Citation: Ying Dong, Wen Chen, Hui Zhao, Xinlei Ma, Tan Gao, Xudong Li. Label propagation algorithm based on Roll-back detection and credibility assessment[J]. Mathematical Biosciences and Engineering, 2020, 17(3): 2432-2450. doi: 10.3934/mbe.2020132

| [1] | Z. H. Zhou, M. Li, Semi-supervised learning by disagreement, Knowl. Inf. Syst., 24 (2010), 415-439. |
| [2] | X. Zhu, Z. Ghahramani, J. D. Lafferty, Semi-supervised learning using gaussian fields and harmonic functions, Proc. 20th. Int. Conf. Mach Learn.(ICML), Washington DC, USA, August, 2003 (2003), 912-919. |
| [3] | O. Chapelle, B. Scholkopf, A. Zien, Semi-supervised learning, IEEE Trans. Neural Netw. Learn. Syst., 20 (2006), 542-542. |
| [4] | K. P. Bennett, A. Demiriz, Semi-supervised support vector machines, Adv. Neural Inform. Proc. Syst.(NSIP), 1999 (1999), 368-374. |
| [5] | J. Levatic, D. Kocev, M. Ceci, S. Džeroski, Semi-supervised trees for multi-target regression, Inf. Sci., 450 (2018), 109-127. |
| [6] | B. Jiang, H. Chen, B. Yuan, X. Yao, Scalable graph-based semi-supervised learning through sparse bayesian model, IEEE Trans. Knowl. Data Eng., 29 (2017), 2758-2771. |
| [7] | Z. Zhao, M. Zhao, T. W. S. Chow, Graph based constrained semi-supervised learning framework via label propagation over adaptive neighborhood, IEEE Trans. Knowl. Data Eng., 27 (2013), 2362-2376. |
| [8] | J. Xie, B. K. Szymanski, Community detection using a neighborhood strength driven label propagation algorithm, IEEE Netw. Sci. Work.(NSW), West Point, NY, USA, May, 2011 (2011), 188-195. |
| [9] | Z. H. Wu, Y. F. Lin, S. Gregory, H. Y. Wan, S. F. Tian, Balanced multi-label propagation for overlapping community detection in social networks, J. Comput. Sci. Technol., 27 (2012), 468-479. |
| [10] | S. M. Kim, P. Pantel, L. Duan, S. Gaffney, Improving web page classification by label-propagation over click graphs, Proc. 18th ACM Conf. Inform. Knowl. Manag.(CIKM), Hong Kong, China, November, 2009 (2009), 1077-1086. |
| [11] | S. Blair-Goldensohn, K. Hannan, R. McDonald, T. Neylon, J. Reynar, Building a sentiment summarizer for local service reviews, (2008). |
| [12] | V. Badrinarayanan, F. Galasso, R. Cipolla, Label propagation in video sequences, IEEE Comput. Soci. Conf. Comput Vis. Pat Rec.(CVPR), San Francisco, CA, USA, June, 2010 (2010), 3265-3272. |
| [13] | K. Kothapalli, S. V. Pemmaraju, V. Sardeshmukh, On the analysis of a label propagation algorithm for community detection, Int. Conf. Dist Comput. Netw.(ICDCN), Mumbai, Maharastra, India, July, 2013 (2013), 255-269. |
| [14] | C. Gong, D. Tao, W. Liu, L. Liu, J. Yang, Label propagation via teaching-to-learn and learningto-teach, IEEE Trans. Neural Netw. Learn. Syst., 28 (2016), 1452-1465. |
| [15] | J. Hao, X. Chen, S. Huang, Y. Jun, Semi-supervised classification algorithm using fuzzy nearest neighborhood label propagation, Microelectron. Comput., 27 (2010), 30-33. |
| [16] | X. K. Zhang, C. Song, J. Jia, Z. L. Lu, Q. Zhang, An improved label propagation algorithm based on the similarity matrix using random walk, Int. J. Mod. Phys. B, 30 (2016), 1650093. |
| [17] | B. Wang, Z. Tu, J. K. Tsotsos, Dynamic label propagation for semi-supervised multi-class multi-label classification, Proc. IEEE Int. Conf. Comput Vis.(ICCV), Berlin, Germany, June, 2013 (2013), 425-432. |
| [18] | X. Zhu, Z. Ghahramani, Learning from labeled and unlabeled data with label propagation, (2002). |
| [19] | Available from: https://scikit-learn.org/stable/auto_examples/cluster/plot_cluster_comparison.html#sphx-glr-auto-examples-cluster-plot-cluster-comparison-py. |
| [20] | Available from: https://sklearn.apachecn.org/docs/0.21.3/7.html. |
| [21] | Available from: https://sklearn.apachecn.org/docs/0.21.3/11.html. |
| [22] | Available from: https://sklearn.apachecn.org/docs/0.21.3/10.html. |
| [23] | Available from: https://archive.ics.uci.edu/ml/datasets.php. |
| [24] | Available from: https://sklearn.apachecn.org/docs/0.21.3/5.html. |
| [25] | J. Deovre, Probability and statistics for engineering and science, Brooks/Cole, Belmont, CA (1987). |
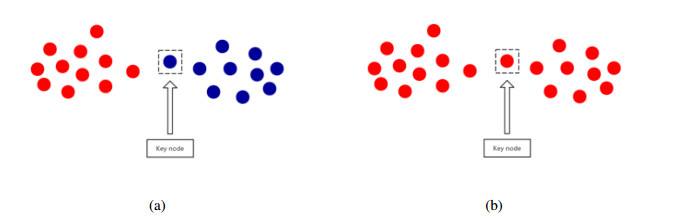
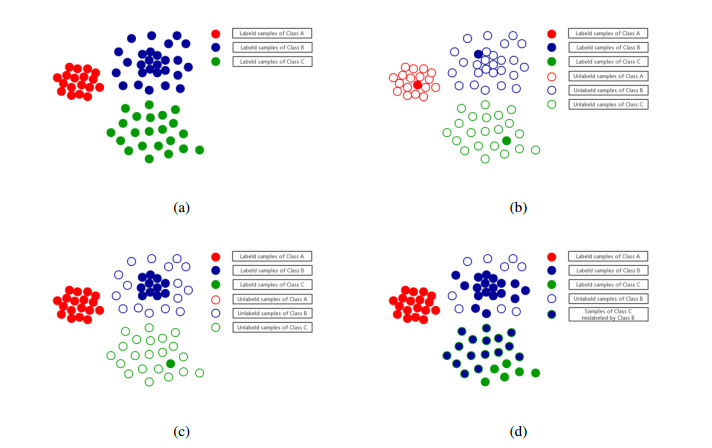
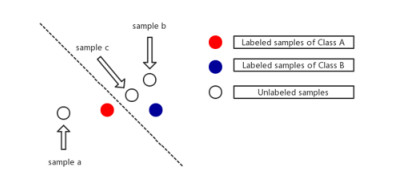
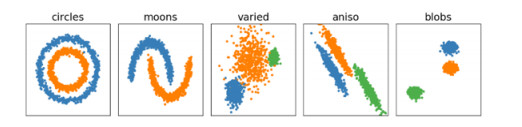

Figures(8) / Tables(7)

Ying Dong, Wen Chen, Hui Zhao, Xinlei Ma, Tan Gao, Xudong Li. Label propagation algorithm based on Roll-back detection and credibility assessment[J]. Mathematical Biosciences and Engineering, 2020, 17(3): 2432-2450. doi: 10.3934/mbe.2020132







 DownLoad:
DownLoad: