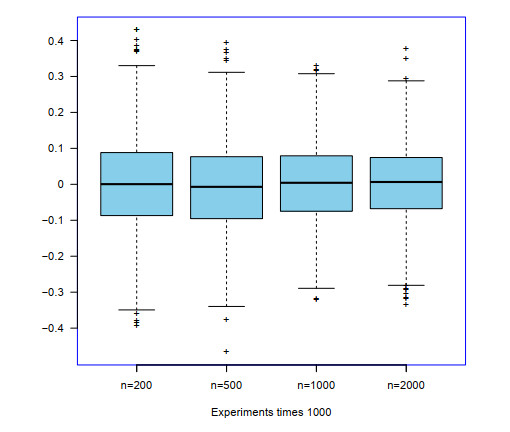
In this work, the law of the single logarithm for randomly weighted sums of widely orthant dependent random variables was studied, which improved and generalized some corresponding results in the literature. As an application, the rate of complete convergence for random weighting estimation with widely orthant dependent samples was obtained under general assumptions. Some numerical analyses were also conducted to confirm the theoretical results.
Citation: Yi Wu, Duoduo Zhao. Law of the single logarithm for randomly weighted sums of dependent sequences and an application[J]. AIMS Mathematics, 2024, 9(4): 10141-10156. doi: 10.3934/math.2024496
In this work, the law of the single logarithm for randomly weighted sums of widely orthant dependent random variables was studied, which improved and generalized some corresponding results in the literature. As an application, the rate of complete convergence for random weighting estimation with widely orthant dependent samples was obtained under general assumptions. Some numerical analyses were also conducted to confirm the theoretical results.

| [1] |
P. L. Hsu, H. Robbins, Complete convergence and the law of large numbers, P. National Acad. Sci. USA, 33 (1947), 25–31. https://doi.org/10.1073/pnas.33.2.25 doi: 10.1073/pnas.33.2.25

|
| [2] |
L. E. Baum, M. Katz, Convergence rates in the law of large numbers, Trans. Amer. Math. Soc., 120 (1965), 108–123. https://doi.org/10.1090/S0002-9947-1965-0198524-1 doi: 10.1090/S0002-9947-1965-0198524-1
|
| [3] |
T. L. Lai, Limit theorems for delayed sums, Ann. Probab., 2 (1974), 432–440. https://doi.org/10.1214/aop/1176996658 doi: 10.1214/aop/1176996658
|
| [4] |
P. Y. Chen, D. C. Wang, Convergence rates for probabilities of moderate deviations for moving average processes, Acta Math. Sin. English Ser., 24 (2008), 611–622. https://doi.org/10.1007/s10114-007-6062-7 doi: 10.1007/s10114-007-6062-7
|
| [5] |
P. Y. Chen, S. H. Sung, A Bernstein type inequality for NOD random variables and applications, J. Math. Inequal., 11 (2017), 455–467. https://doi.org/10.7153/jmi-11-38 doi: 10.7153/jmi-11-38
|
| [6] | Z. D. Bai, P. E. Cheng, C. H. Zhang, An extension of the Hardy-Littlewood strong law, Stat. Sinica, 7 (1997), 923–928. |
| [7] |
P. Y. Chen, S. X. Gan, Limiting behavior of weighted sums of i.i.d. random variables, Statist. Probab. Lett., 77 (2007), 1589–1599. https://doi.org/10.1016/j.spl.2007.03.038 doi: 10.1016/j.spl.2007.03.038
|
| [8] |
S. H. Sung, A law of the single logarithm for weighted sums of i.i.d. random elements, Statist. Probab. Lett., 79 (2009), 1351–1357. https://doi.org/10.1016/j.spl.2009.02.008 doi: 10.1016/j.spl.2009.02.008
|
| [9] |
P. Y. Chen, N. N. Kong, S. H. Sung, Complete convergence for weighted sums of i.i.d. random variables with applications in regression estimation and EV model, Commun. Stat. Theor. M., 46 (2017), 3599–3613. https://doi.org/10.1080/03610926.2015.1066817 doi: 10.1080/03610926.2015.1066817
|
| [10] |
X. D. Liu, L. H. Zhang, J. X. Zuo, The Lai law for weighted sums, J. Math. Inequal., 16 (2022), 1621–1632. https://doi.org/10.7153/jmi-2022-16-105 doi: 10.7153/jmi-2022-16-105
|
| [11] |
J. Cuzick, A strong law for weighted sums of i.i.d. random variables, J. Theor. Probab., 8 (1995), 625–641. https://doi.org/10.1007/BF02218047 doi: 10.1007/BF02218047
|
| [12] |
P. Y. Chen, T. Zhang, S. H. Sung, Strong laws for randomly weighted sums of random variables and applications in the bootstrap and random design regression, Stat. Sinica, 29 (2019), 1739–1749. https://doi.org/10.5705/SS.202017.0106 doi: 10.5705/SS.202017.0106
|
| [13] |
K. Y. Wang, Y. B. Wang, Q. W. Gao, Uniform asymptotics for the finite-time ruin probability of a new dependent risk model with a constant interest rate, Methodol. Comput. Appl. Probab., 15 (2013), 109–124. https://doi.org/10.1007/s11009-011-9226-y doi: 10.1007/s11009-011-9226-y
|
| [14] | K. Alam, K. M. L. Saxena, Positive dependence in multivariate distributions, Commun. Stat. Theor. M., 10 (12), 1183–1196. https://doi.org/10.1080/03610928108828102 |
| [15] | T. Z. Hu, Negatively superadditive dependence of random variables with applications, Chinese J. Appl. Probab. Stat., 16 (2000), 133–144. |
| [16] | E. L. Lehmann, Some concepts of dependence, Ann. Math. Statist., 37 (1966), 1137–1153. https://doi.org/10.1214/aoms/1177699260 |
| [17] |
L. Liu, Precise large deviations for dependent random variables with heavy tails, Stat. Probab. Lett., 79 (2009), 1290–1298. https://doi.org/10.1016/j.spl.2009.02.001 doi: 10.1016/j.spl.2009.02.001
|
| [18] |
Z. G. Zheng, Random weighting method for T statistic, Acta Math. Sin., 5 (1989), 87–94. https://doi.org/10.1007/BF02107626 doi: 10.1007/BF02107626
|
| [19] |
S. S. Gao, J. M. Zhang, T. Zhou, Law of large numbers for sample mean of random weighting estimate, Inform. Sci., 155 (2003), 151–156. https://doi.org/10.1016/S0020-0255(03)00158-0 doi: 10.1016/S0020-0255(03)00158-0
|
| [20] |
L. G. Xue, L. X. Zhu, $L_1$-norm estimation and random weighting method in a semiparametric model, Acta Math. Appl. Sin. English Ser., 21 (2005), 295–302. https://doi.org/10.1007/s10255-005-0237-8 doi: 10.1007/s10255-005-0237-8
|
| [21] |
S. S. Gao, Y. M. Zhong, Random weighting estimation of kernel density, J. Stat. Plan. Infer., 140 (2010), 2403–2407. https://doi.org/10.1016/j.jspi.2010.02.009 doi: 10.1016/j.jspi.2010.02.009
|
| [22] |
R. Roozegar, A. R. Soltani, On the asymptotic behavior of randomly weighted averages, Stat. Probab. Lett., 96 (2015), 269–272. https://doi.org/10.1016/j.spl.2014.10.003 doi: 10.1016/j.spl.2014.10.003
|
| [23] |
K. Joag-Dev, F. Proschan, Negative association of random variables with applications, Ann. Stat., 11 (1983), 286–295. https://doi.org/10.1214/aos/1176346079 doi: 10.1214/aos/1176346079
|
| [24] |
X. J. Wang, C. Xu, T. C. Hu, A. Volodin, S. H. Hu, On complete convergence for widely orthant-dependent random variables and its applications in nonparametric regression models, TEST, 23 (2014), 607–629. https://doi.org/10.1007/s11749-014-0365-7 doi: 10.1007/s11749-014-0365-7
|
| [25] |
Y. Wu, W. Wang, X. J. Wang, Sufficient and necessary conditions for the strong consistency of LS estimators in simple linear EV regression models, J. Stat. Comput. Simul., 93 (2023), 1244–1262. https://doi.org/10.1080/00949655.2022.2134377 doi: 10.1080/00949655.2022.2134377
|
| [26] |
X. Deng, X. J. Wang, An exponential inequality and its application to M estimators in multiple linear models, Stat. Papers, 61 (2020), 1607–1627. https://doi.org/10.1007/s00362-018-0994-0 doi: 10.1007/s00362-018-0994-0
|



Figures(4)

Yi Wu, Duoduo Zhao. Law of the single logarithm for randomly weighted sums of dependent sequences and an application[J]. AIMS Mathematics, 2024, 9(4): 10141-10156. doi: 10.3934/math.2024496







 DownLoad:
DownLoad: