In the present study, we address the nonparametric estimation challenge related to the regression function within the Single Functional Index Model in the random censoring framework. The principal achievement of this investigation lies in the establishment of the asymptotic characteristics of the estimator, including rates of almost complete convergence. Moreover, we establish the asymptotic normality of the constructed estimator under mild conditions. Subsequently, we provide the application of our findings towards the construction of confidence intervals. Lastly, we illuminate the finite-sample performance of both the model and the estimation methodology through the analysis of simulated data and a real-world data example.
Citation: Said Attaoui, Billal Bentata, Salim Bouzebda, Ali Laksaci. The strong consistency and asymptotic normality of the kernel estimator type in functional single index model in presence of censored data[J]. AIMS Mathematics, 2024, 9(3): 7340-7371. doi: 10.3934/math.2024356
In the present study, we address the nonparametric estimation challenge related to the regression function within the Single Functional Index Model in the random censoring framework. The principal achievement of this investigation lies in the establishment of the asymptotic characteristics of the estimator, including rates of almost complete convergence. Moreover, we establish the asymptotic normality of the constructed estimator under mild conditions. Subsequently, we provide the application of our findings towards the construction of confidence intervals. Lastly, we illuminate the finite-sample performance of both the model and the estimation methodology through the analysis of simulated data and a real-world data example.

| [1] |
A. Ait-Saïdi, F. Ferraty, R. Kassa, P. Vieu, Cross-validated estimations in the single-functional index model, Statistics, 42 (2008), 475–494. https://doi.org/10.1080/02331880801980377 doi: 10.1080/02331880801980377

|
| [2] |
I. M. Almanjahie, S. Bouzebda, Z. Kaid, A. Laksaci, Nonparametric estimation of expectile regression in functional dependent data, J. Nonparametr. Stat., 34 (2022), 250–281. https://doi.org/10.1080/10485252.2022.2027412 doi: 10.1080/10485252.2022.2027412
|
| [3] |
S. Attaoui, On the nonparametric conditional density and mode estimates in the single functional index model with strongly mixing data, Sankhya A, 76 (2014), 356–378. https://doi.org/10.1007/s13171-014-0051-6 doi: 10.1007/s13171-014-0051-6
|
| [4] |
S. Attaoui, N. Ling, Asymptotic results of a nonparametric conditional cumulative distribution estimator in the single functional index modeling for time series data with applications, Metrika, 79 (2016), 485–511. https://doi.org/10.1007/s00184-015-0564-6 doi: 10.1007/s00184-015-0564-6
|
| [5] |
S. Attaoui, A. Laksaci, E. Ould Said, A note on the conditional density estimate in the single functional index model, Statist. Probab. Lett., 81 (2011), 45–53. https://doi.org/10.1016/j.spl.2010.09.017 doi: 10.1016/j.spl.2010.09.017
|
| [6] | S. Bhattacharjee, H. G. Müller, Single index Fréchet regression, Ann. Statist., 51 (2023), 1770–1798. https://doi.org/110.1214/23-aos2307 |
| [7] | V. I. Bogachev, Gaussian Measures, Providence: American Mathematical Society, 1998. |
| [8] | D. Bosq, Linear Processes in Function Spaces, New York: Springer-Verlag, 2000. https://doi.org/10.1007/978-1-4612-1154-9 |
| [9] | M. Bouraine, A. A. Saidi, F. Ferraty, P. Vieu, Choix optimal de l'indice multi-fonctionnel: méthode de validation croisée, Rev. Roumaine Math. Pures Appl., 55 (2010), 355–367. |
| [10] | S. Bouzebda, On the weak convergence and the uniform-in-bandwidth consistency of the general conditional $U$-processes based on the copula representation: multivariate setting, Hacet. J. Math. Stat., 52 (2023), 1303–1348. |
| [11] |
S. Bouzebda, General tests of conditional independence based on empirical processes indexed by functions, Jpn. J. Stat. Data Sci., 6 (2023), 115–177. https://doi.org/10.1007/s42081-023-00193-3 doi: 10.1007/s42081-023-00193-3
|
| [12] |
S. Bouzebda, M. Chaouch, Uniform limit theorems for a class of conditional $Z$-estimators when covariates are functions, J. Multivariate Anal., 189 (2022), 104872. https://doi.org/10.1016/j.jmva.2021.104872. doi: 10.1016/j.jmva.2021.104872
|
| [13] |
S. Bouzebda, B. Nemouchi, Weak-convergence of empirical conditional processes and conditional $U$-processes involving functional mixing data, Stat. Inference Stoch. Process., 26 (2023), 33–88. https://doi.org/10.1007/s11203-022-09276-6 doi: 10.1007/s11203-022-09276-6
|
| [14] |
S. Bouzebda, N. Taachouche, Rates of the strong uniform consistency for the kernel-type regression function estimators with general kernels on manifolds, Math. Methods Statist., 32 (2023), 27–80. https://doi.org/10.3103/s1066530723010027 doi: 10.3103/s1066530723010027
|
| [15] |
S. Bouzebda, N. Taachouche, On the variable bandwidth kernel estimation of conditional $U$-statistics at optimal rates in sup-norm, Phys. A, 625 (2023), 129000. https://doi.org/10.1016/j.physa.2023.129000 doi: 10.1016/j.physa.2023.129000
|
| [16] |
S. Bouzebda, I. Elhattab, A. Abdeldjaoued Ferfache, General $M$-estimator processes and their $m$ out of $n$ bootstrap with functional nuisance parameters, Methodol. Comput. Appl. Probab., 24 (2022), 2961–3005. https://doi.org/10.1007/s11009-022-09965-y doi: 10.1007/s11009-022-09965-y
|
| [17] |
S. Bouzebda, A. Abdeldjaoued Ferfache, T. El-hadjali, Uniform in bandwidth consistency of conditional $U$-statistics adaptive to intrinsic dimension in presence of censored data, Sankhya A, 85 (2023), 1548–1606. https://doi.org/10.1007/s13171-022-00301-7 doi: 10.1007/s13171-022-00301-7
|
| [18] | A. Carbonez, L. Györfi, E. C. van der Meulen, Partitioning-estimates of a regression function under random censoring, Statist. Decisions, 13 (1995), 21–37. |
| [19] | L. Györfi, M. Kohler, A. Krzyżak, H. Walk, A Distribution-Free Theory of Nonparametric Regression, New York: Springer, 2002. https://doi.org/10.1007/b97848 |
| [20] | J. E. Chacón, T. Duong, Multivariate Kernel Smoothing and Its Applications, Boca Raton: CRC Press, 2018. https://doi.org/10.1201/9780429485572. |
| [21] |
D. Chen, P. Hall, H. G. Müller, Single and multiple index functional regression models with nonparametric link, Ann. Statist., 39 (2011), 1720–1747. https://doi.org/10.1214/11-AOS882 doi: 10.1214/11-AOS882
|
| [22] |
A. Cuevas, A partial overview of the theory of statistics with functional data, J. Statist. Plann. Inference, 147 (2014), 1–23. https://doi.org/10.1016/j.jspi.2013.04.002 doi: 10.1016/j.jspi.2013.04.002
|
| [23] |
P. Deheuvels, J. H. J. Einmahl, Functional limit laws for the increments of Kaplan-Meier product-limit processes and applications, Ann. Prob., 28 (2000), 1301–1335. https://doi.org/10.1214/aop/1019160336 doi: 10.1214/aop/1019160336
|
| [24] | L. Devroye, A Course in Density Estimation, Boston: Birkhäuser Boston, 1987. |
| [25] | L. Devroye, G. Lugosi, Combinatorial Methods in Density Estimation, New York: Springer-Verlag, 2001. https://doi.org/10.1007/978-1-4613-0125-7 |
| [26] | P. P. B. Eggermont, V. N. LaRiccia, Maximum Penalized Likelihood Estimation. Volume II. Regression, Dordrecht: Springer, 2009. https://doi.org/10.1007/b12285 |
| [27] |
S. Feng, P. Tian, Y. Hu, G. Li, Estimation in functional single-index varying coefficient model, J. Statist. Plann. Inference, 214 (2021), 62–75. https://doi.org/10.1016/j.jspi.2021.01.003 doi: 10.1016/j.jspi.2021.01.003
|
| [28] | F. Ferraty, P. Vieu, Nonparametric Functional Data Analysis, New York: Springer, 2006. |
| [29] |
F. Ferraty, A. Peuch, P. Vieu, Modèle à indice fonctionnel simple, C. R. Math. Acad. Sci. Paris, 336 (2003), 1025–1028. https://doi.org/10.1016/S1631-073X(03)00239-5 doi: 10.1016/S1631-073X(03)00239-5
|
| [30] |
F. Ferraty, A. Mas, P. Vieu, Nonparametric regression on functional data: inference and practical aspects, Aust. N. Z. J. Stat., 49 (2007), 267–286. https://doi.org/10.1111/j.1467-842X.2007.00480.x doi: 10.1111/j.1467-842X.2007.00480.x
|
| [31] |
F. Ferraty, I. Van Keilegom, P. Vieu, On the validity of the bootstrap in non-parametric functional regression, Scand. J. Stat., 37 (2010), 286–306. https://doi.org/10.1111/j.1467-9469.2009.00662.x doi: 10.1111/j.1467-9469.2009.00662.x
|
| [32] |
A. Földes, L. Rejtő, A LIL type result for the product limit estimator, Z. Wahrsch. Verw. Gebiete, 56 (1981), 75–86. https://doi.org/10.1007/BF00531975 doi: 10.1007/BF00531975
|
| [33] | T. Gasser, P. Hall, B. Presnell, Nonparametric estimation of the mode of a distribution of random curves, J. R. Stat. Soc. Ser. B Stat. Methodol., 60 (1998), 681–691. |
| [34] |
A. Goia, P. Vieu, An introduction to recent advances in high/infinite dimensional statistics, J. Multivariate Anal., 146 (2016), 1–6. https://doi.org/10.1016/j.jmva.2015.12.001 doi: 10.1016/j.jmva.2015.12.001
|
| [35] |
L. Gu, L. Yang, Oracally efficient estimation for single-index link function with simultaneous confidence band, Electron. J. Stat., 9 (2015), 1540–1561. https://doi.org/10.1214/15-EJS1051 doi: 10.1214/15-EJS1051
|
| [36] |
Z. Guessoum, E. Ould-Saïd, On nonparametric estimation of the regression function under random censorship model, Statist. Decis., 26 (2008), 159–177. https://doi.org/10.1524/stnd.2008.0919 doi: 10.1524/stnd.2008.0919
|
| [37] |
P. Hall, M. Hosseini-Nasab, On properties of functional principal components analysis, J. R. Stat. Soc. Ser. B Stat. Methodol., 68 (2006), 109–126. https://doi.org/10.1111/j.1467-9868.2005.00535.x doi: 10.1111/j.1467-9868.2005.00535.x
|
| [38] | M. M. Hamri, S. D. Mekki, A. Rabhi, N. Kadiri, Single functional index quantile regression for independent functional data under right-censoring, Economet. Ekonometria. Adv. Appl. Data Anal., 26 (2022), 31–62. |
| [39] |
Z. C. Han, J. G. Lin, Y. Y. Zhao, Adaptive semiparametric estimation for single index models with jumps, Comput. Statist. Data Anal., 151 (2020), 107013. https://doi.org/10.1016/j.csda.2020.107013 doi: 10.1016/j.csda.2020.107013
|
| [40] | M. Hao, K. Liu, W. Su, X. Zhao, Semiparametric estimation for the functional additive hazards model, Canad. J. Statist., 2023. https://doi.org/10.1002/cjs.11805 |
| [41] |
W. Härdle, V. Spokoiny, S. Sperlich, Semiparametric single index versus fixed link function modelling, Ann. Statist., 25 (1997), 212–243. https://doi.org/10.1214/aos/1034276627 doi: 10.1214/aos/1034276627
|
| [42] | L. Horváth, P. Kokoszka, Inference for Functional Data with Applications. New York: Springer, 2012. https://doi.org/10.1007/978-1-4614-3655-3 |
| [43] |
Z. Jiang, Z. Huang, J. Zhang, Functional single-index composite quantile regression, Metrika, 86 (2023), 595–603. https://doi.org/10.1007/s00184-022-00887-w doi: 10.1007/s00184-022-00887-w
|
| [44] | E. L. Kaplan, P. Meier, Nonparametric estimation from incomplete observations, J. Amer. Statist. Assoc., 53 (1958), 457–481. |
| [45] |
M. Kohler, K. Máthé, M. Pintér, Prediction from randomly right censored data, J. Multivariate Anal., 80 (2002), 73–100. https://doi.org/10.1006/jmva.2000.1973 doi: 10.1006/jmva.2000.1973
|
| [46] |
D. R. Kowal, A. Canale, Semiparametric functional factor models with bayesian rank selection, Bayesian Anal., 18 (2023), 1161–1189. https://doi.org/10.1214/23-ba1410 doi: 10.1214/23-ba1410
|
| [47] |
J. Li, C. Huang, H. Zhu, A functional varying-coefficient single-index model for functional response data, J. Amer. Statist. Assoc., 112 (2017), 1169–1181. https://doi.org/10.1080/01621459.2016.1195742 doi: 10.1080/01621459.2016.1195742
|
| [48] |
W. V. Li, Q. M. Shao, Gaussian processes: inequalities, small ball probabilities and applications, Handbook Statist., 19 (2001), 533–597. https://doi.org/10.1016/S0169-7161(01)19019-X doi: 10.1016/S0169-7161(01)19019-X
|
| [49] |
Y. Li, N. Wang, R. J. Carroll, Generalized functional linear models with semiparametric single-index interactions, J. Amer. Statist. Assoc., 105 (2010), 621–633. https://doi.org/10.1198/jasa.2010.tm09313 doi: 10.1198/jasa.2010.tm09313
|
| [50] |
H. Liang, X. Liu, R. Li, C. L. Tsai, Estimation and testing for partially linear single-index models, Ann. Statist., 38 (2010), 3811–3836. https://doi.org/10.1214/10-AOS835 doi: 10.1214/10-AOS835
|
| [51] |
N. Ling, P. Vieu, Nonparametric modelling for functional data: selected survey and tracks for future, Statistics, 52 (2018), 934–949. https://doi.org/10.1080/02331888.2018.1487120 doi: 10.1080/02331888.2018.1487120
|
| [52] |
N. Ling, Qian Xu, Asymptotic normality of conditional density estimation in the single index model for functional time series data, Statist. Probab. Lett., 82 (2012), 2235–2243. https://doi.org/10.1016/j.spl.2012.08.018 doi: 10.1016/j.spl.2012.08.018
|
| [53] | N. Ling, L. Cheng, P. Vieu, Single functional index model under responses MAR and dependent observations, In: Functional and high-dimensional statistics and related fields, 161–168, 2020. https://doi.org/10.1007/978-3-030-47756-1_22 |
| [54] |
N. Ling, L. Cheng, P. Vieu, H. Ding, Missing responses at random in functional single index model for time series data, Statist. Papers, 63 (2022), 665–692. https://doi.org/10.1007/s00362-021-01251-2 doi: 10.1007/s00362-021-01251-2
|
| [55] |
E. Masry, Nonparametric regression estimation for dependent functional data: asymptotic normality, Stochast. Process. Appl., 115 (2005), 155–177. https://doi.org/10.1016/j.spa.2004.07.006 doi: 10.1016/j.spa.2004.07.006
|
| [56] | E. Mayer-Wolf, O. Zeitouni, The probability of small Gaussian ellipsoids and associated conditional moments, Ann. Probab., 21 (1993), 14–24. |
| [57] | G. McLachlan, D. Peel, Finite Mixture Models, New York: Wiley-Interscience, 2000. https://doi.org/10.1002/0471721182 |
| [58] | M. Mohammedi, S. Bouzebda, A. Laksaci, O. Bouanani, Asymptotic normality of the k-nn single index regression estimator for functional weak dependence data, Comm. Statist. Theory Meth., 2022. https://doi.org/10.1080/03610926.2022.2150823 |
| [59] | È. A. Nadaraja, On a regression estimate, Teor. Verojatnost. Primenen., 9 (1964), 157–159. |
| [60] | È. A. Nadaraya, Nonparametric Estimation of Probability Densities and Regression Curves, Dordrecht: Kluwer Academic Publishers, 1989. https://doi.org/10.1007/978-94-009-2583-0 |
| [61] |
Y. Nie, L. Wang, J. Cao, Estimating functional single index models with compact support, Environmetrics, 34 (2023), e2784. https://doi.org/10.1002/env.2784 doi: 10.1002/env.2784
|
| [62] |
S. Novo, G. Aneiros, P. Vieu, Automatic and location-adaptive estimation in functional single-index regression, J. Nonparametr. Stat., 31 (2019), 364–392. https://doi.org/10.1080/10485252.2019.1567726 doi: 10.1080/10485252.2019.1567726
|
| [63] |
E. Ould-Saïd, A strong uniform convergence rate of kernel conditional quantile estimator under random censorship, Statist. Prob. Lett., 76 (2006), 579–586. https://doi.org/10.1016/j.spl.2005.09.002 doi: 10.1016/j.spl.2005.09.002
|
| [64] | J. O. Ramsay, B. W. Silverman, Functional Data Analysis, New York: Springer, 2005. |
| [65] | D. W. Scott, Multivariate Density Estimation. Theory, Practice, and Visualization, WHoboken: John Wiley & Sons, 2015. |
| [66] | G. R. Shorack, J. A. Wellner, Empirical Processes with Applications to Statistics, New York: John Wiley & Sons, 1986. |
| [67] | B. W. Silverman, Density Estimation for Statistics and Data Analysis, London: Chapman & Hall, 1986. https://doi.org/10.1007/978-1-4899-3324-9 |
| [68] | I. Soukarieh, S. Bouzebda, Weak convergence of the conditional $U$-statistics for locally stationary functional time series, Stat. Infer. Stoch. Process., 2022. |
| [69] |
W. Stute, L. X. Zhu, Nonparametric checks for single-index models, Ann. Statist., 33 (2005), 1048–1083. https://doi.org/10.1214/009053605000000020 doi: 10.1214/009053605000000020
|
| [70] |
Q. Tang, L. Kong, D. Rupper, R. J. Karunamuni, Partial functional partially linear single-index models, Statist. Sinica, 31 (2021), 107–133. https://doi.org/10.5705/ss.20 doi: 10.5705/ss.20
|
| [71] | M. P. Wand, M. C. Jones, Kernel Smoothing, London: Chapman and Hall, 1995. https://doi.org/10.1007/978-1-4899-4493-1 |
| [72] | Y. A. Wang, Q. Huang, Z. Yao, Y. Zhang, On a class of linear regression methods, J. Complexity, 2024, 101826. https://doi.org/10.1016/j.jco.2024.101826 |
| [73] | G. S. Watson, Smooth regression analysis, Sankhy\ = {a} Ser. A, 26 (1964), 359–372. |
| [74] |
Y. Zhang, B. Hofmann, On fractional asymptotical regularization of linear ill-posed problems in Hilbert spaces, Fract. Calc. Appl. Anal., 22 (2019), 699–721. https://doi.org/10.1515/fca-2019-0039 doi: 10.1515/fca-2019-0039
|
| [75] |
W. Zhou, J. Gao, D. Harris, H. Kew, Semi-parametric single-index predictive regression models with cointegrated regressors, J. Economet., 238 (2024), 105577. https://doi.org/10.1016/j.jeconom.2023.105577 doi: 10.1016/j.jeconom.2023.105577
|
| [76] |
H. Zhu, R. Zhang, Y. Liu, H. Ding, Robust estimation for a general functional single index model via quantile regression, J. Korean Statist. Soc., 51 (2022), 1041–1070. https://doi.org/10.1007/s42952-022-00174-4 doi: 10.1007/s42952-022-00174-4
|
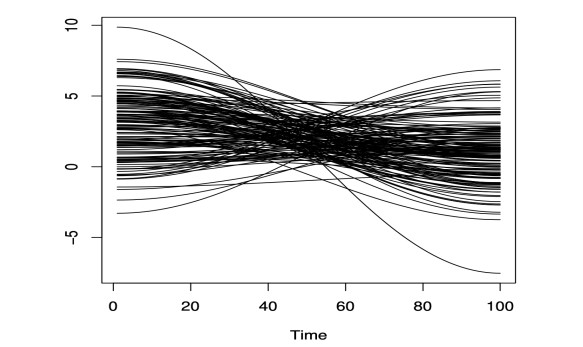





Figures(6)

Said Attaoui, Billal Bentata, Salim Bouzebda, Ali Laksaci. The strong consistency and asymptotic normality of the kernel estimator type in functional single index model in presence of censored data[J]. AIMS Mathematics, 2024, 9(3): 7340-7371. doi: 10.3934/math.2024356







 DownLoad:
DownLoad: