecular interactions. Recently, the local distribution theory was proposed to factorize joint distribution of a given molecular system into trainable local distributions. Belief propagation algorithms are a family of exact factorization algorithms for (junction) trees, and are extended to approximate loopy belief propagation algorithms for graphs with loops. Despite the fact that factorization of probability distribution is the common foundation, computational research in molecular systems and machine learning studies utilizing belief propagation algorithms have been carried out independently with respective track of algorithm development. The connection and differences among these factorization algorithms are briefly presented in this perspective, with the hope to intrigue further development of factorization algorithms for physical modeling of complex molecular systems.
Citation: Bochuan Du, Pu Tian. Factorization in molecular modeling and belief propagation algorithms[J]. Mathematical Biosciences and Engineering, 2023, 20(12): 21147-21162. doi: 10.3934/mbe.2023935
Factorization reduces computational complexity, and is therefore an important tool in statistical machine learning of high dimensional systems. Conventional molecular modeling, including molecular dynamics and Monte Carlo simulations of molecular systems, is a large research field based on approximate factorization of molecular interactions. Recently, the local distribution theory was proposed to factorize joint distribution of a given molecular system into trainable local distributions. Belief propagation algorithms are a family of exact factorization algorithms for (junction) trees, and are extended to approximate loopy belief propagation algorithms for graphs with loops. Despite the fact that factorization of probability distribution is the common foundation, computational research in molecular systems and machine learning studies utilizing belief propagation algorithms have been carried out independently with respective track of algorithm development. The connection and differences among these factorization algorithms are briefly presented in this perspective, with the hope to intrigue further development of factorization algorithms for physical modeling of complex molecular systems.

| [1] | I. T. Jolliffe, Principal Component Analysis, Springer, New York, 2002. https://doi.org/10.1007/b98835 |
| [2] | T. F. Cox, M. A. A. Cox, Multidimensional Scaling, $2^nd$ eddition, Chapman and Hall/CRC, New York, 2000. https://doi.org/10.1201/9781420036121 |
| [3] |
J. B. Tenenbaum, V. de Silva, J. C. Langford, A global geometric framework for nonlinear dimensionality reduction, Science, 290 (2000), 2319–2323. https://doi.org/10.1126/science.290.5500.2319 doi: 10.1126/science.290.5500.2319

|
| [4] |
S. T. Roweis, L. K. Saul, Nonlinear dimensionality reduction by locally linear embedding, Science, 290 (2000), 2323–2326. https://doi.org/10.1126/science.290.5500.2323 doi: 10.1126/science.290.5500.2323
|
| [5] | R. R. Coifman, S. Lafon, A. B. Lee, M. Maggioni, B. Nadler, F. Warner, et al., Geometric diffusions as a tool for harmonic analysis and structure definition of data: Multiscale methods. Proc. Natl. Acad. Sci., 102 (2005), 7432–7437. https://doi.org/10.1073/pnas.0500896102 |
| [6] |
M. Ceriotti, G. A. Tribello, M. Parrinello, Simplifying the representation of complex free-energy landscapes using sketch-map, Proc. Natl. Acad. Sci., 108 (2011), 13023–13028. https://doi.org/10.1073/pnas.1108486108 doi: 10.1073/pnas.1108486108
|
| [7] | J. Pearl, Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference, Morgan Kaufmann, San Mateo, CA, 1988. |
| [8] |
F. R. Kschischang, B. J. Frey, H. A. Loeliger, Factor graphs and the sum-product algorithm, IEEE Trans. Inf. Theory, 47 (2001), 498–519. https://doi.org/10.1109/18.910572 doi: 10.1109/18.910572
|
| [9] | D. Koller, N. Friedman, Probabilistic Graphical Models: Principles and Techniques, MIT Press, Cambridge, MA, 2009. |
| [10] |
H. Fu, X. Shao, W. Cai, C. Chipot, Taming rugged free energy landscapes using an average force, Acc. Chem. Res., 52 (2019), 3254–3264. https://doi.org/10.1021/acs.accounts.9b00473 doi: 10.1021/acs.accounts.9b00473
|
| [11] |
O. Valsson, P. Tiwary, M. Parrinello, Enhancing important fluctuations: Rare events and metadynamics from a conceptual viewpoint, Annu. Rev. Phys. Chem., 67 (2016), 159–184. https://doi.org/10.1146/annurev-physchem-040215-112229 doi: 10.1146/annurev-physchem-040215-112229
|
| [12] |
G. Bussi, A. Laio, Using metadynamics to explore complex free-energy landscapes, Nat. Rev. Phys., 2 (2020), 200–212. https://doi.org/10.1038/s42254-020-0153-0 doi: 10.1038/s42254-020-0153-0
|
| [13] |
D. Ramachandram, G. W. Taylor, Deep multimodal learning: A survey on recent advances and trends, IEEE Signal Process Mag., 34 (2017), 96–108. https://doi.org/10.1109/MSP.2017.2738401 doi: 10.1109/MSP.2017.2738401
|
| [14] | C. Dellago, P. G. Bolhuis, P. L. Geissler, Transition path sampling, in Advances in Chemical Physics, John Wiley & Sons, Ltd, (2002), 1–78. https://doi.org/10.1002/0471231509.ch1 |
| [15] |
J. Rogal, P. G. Bolhuis, Multiple state transition path sampling, J. Chem. Phys., 129 (2008), 224107. https://doi.org/10.1063/1.3029696 doi: 10.1063/1.3029696
|
| [16] |
P. Buijsman, P. G. Bolhuis, Transition path sampling for non-equilibrium dynamics without predefined reaction coordinates, J. Chem. Phys., 152 (2020), 044108. https://doi.org/10.1063/1.5130760 doi: 10.1063/1.5130760
|
| [17] | R. J. Trudeau, Introduction to Graph Theory, Dover Publications, New York, 1993. |
| [18] |
S. L. Lauritzen, D. J. Spiegelhalter, Local computations with probabilities on graphical structures and their application to expert systems, J. Roy. Statist. Soc. Ser. B, 50 (1988), 157–194. https://doi.org/10.1111/j.2517-6161.1988.tb01721.x doi: 10.1111/j.2517-6161.1988.tb01721.x
|
| [19] | F. V. Jensen, S. L. Lauritzen, K. G. Olesen, Bayesian updating in causal probabilistic networks by local computations, Comput. Statist. Quart., 5 (1990), 269–282. |
| [20] | V. Gogate, R. Dechter, A complete anytime algorithm for treewidth, in Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence, Arlington, Virginia, (2004), 201–208. |
| [21] | E. H. Bachoore, H. L Bodlaender, A branch and bound algorithm for exact, upper, and lower bounds on treewidth, in Algorithmic Aspects in Information and Management, AAIM 2006, Lecture Notes in Computer Science, Springer, (2006), 255–266. https://doi.org/10.1007/11775096_24 |
| [22] | T. J. Ottosen, J. Vomlel, All roads lead to rome–new search methods for the optimal triangulation problem, Int. J. Approximate Reasoning, 53 (2012), 1350–1366. https://doi.org/10.1016/j.ijar.2012.06.006 |
| [23] |
C. Li, M. Ueno, An extended depth-first search algorithm for optimal triangulation of bayesian networks, Int. J. Approximate Reasoning, 80 (2017), 294–312. https://doi.org/10.1016/j.ijar.2016.09.012 doi: 10.1016/j.ijar.2016.09.012
|
| [24] | C. Berrou, A. Glavieux, Turbo Codes, John Wiley & Sons, Ltd, New York, 2003. https://doi.org/10.1002/0471219282.eot346 |
| [25] | J. Gonzalez, Y. Low, C. Guestrin, Parallel splash belief propagation, J. Mach. Learn. Res., 1 (2009), 1–48. |
| [26] | J. S. Yedidia, W. T. Freeman, Y. Weiss, Generalized belief propagation, in NIPS'00: Proceedings of the 13th International Conference on Neural Information Processing System, (2000), 668–674. |
| [27] | M. P. Kumar, P. H. S. Torr, Fast memory-efficient generalized belief propagation, in Computer Vision–ECCV 2006, Lecture Notes in Computer Science, Springer, (2006), 451–463. https://doi.org/10.1007/11744085_35 |
| [28] | S. Y. Chen, H. Tong, Z. Wang, S. Liu, M. Li, B. Zhang, Improved generalized belief propagation for vision processing, Math. Probl. Eng., 2011 (2011). https://doi.org/10.1155/2011/416963 |
| [29] | J. Ortiz, T. Evans, A. J. Davison, A visual introduction to gaussian belief propagation, arXiv preprint, (2021), arXiv: 2107.02308. https://doi.org/10.48550/arXiv.2107.02308 |
| [30] |
P. Tian, The repetitive local sampling and the local distribution theory, WIREs Comput. Mol. Sci., 12 (2021), e1588. https://doi.org/10.1002/wcms.1588 doi: 10.1002/wcms.1588
|
| [31] |
X. Wang, S. Ramirez-Hinestrosa, J. Dobnikar, D. Frenkel, The lennard-jones potential: When (not) to use it, Phys. Chem. Chem. Phys., 22 (2020), 10624–10633. https://doi.org/10.1039/c9cp05445f doi: 10.1039/c9cp05445f
|
| [32] |
B. R. Brooks, C. L. Brooks, A. D. Mackerell, L. Nilsson, R. J. Petrella, B. Roux, et al., CHARMM: The biomolecular simulation program, J. Comput. Chem., 30 (2009), 1545–614. https://doi.org/10.1002/jcc.21287 doi: 10.1002/jcc.21287
|
| [33] |
D. A. Case, T. E. Cheatham, T. Darden, H. Gohlke, R. Luo, K. M. Merz, et al., The amber biomolecular simulation programs, J. Comput. Chem., 26 (2005), 1668–1688. https://doi.org/10.1002/jcc.20290 doi: 10.1002/jcc.20290
|
| [34] | D. Van Der Spoel, E. Lindahl, B. Hess, G. Groenhof, A. E. Mark, H. J. Berendsen, Gromacs: Fast, flexible, and free, J. Comput. Chem., 26 (2005), 1701–1718. https://doi.org/10.1002/jcc.20291 |
| [35] |
R. H. French, V. A. Parsegian, R. Podgornik, R. F. Rajter, A. Jagota, J. Luo, et al., Long range interactions in nanoscale science, Rev. Mod. Phys., 82 (2010), 1887–1944. https://doi.org/10.1103/RevModPhys.82.1887 doi: 10.1103/RevModPhys.82.1887
|
| [36] |
A. Y. Toukmaji, J. A. Board, Ewald summation techniques in perspective: A survey, Comput. Phys. Commun., 95 (1996), 73–92. https://doi.org/10.1016/0010-4655(96)00016-1 doi: 10.1016/0010-4655(96)00016-1
|
| [37] |
C. Pan, Z. Hu, Rigorous error bounds for ewald summation of electrostatics at planar interfaces, J. Chem. Theory Comput., 10 (2014), 534–542. https://doi.org/10.1021/ct400839x doi: 10.1021/ct400839x
|
| [38] |
X. Cao, P. Tian, Molecular free energy optimization on a computational graph, RSC Adv., 11 (2021), 12929–12937. https://doi.org/10.1039/d1ra01455b doi: 10.1039/d1ra01455b
|
| [39] | X. Cao, P. Tian, "Dividing and conquering" and "caching" in molecular modeling, Int. J. Mol. Sci., 22 (2021), 5053. |
| [40] |
Z. Wang, D. W. Scott, Nonparametric density estimation for high-dimensional data–algorithms and applications, WIREs Comput. Stat., 11 (2019), e1461. https://doi.org/10.1002/wics.1461 doi: 10.1002/wics.1461
|
| [41] |
Q. Liu, J. Xu, R. Jiang, W. H. Wong, Density estimation using deep generative neural networks, Proc. Nat. Acad. Sci., 118 (2021), e2101344118. https://doi.org/10.1073/pnas.2101344118 doi: 10.1073/pnas.2101344118
|
| [42] |
H. Zhang, Z. Bei, W. Xi, M. Hao, Z. Ju, K. M. Saravanan, et al., Evaluation of residue-residue contact prediction methods: From retrospective to prospective, PLoS Comput. Biol., 17 (2021), e1009027. https://doi.org/10.1371/journal.pcbi.1009027 doi: 10.1371/journal.pcbi.1009027
|
| [43] |
Y. Q. Gao, An integrate-over-temperature approach for enhanced sampling, J. Chem. Phys., 128 (2008), 064105. https://doi.org/10.1063/1.2825614 doi: 10.1063/1.2825614
|
| [44] |
L. Yang, C. W. Liu, Q. Shao, J. Zhang, Y. Q. Gao, From thermodynamics to kinetics: Enhanced sampling of rare events, Acc. Chem. Res., 48 (2015), 947–955. https://doi.org/10.1021/ar500267n doi: 10.1021/ar500267n
|
| [45] |
R. C. Bernardi, M. C. R. Melo, K. Schulten, Enhanced sampling techniques in molecular dynamics simulations of biological systems, Biochim. Biophys. Acta, 1850 (2015), 872–877. https://doi.org/10.1016/j.bbagen.2014.10.019 doi: 10.1016/j.bbagen.2014.10.019
|
| [46] |
J. Comer, J. C. Gumbart, J. Hénin, T. Lelièvre, A. Pohorille, C. Chipot, The adaptive biasing force method: everything you always wanted to know but were afraid to ask, J. Phy. Chem. B, 119 (2015), 1129–1151. https://doi.org/10.1021/jp506633n doi: 10.1021/jp506633n
|
| [47] |
V. Mlynsky, G. Bussi, Exploring RNA structure and dynamics through enhanced sampling simulations, Curr. Opin. Struct. Biol., 49 (2018), 63–71. https://doi.org/10.1016/j.sbi.2018.01.004 doi: 10.1016/j.sbi.2018.01.004
|
| [48] |
Y. I. Yang, Q. Shao, J. Zhang, L. Yang, Y. Q. Gao, Enhanced sampling in molecular dynamics, J. Chem. Phys., 151 (2019), 070902. https://doi.org/10.1063/1.5109531 doi: 10.1063/1.5109531
|
| [49] |
W. Tschöp, K. Kremer, J. Batoulis, T. Bürger, O. Hahn, Simulation of polymer melts. I. Coarse-graining procedure for polycarbonates, Acta Polym., 49 (1998), 61–74. https://doi.org/10.1002/(sici)1521-4044(199802)49:2/3<61::Aid-apol61>3.0.Co;2-v doi: 10.1002/(sici)1521-4044(199802)49:2/3<61::Aid-apol61>3.0.Co;2-v
|
| [50] |
H. Chan, M. J. Cherukara, B. Narayanan, T. D. Loeffler, C. Benmore, S. K. Gray, et al., Machine learning coarse grained models for water, Nat. Commun., 10 (2019), 379. https://doi.org/10.1038/s41467-018-08222-6 doi: 10.1038/s41467-018-08222-6
|
| [51] |
F. Noe, A. Tkatchenko, K. R. Muller, C. Clementi, Machine learning for molecular simulation, Annu. Rev. Phys. Chem., 71 (2020), 361–390. https://doi.org/10.1146/annurev-physchem-042018-052331 doi: 10.1146/annurev-physchem-042018-052331
|
| [52] |
P. Gkeka, G. Stoltz, A. B. Farimani, Z. Belkacemi, M. Ceriotti, J. D. Chodera, et al., Machine learning force fields and coarse-grained variables in molecular dynamics: Application to materials and biological systems, J. Chem. Theory Comput., 16 (2020), 4757–4775. https://doi.org/10.1021/acs.jctc.0c00355 doi: 10.1021/acs.jctc.0c00355
|
| [53] |
J. Behler, Perspective: Machine learning potentials for atomistic simulations, J. Chem. Phys., 145 (2016), 170901. https://doi.org/10.1063/1.4966192 doi: 10.1063/1.4966192
|
| [54] |
M. Ceriotti. Unsupervised machine learning in atomistic simulations, between predictions and understanding, J. Chem. Phys, 150 (2019), 150901. https://doi.org/10.1063/1.5091842 doi: 10.1063/1.5091842
|
| [55] |
A. Lunghi, S. Sanvito, A unified picture of the covalent bond within quantum-accurate force fields: From organic molecules to metallic complexes' reactivity, Sci. Adv., 5 (2019), eaaw2210. https://doi.org/10.1126/sciadv.aaw2210 doi: 10.1126/sciadv.aaw2210
|
| [56] |
T. Mueller, A. Hernandez, C. Wang, Machine learning for interatomic potential models, J. Chem. Phys., 152 (2020), 050902. https://doi.org/10.1063/1.5126336 doi: 10.1063/1.5126336
|
| [57] |
Z. Huang, Y. Wang, X. Ma, Clustering of cancer attributed networks by dynamically and jointly factorizing multi-layer graphs, IEEE/ACM Trans. Comput. Biol. Bioinf., 19 (2022), 2737–2748. https://doi.org/10.1109/TCBB.2021.3090586 doi: 10.1109/TCBB.2021.3090586
|
| [58] |
X. Gao, X. Ma, W. Zhang, J. Huang, H. Li, Y. Li, et al., Multi-view clustering with self-representation and structural constraint, IEEE Trans. Big Data, 8 (2022), 882–893. https://doi.org/10.1109/tbdata.2021.3128906 doi: 10.1109/tbdata.2021.3128906
|
| [59] |
W. Wu, X. Ma, Network-based structural learning nonnegative matrix factorization algorithm for clustering of scrna-seq data, IEEE/ACM Trans. Comput. Biol. Bioinf., 20 (2023), 566–575. https://doi.org/10.1109/TCBB.2022.3161131 doi: 10.1109/TCBB.2022.3161131
|
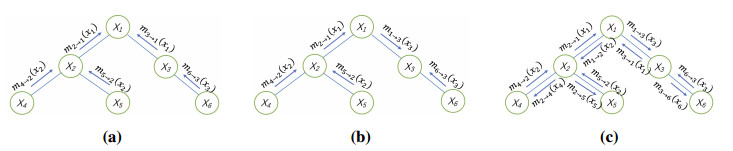



Figures(4)

Bochuan Du, Pu Tian. Factorization in molecular modeling and belief propagation algorithms[J]. Mathematical Biosciences and Engineering, 2023, 20(12): 21147-21162. doi: 10.3934/mbe.2023935







 DownLoad:
DownLoad: