Citation: Yongju Tong, YuLing Liu, Jie Wang, Guojiang Xin. Text steganography on RNN-Generated lyrics[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 5451-5463. doi: 10.3934/mbe.2019271

| [1] | R. H. Meng, S. G. Rice, J. Wang, et al.,A fusion steganographic algorithm based on faster R-CNN, CMC Comput. Mater. Con., 55 (2018), 1–16. |
| [2] | G. J. Xin, Y. L. Liu, T. Yang, et al., An adaptive audio steganography for covert wireless communication, Secur. Commun. Netw., 1 (2018), 1–10. |
| [3] | F. Peng, X. Q. Gong, M. Long, et al., A selective encryption scheme for protecting H.264/AVC video in multimedia social network, Multimed. Tools Appl., 76 (2018), 3235–3253. |
| [4] | Y. W. Kim, K. A. Moon and I. S. Oh,A text watermarking algorithm based on word classification and inter-word space statistics, International Conference on Document Analysis and Recognition, 2 (2003), 775–799. |
| [5] | A. M. Alattar and O. M. Alattar, Watermarking electronic text documents containing justified paragraphs and irregular line spacing, International Society for Optics and Photonics, 5306 (2004), 685–695. |
| [6] | B. K. Ramakrishnan, P. K. Thandra and A. V. S. M. Srinivasula, Text steganography: a novel character-level embedding algorithm using font attribute, Secur. Commun. Netw., 9 (2016), 6066– 6079. |
| [7] | R. Kumar, A. Malik, S. Singh, et al., A space based reversible high capacity text steganography scheme using Font type and style, International Conference on Computing, Communication and Automation, (2016), 1090–1094. |
| [8] | Q. Cao, X. M. Sun and L. Y. Xiang,A secure text steganography based on synonym substitution, IEEE Conference Anthology, (2014), 1–3. |
| [9] | L. Y. Xiang, Y. Li and W. Hao, Reversible natural language watermarking using synonym substitution and arithmetic coding, CMC Comput. Mater. Con., 55 (2018), 541–559. |
| [10] | J. Cong, D. Zhang and M. Pan,Chinese text information hiding based on paraphrasing technology, IEEE International Conference of Information Science and Management Engineering, 1 (2010), 39–42. |
| [11] | Y. Yang, Y. W. Chen and Y. L. Chen,A novel universal steganalysis algorithm based on the IQM and the SRM, CMC Comput. Mater. Con., 56 (2018), 261–271. |
| [12] | L. Y. Xiang, J. M. Yu, C. F. Yang, et al., A word-embedding-based steganalysis method for linguistic steganography via synonym-substitution, IEEE Access, 6 (2018), 64131–64141. |
| [13] | Z. S. Yu, L. S. Huang and Z. L. Chen, High embedding ratio text steganography by ci-poetry of the song dynasty, J. Chin. Inf. Proc., 23 (2009), 55–62. |
| [14] | J. W. Wang, T. Li, X. Y. Luo, et al., Identifying computer generated images based on quaternion central moments in color quaternion wavelet domain, IEEE. T. Circ. Syst. Vid., (2018), 1. |
| [15] | X. Zhang and M. Lapata,Chinese poetry generation with recurrent neural networks, International Conference on Empirical Methods in Natural Language Processing, (2014), 670–680. |
| [16] | Q. X. Wang, T. Y. Luo and D. Wang, Can machine generate traditional chinese poetry? A feigenbaum test, International Conference on Brain Inspired Cognitive Systems, 10023 (2016), 34–46. |
| [17] | Q. X. Wang, T. Y. Luo and D. Wang,Chinese song iambics generation with neural attention-based model, Association for Computing Machinery, (2016), 2943–2949. |
| [18] | X. Y. Yi, R. Y. Li and M. S. Sun,Generating chinese classical poems with RNN encoder-decoder, in Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data (eds. M. Sun, X. Wang, B. Chang, D. Xiong), Springer, 10565 (2017), 211–223. |
| [19] | Y.B. Luo, Y.F. Huang andF. F. Li,Textsteganography based onci-poetry generation usingmarkov chain model, KSII. T. Internet. Inf., 10 (2016), 4568–4584. |
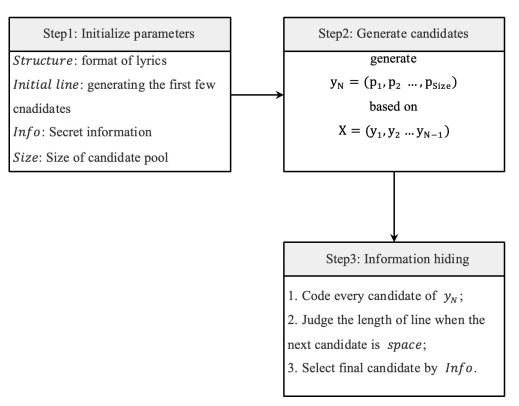
| [20] | Y. B. Luo and Y. F. Huang, Text steganography with high embedding rate: Using recurrent neural networks to generate chinese classic poetry, 5th ACM Workshop on Information Hiding and Multimedia Security, (2017), 99–104. |
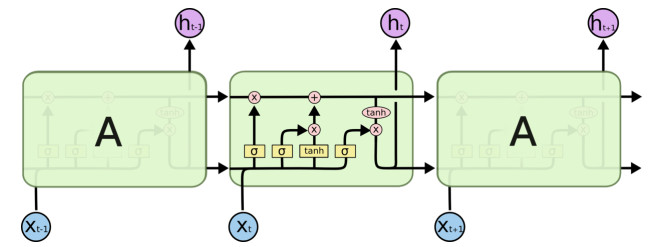
| [21] | C. Olah, Understanding LSTM Networks, 2015. Available from: http://colah.github.io/posts/2015-08-Understanding-LSTMs. |
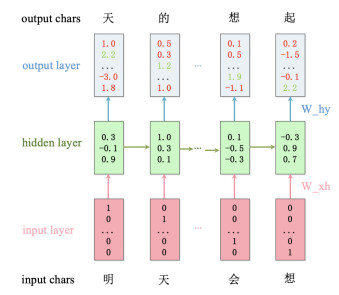
| [22] | A. Karpathy,The unreasonable effectiveness of recurrent neural networks, 2015. Available from: http://karpathy.github.io/2015/05/21/rnn-effectiveness. |
| [23] | Q. Y. Du, The application of the thirteen rhymes in singing technique, Journal of Xingyi Normal University for Nationalities, (2010), in Chinese. |




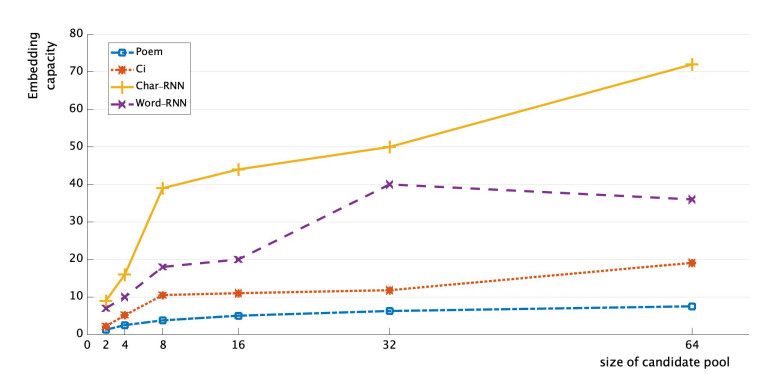
Figures(8) / Tables(3)

Yongju Tong, YuLing Liu, Jie Wang, Guojiang Xin. Text steganography on RNN-Generated lyrics[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 5451-5463. doi: 10.3934/mbe.2019271







 DownLoad:
DownLoad: