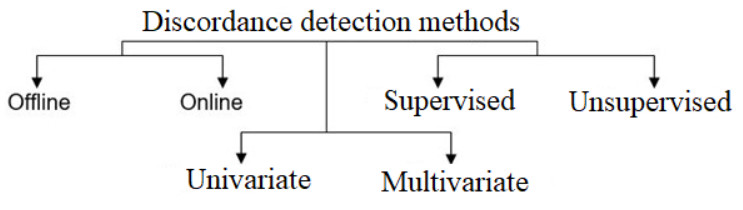
The detection of change points in chaotic and non-stationary time series presents a critical challenge for numerous practical applications, particularly in fields such as finance, climatology, and engineering. Traditional statistical methods, grounded in stationary models, are often ill-suited to capture the dynamics of processes governed by stochastic chaos. This paper explores modern approaches to change point detection, focusing on multivariate regression analysis and machine learning techniques. We demonstrate the limitations of conventional models and propose hybrid methods that leverage long-term correlations and metric-based learning to improve detection accuracy. Our study presents comparative analyses of existing early detection techniques and introduces advanced algorithms tailored to non-stationary environments, including online and offline segmentation strategies. By applying these methods to financial market data, particularly in monitoring currency pairs like EUR/USD, we illustrate how dynamic filtering and multiregression analysis can significantly enhance the identification of change points. The results underscore the importance of adapting detection models to the specific characteristics of chaotic data, offering practical solutions for improving decision-making in complex systems. Key findings reveal that while no universal solution exists for detecting change points in chaotic time series, integrating machine learning and multivariate approaches allows for more robust and adaptive forecasting models. The work highlights the potential for future advancements in neural network applications and multi-expert decision systems, further enhancing predictive accuracy in volatile environments.
Citation: Alexander Musaev, Dmitry Grigoriev, Maxim Kolosov. Adaptive algorithms for change point detection in financial time series[J]. AIMS Mathematics, 2024, 9(12): 35238-35263. doi: 10.3934/math.20241674
The detection of change points in chaotic and non-stationary time series presents a critical challenge for numerous practical applications, particularly in fields such as finance, climatology, and engineering. Traditional statistical methods, grounded in stationary models, are often ill-suited to capture the dynamics of processes governed by stochastic chaos. This paper explores modern approaches to change point detection, focusing on multivariate regression analysis and machine learning techniques. We demonstrate the limitations of conventional models and propose hybrid methods that leverage long-term correlations and metric-based learning to improve detection accuracy. Our study presents comparative analyses of existing early detection techniques and introduces advanced algorithms tailored to non-stationary environments, including online and offline segmentation strategies. By applying these methods to financial market data, particularly in monitoring currency pairs like EUR/USD, we illustrate how dynamic filtering and multiregression analysis can significantly enhance the identification of change points. The results underscore the importance of adapting detection models to the specific characteristics of chaotic data, offering practical solutions for improving decision-making in complex systems. Key findings reveal that while no universal solution exists for detecting change points in chaotic time series, integrating machine learning and multivariate approaches allows for more robust and adaptive forecasting models. The work highlights the potential for future advancements in neural network applications and multi-expert decision systems, further enhancing predictive accuracy in volatile environments.

| [1] |
C. Truong, L. Oudre, N. Vayatis, Selective review of offline change point detection methods, Signal Process., 167 (2020), 107299. https://doi.org/10.1016/j.sigpro.2019.107299 doi: 10.1016/j.sigpro.2019.107299

|
| [2] | K. A. Blount, L. Rush, Chaos theory, Entangled Crush, 2021. |
| [3] | B. Davies, Exploring chaos: theory and experiment, Studies in Nonlinearity, CRC Press, 2018. https://doi.org/10.1201/9780429502866 |
| [4] | D. Feldman, Chaos and dynamical systems, Princeton University Press, 2019. https://doi.org/10.1515/9780691189390 |
| [5] |
A. Musaev, D. Grigoriev, Analyzing, modeling, and utilizing observation series correlation in capital markets, Computation, 9 (2021), 88. https://doi.org/10.3390/computation9080088 doi: 10.3390/computation9080088
|
| [6] | H. Wold, A study in the analysis of stationary time series, 2 Eds., Almqvist & Wiksell, 1954. |
| [7] |
S. Aminikhanghahi, D. J. Cook, A survey of methods for time series change point detection, Knowl. Inf. Syst., 51 (2017), 339–367. https://doi.org/10.1007/s10115-016-0987-z doi: 10.1007/s10115-016-0987-z
|
| [8] | B. Namoano, A. Starr, C. Emmanouilidis, R. C. Cristobal, Online change detection techniques in time series: an overview, 2019 IEEE International Conference on Prognostics and Health Management (ICPHM), 2019. https://doi.org/10.1109/ICPHM.2019.8819394 |
| [9] | Mario Krause, Unsupervised Change Point Detection for heterogeneous sensor signals, arXiv Press, 2023. https://doi.org/10.48550/arXiv.2305.11976 |
| [10] |
F. Li, G. C. Runger, E. Tuv, Supervised learning for change-point detection, Int. J. Prod. Res., 44 (2006), 2853–2868. https://doi.org/10.1080/00207540600669846 doi: 10.1080/00207540600669846
|
| [11] |
A. Musaev, A. Makshanov, D. Grigoriev, The genesis of uncertainty: structural analysis of stochastic chaos in finance markets, Complexity, 2023 (2023), 1–16. https://doi.org/10.1155/2023/1302220 doi: 10.1155/2023/1302220
|
| [12] | R. M. Yusupov, A. A. Musaev, D. A. Grigoriev, Evaluation of statistical forecast method efficiency in the conditions of dynamic chaos, 2021 IV International Conference on Control in Technical Systems (CTS), 2021,178–180. https://doi.org/10.1109/CTS53513.2021.9562780 |
| [13] |
A. Musaev, D. Grigoriev, Numerical studies of statistical management decisions in conditions of stochastic chaos, Mathematics, 10 (2022), 226. https://doi.org/10.3390/math10020226 doi: 10.3390/math10020226
|
| [14] |
S. C. Huang, P. J. Chuang, C. F. Wu, H. J. Lai, Chaos-based support vector regressions for exchange rate forecasting, Expert Syst. Appl., 37 (2010), 8590–8598. https://doi.org/10.1016/j.eswa.2010.06.001 doi: 10.1016/j.eswa.2010.06.001
|
| [15] | A. Özkaya, Chaotic dynamics in Turkish foreign exchange markets, Bus. Manag. Stud. Int. J., 10 (2022), 787–795. |
| [16] |
A. Das, P. Das, Chaotic analysis of the foreign exchange rates, Appl. Math. Comput., 185 (2007), 388–396. https://doi.org/10.1016/j.amc.2006.06.106 doi: 10.1016/j.amc.2006.06.106
|
| [17] | E. E. Peters, Fractal market analysis: applying chaos theory to investment and economics, Wiley, 1994. |
| [18] | E. E. Peters, Chaos and order in the capital markets: a new view of cycles, prices, and market volatility, 2 Eds., John Wiley & Sons, 1996. |
| [19] | M. Basseville, I. V. Nikiforov, Detection of abrupt changes: theory and applications (Translated from English), Prentice-Hall, Inc., 1993. |
| [20] |
A. Aue, L. Horváth, Structural breaks in time series, J. Time Ser. Anal., 34 (2013), 1–16. https://doi.org/10.1111/j.1467-9892.2012.00819.x doi: 10.1111/j.1467-9892.2012.00819.x
|
| [21] | A. N. Shiryaev, Stochastic disorder problems, Moscow Center for Continuous Mathematical Education (MCNMO), 2019. |
| [22] | Y. G. Sinai, Probability theory: an introductory course, Springer Berlin, Heidelberg, 1992. https://doi.org/10.1007/978-3-662-02845-2 |
| [23] | M. C. Meyer, Probability and mathematical statistics: theory, applications, and practice in R, SIAM, 2019. https://doi.org/10.1137/1.9781611975789 |
| [24] |
M. Aloud, E. Tsang, R. Olsen, A. Dupuis, A directional-change event approach for studying financial time series, Economics, 6 (2012), 1–17, https://doi.org/10.5018/economics-ejournal.ja.2012-36 doi: 10.5018/economics-ejournal.ja.2012-36
|
| [25] |
A. Musaev, A. Makshanov, D. Grigoriev, Algorithms of sequential identification of system components in chaotic processes, Int. J. Dyn. Control, 11 (2023), 2566–2579. https://doi.org/10.1007/s40435-023-01121-9 doi: 10.1007/s40435-023-01121-9
|
| [26] |
T. G. Kang, P. D. Anderson, The effect of inertia on the flow and mixing characteristics of a chaotic serpentine mixer, Micromachines, 5 (2014), 1270–1286. https://doi.org/10.3390/mi5041270 doi: 10.3390/mi5041270
|
| [27] |
A. Musaev, A. Makshanov, D. Grigoriev, Exploring the quotation inertia in international currency markets, Computation, 11 (2023), 209. https://doi.org/10.3390/computation11110209 doi: 10.3390/computation11110209
|
| [28] | A. Musaev, D. Grigoriev, Multi-expert systems: Fundamental concepts and application examples, J. Theor. Appl. Inf. Technol., 100 (2022), 336–348. |
| [29] |
Z. Ivanovski, N. Ivanovska, Z. Narasanov, The regression analysis of stock returns at MSE, J. Mod. Account. Audit., 12 (2016), 217–224. https://doi.org/10.17265/1548-6583/2016.04.003 doi: 10.17265/1548-6583/2016.04.003
|
| [30] | J. Fang, Why logistic regression analyses are more reliable than multiple regression analyses, J. Bus. Econ., 4 (2013), 620–633. |
| [31] |
A. Musaev, A. Makshanov, D. Grigoriev, Statistical analysis of current financial instrument quotes in the conditions of market chaos, Mathematics, 10 (2022), 587. https://doi.org/10.3390/math10040587 doi: 10.3390/math10040587
|
| [32] |
R. F. Engle, C. W. J. Granger, Co-integration and error correction: Representation, estimation, and testing, Econometrica, 55 (1987), 251–276. https://doi.org/10.2307/1913236 doi: 10.2307/1913236
|
| [33] |
C. W. J. Granger, Some properties of time series data and their use in econometric model specification, J. Econometrics, 16 (1981), 121–130. https://doi.org/10.1016/0304-4076(81)90079-8 doi: 10.1016/0304-4076(81)90079-8
|
| [34] | L. J. Fogel, A. J. Owens, M. J. Walsh, Artificial intelligence through simulated evolution, John Wiley & Sons, 1966. |
| [35] |
A. Musaev, A. Makshanov, D. Grigoriev, Evolutionary optimization of control strategies for non-stationary immersion environments, Mathematics, 10 (2022), 1797. https://doi.org/10.3390/math10111797 doi: 10.3390/math10111797
|
| [36] |
M. A. Junior, P. Appiahene, O. Appiah, C. N. Bombie, Forex market forecasting using machine learning: Systematic literature review and meta-analysis, J. Big Data, 10 (2023), 9. https://doi.org/10.1186/s40537-022-00676-2 doi: 10.1186/s40537-022-00676-2
|
| [37] | A. A. Baasher, M. W. Fakhr, Forex trend classification using machine learning techniques, Proceedings of the 11th WSEAS international conference on Applied computer science, Stevens Point, WI, USA: World Scientific and Engineering Academy and Society (WSEAS), 1 (2011), 41–47. |
| [38] |
A. Musaev, E. Borovinskaya, Prediction in chaotic environments based on weak Musaev quadratic classifiers, Symmetry, 12 (2020), 1630. https://doi.org/10.3390/sym12101630 doi: 10.3390/sym12101630
|
| [39] |
A. Musaev, A. Makshanov, D. Grigoriev, Forecasting multivariate chaotic processes with precedent analysis, Computation, 9 (2021), 110. https://doi.org/10.3390/computation9100110 doi: 10.3390/computation9100110
|
| [40] | V. Niederhoffer, L. Kenner, Practical speculation, Wiley, 2005. |
| [41] | J. Chen, Essentials of technical analysis for financial markets, John Wiley & Sons, 2010. https://doi.org/10.1002/9781119204213 |
| [42] | R. Di Lorenzo, Basic technical analysis of financial markets, Springer, 2013. https://doi.org/10.1007/978-88-470-5421-9 |
| [43] |
I. K. Nti, A. F. Adekoya, B. A. Weyori, A systematic review of fundamental and technical analysis of stock market predictions, Artif. Intell. Rev., 53 (2020), 3007–3057. https://doi.org/10.1007/s10462-019-09754-z doi: 10.1007/s10462-019-09754-z
|
| [44] | B. Donnely, The art of currency trading: a professional's guide to the foreign exchange market, Wiley, 2019. |
| [45] | F. Escher, Elements of foreign exchange: a foreign exchange primer, Wentworth Press, 1917. |
| [46] | S. K. Parameswaran, Fundamentals of financial instruments: an introduction to stocks, bonds, foreign exchange, and derivatives, 2 Eds., Wiley, 2022. |
| [47] | K. Fukunaga, Introduction to statistical pattern recognition, 2Eds., Academic Press, 2013. |
| [48] | T. Hastie, R. Tibshirani, J. Friedman, The elements of statistical learning, 2 Eds., Springer, 2009. https://doi.org/10.1007/978-0-387-84858-7 |
| [49] |
D. Thakore, Conflict and conflict management, IOSR J. Bus. Manag., 8 (2013), 7–16. https://doi.org/10.9790/487X-0860716 doi: 10.9790/487X-0860716
|
| [50] | A. J. Jones, Game theory: mathematical models of conflict, Elsevier, 2000. |
| [51] | A. Skowron, S. Ramanna, J. F. Peters, Conflict analysis and information systems: a rough set approach, In: G. Y. Wang, J. F. Peters, A. Skowron, Y. Yao, Rough Sets Knowl. Technol., Springer, 2006. https://doi.org/10.1007/11795131_34 |
| [52] | G. Kunapuli, Ensemble methods for machine learning, Manning Publications, 2023. |
| [53] |
R. Fonseca, P. Gomez, Automatic model selection in ensembles for time series forecasting, IEEE Latin Am. Trans., 14 (2016), 3811–3819. https://doi.org/10.1109/TLA.2016.7786368 doi: 10.1109/TLA.2016.7786368
|
| [54] | M. P. Deisenroth, A. A. Faisal, Mathematics for machine learning, Cambridge University Press, 2020. https://doi.org/10.1017/9781108679930 |













Figures(14)

Alexander Musaev, Dmitry Grigoriev, Maxim Kolosov. Adaptive algorithms for change point detection in financial time series[J]. AIMS Mathematics, 2024, 9(12): 35238-35263. doi: 10.3934/math.20241674







 DownLoad:
DownLoad: