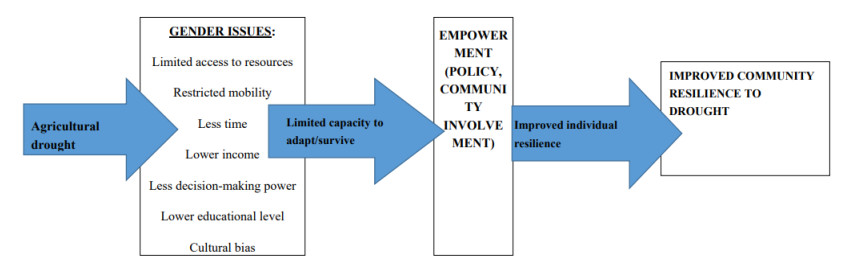
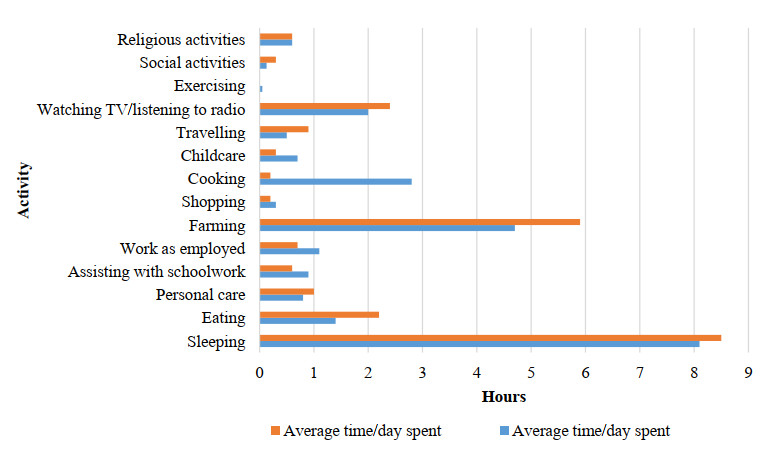
Studies have determined the factors influencing agricultural drought resilience of smallholder farmers and implications for empowerment. Other than the Abbreviated Women's Empowerment in Agriculture Index (A-WEAI), studies do not provide an analysis of cultural or traditional beliefs and reflective dialogues on challenges of smallholder female livestock farmers. This study uses a mixed approach that includes a survey, A-WEAI, Pearson's chi-square coefficient, and reflective dialogue to analyze these challenges. The ability to adapt to agricultural drought is influenced by factors such as access to information, credit, productive resources, and available time, all of which are different for men and women. Our study found that 61.3% and 16.4% of the female and male farmers were disempowered. Domains that contributed the most to the disempowerment of the women and men were respectively time/workload (52.97% and 31.89%), access to and decisions on credit (17.7% and 21.4%), ownership of assets (11.3% and 8.5%), input into productive decisions (10% and 9.1%) and group membership (8% and 19.13%). No significant correlation for age, marital status, or level of education versus empowerment status of women was found. A significant correlation was observed between farming experience and the empowerment status of women. Reflective dialogue during interviews revealed that women struggled with access to finance, grazing, water, stock theft, lack of training and knowledge, and intimidation by male neighbors. Such findings help inform agricultural development strategies to develop or modify existing policies to enhance the resilience of farmers to agricultural drought and empowerment. Gender-specific agricultural projects should be encouraged to empower female farmers to improve their resilience to agricultural drought. The government should assist female livestock farmers in accessing credit and developing clear policies on land tenure issues. Mentorship programs should be encouraged to educate and support female smallholder farmers to enhance their agricultural drought resilience and empowerment.
Citation: Lindie V. Maltitz, Yonas T. Bahta. Empowerment of smallholder female livestock farmers and its potential impacts to their resilience to agricultural drought[J]. AIMS Agriculture and Food, 2021, 6(2): 603-630. doi: 10.3934/agrfood.2021036
Studies have determined the factors influencing agricultural drought resilience of smallholder farmers and implications for empowerment. Other than the Abbreviated Women's Empowerment in Agriculture Index (A-WEAI), studies do not provide an analysis of cultural or traditional beliefs and reflective dialogues on challenges of smallholder female livestock farmers. This study uses a mixed approach that includes a survey, A-WEAI, Pearson's chi-square coefficient, and reflective dialogue to analyze these challenges. The ability to adapt to agricultural drought is influenced by factors such as access to information, credit, productive resources, and available time, all of which are different for men and women. Our study found that 61.3% and 16.4% of the female and male farmers were disempowered. Domains that contributed the most to the disempowerment of the women and men were respectively time/workload (52.97% and 31.89%), access to and decisions on credit (17.7% and 21.4%), ownership of assets (11.3% and 8.5%), input into productive decisions (10% and 9.1%) and group membership (8% and 19.13%). No significant correlation for age, marital status, or level of education versus empowerment status of women was found. A significant correlation was observed between farming experience and the empowerment status of women. Reflective dialogue during interviews revealed that women struggled with access to finance, grazing, water, stock theft, lack of training and knowledge, and intimidation by male neighbors. Such findings help inform agricultural development strategies to develop or modify existing policies to enhance the resilience of farmers to agricultural drought and empowerment. Gender-specific agricultural projects should be encouraged to empower female farmers to improve their resilience to agricultural drought. The government should assist female livestock farmers in accessing credit and developing clear policies on land tenure issues. Mentorship programs should be encouraged to educate and support female smallholder farmers to enhance their agricultural drought resilience and empowerment.

| [1] |
Freire-González J, Decker C, Hall J (2017) The economic impacts of droughts: A framework for analysis. Ecol Econ 132: 196-204. doi: 10.1016/j.ecolecon.2016.11.005

|
| [2] |
Logan I, van den Bergh J (2013) Methods to assess costs of drought damages and policies for drought mitigation and adaptation: Review and recommendations. Water Resour Manag 27: 1707-1720. doi: 10.1007/s11269-012-0119-9
|
| [3] | FAO (Food and Agricultural Organization of the United Nations) (2013) UN lays foundations for more drought resilient societies. Meeting urges disaster risk reduction instead of crisis management. Available from: https://www.fao.org/news/story/en/item/172030/icode/ (Accessed 30 March 2021). |
| [4] | Ferrari E, McDonald S, Osman R (2016) Water scarcity and irrigation efficiency in Egypt. Water Econ Pol 2: 165009. |
| [5] | Gunst L, Castro Rego F, et al. (2015) Impact of meteorological drought on crop yield on pan-European scale, 1979-2009. In: Andreu J, Solera A, Paredes-Arquiola J, et al. (Eds.), Drought: Research and Science-Policy Interfacing, CRC Press, Taylor & Francis Group, London. |
| [6] | Mendelsohn R, Dinar A (2009) Climate change and agriculture: An economic analysis of global impacts, adaptation and distributional effects. Edward Elgar, Cheltenham, UK. |
| [7] |
Musolino A, Massarutto A, de Carli A (2018) Does drought always cause economic losses in agriculture? An empirical investigation on the distributive effects of drought events in some areas of Southern Europe. Sci Total Environ 633: 1560-1570. doi: 10.1016/j.scitotenv.2018.02.308
|
| [8] |
Salami H, Shahnooshi N, Thomson KJ (2008) The economic impacts of drought on the economy of Iran: An integration of linear programming and macroeconomic modelling approaches. Ecol Econ 68: 1032-1039. doi: 10.1016/j.ecolecon.2008.12.003
|
| [9] | Yu C, Huang X, Chen H, et al. (2018) Assessing the impacts of extreme agricultural droughts in China under climate and socioeconomic changes. Earth's Future 6: 689-703. |
| [10] |
Erfurt M, Glaser R, Blauhut V (2019) Changing impacts and societal responses to drought in southwestern Germany since 1800. Reg Environ Change 19: 2311-2323. doi: 10.1007/s10113-019-01522-7
|
| [11] | van Niekerk D, Tempelhoff J, Faling W, et al. (2009) The effects of climate change in two flood laden and drought stricken areas in South Africa: Responses to climate change—past, present and future. Report to the National Disaster Management Centre. African Centre for Disaster Studies, Potchefstroom. |
| [12] |
Bahta YT (2020) Smallholder livestock farmers coping and adaptation strategies to agricultural drought. AIMS Agric Food 5: 964-982. doi: 10.3934/agrfood.2020.4.964
|
| [13] |
Ahmadalipour A, Moradkhani H, Castelletti A, et al. (2019) Future drought risk in Africa: Integrating vulnerability, climate change, and population growth. Sci Total Environ 662: 672-686. doi: 10.1016/j.scitotenv.2019.01.278
|
| [14] |
Perez C, Jones EM, Kristjanson P, et al. (2015) How resilient are farming households and communities to a changing climate in Africa? A gender-based perspective. Global Environ Chang 34: 95-107. doi: 10.1016/j.gloenvcha.2015.06.003
|
| [15] | Parker H, Oates N, Mason N, et al. (2016) Gender, agriculture and water insecurity. Available from: https://www.odi.org/sites/odi.org.uk/files/resource-documents/10356.pdf (Accessed 10 April 2020). |
| [16] | IPCC (Intergovernmental Panel on Climate Change) (2018) Special report: Global warming of 1.5 ℃. Available from: https://www.ipcc.ch/sr15/ (Accessed 2 July 2020). |
| [17] | Southwick SM, Bonanno GA, Masten AS, et al. (2014) Resilience definitions, theory, and challenges: Interdisciplinary perspectives. Eur J Psychotraumatol 5: PMC4185134. |
| [18] |
Mutero J, Munapo E, Seaketso P (2016) Operational challenges faced by smallholder farmers: A case of Ethekwini Metropolitan of South Africa. Environ Eco 7: 40-52. doi: 10.21511/ee.07(2).2016.4
|
| [19] | Habtezion S (2016) Gender and climate change: Overview of linkages between gender and climate change. United Nations Development Programme. Available from: https://www.undp.org/content/dam/undp/library/gender/Gender%20and%20Environment/UNDP%20Linkages%20Gender%20and%20CC%20Policy%20Brief%201-WEB.pdf (Accessed 10 May 2020). |
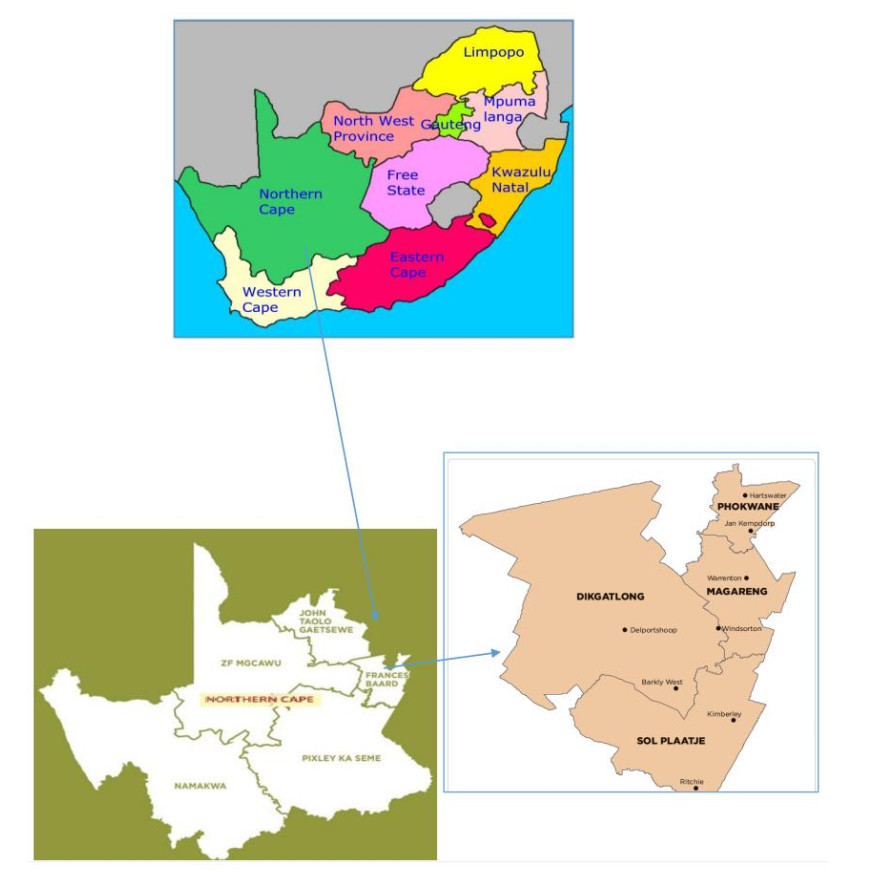
| [20] | Von Maltitz L (2020) The resilience of female smallholder livestock farmers to agricultural drought in the Northern Cape, South Africa. MSc. Dissertation, University of the Free State, South Africa. |
| [21] | DAFF (Department of Agriculture, Forestry, and Fisheries) (2012) A framework for the development of smallholder farmers through cooperatives development. Pretoria, South Africa. |
| [22] | Matlou RC, Bahta YT (2019) Factors influencing the resilience of smallholder livestock farmers to agricultural drought in South Africa: Implication for adaptive capabilities. J Disast Risk Stud 11: art805. |
| [23] | Stats SA (Statistics South Africa) (2019) Labour Force Survey. Pretoria: Statistics South Africa. |
| [24] | Stats SA (Statistics South Africa) (2016) Community Survey 2016: Provincial Profile Northern Cape, Report No. 03-01-14. Pretoria: Statistics South Africa. |
| [25] | Opondo M, Abdi U, Nangiro P (2016) Assessing gender in resilience programming: Uganda. Resilience Intel, Part of the BRACED Knowledge Manager Series. Available from: https://www.odi.org/sites/odi.org.uk/files/odi-assets/publications-opinion-files/10215.pdf (Accessed 10 April 2020). |
| [26] | Theis BYS, Martinez E (2018) How gender shapes responses to climate change : New tools for measuring rural women's empowerment. IFPRI Blog Issue Post. Available from: http://www.ifpri.org/blog/how-gender-shapes-responses-climate-change-new-tools-measuring-rural-womens-empowerment (Accessed 25 April 2020). |
| [27] | Le Masson V (2016) Gender and resilience: From theory to practice. In BRACED Knowledge Manager. Available from: https://www.odi.org/publications/9967-gender-and-resilience-theory-practice (Accessed on 21 April 2020). |
| [28] | DRDLR (Department of Rural Development and Land Reform) (2017) Land Audit Report. Phase II: Private Land Ownership by Race, Gender and Nationality. Version 2. Pretoria: South Africa. |
| [29] | CARE (2016) Enhancing resilience through gender equality. Gender equality and women's voice in asia-pacific resilience programming. Research report. Available from: https://careclimatechange.org/wp-content/uploads/2016/08/enhancing-resilience.pdf (Accessed 14 June 2020). |
| [30] | Ugwu P (2019) Women in agriculture: Challenges facing women in African farming. Research report: Postgraduate school of agricultural and food economics, Catholic University of the Sacred Heart, Italy. |
| [31] | Le Masson V, Norton A, Emily W (2012) Gender and resilience. In BRACED Knowledge Manager. Available from: https://www.odi.org/sites/odi.org.uk/files/odi-assets/publications-opinion-files/9890.pdf (Accessed on 25 September 2020). |
| [32] |
Khapung S (2016) Transnational feminism and women's activism: Building resilience to climate change impact through women's empowerment in climate-smart agriculture. Asian J Women Stud 22: 497-506. doi: 10.1080/12259276.2016.1242946
|
| [33] |
Ravera F, Iniesta-Arandia I, Martin-Lopez B, et al. (2016) Gender perspectives in resilience, vulnerability and adaptation to global environmental change. Ambio 45: 235-247. doi: 10.1007/s13280-016-0842-1
|
| [34] |
Price M, Galie A, Marshall J, et al. (2018) Elucidating linkages between women's empowerment in livestock and nutrition: a qualitative study. Dev in Practice 28: 510-524. doi: 10.1080/09614524.2018.1451491
|
| [35] | Quandt A (2018) Variability in perceptions of household livelihood resilience and drought at the intersection of gender and ethnicity. Climatic Change 152: 1-16. |
| [36] | Lambrecht I, Schuster M, Asare S, et al. (2017) Changing gender roles in agriculture? Evidence from 20 years of data in Ghana. Discussion Paper 01623, International Food Policy Research Institute. Available from: http://ebrary.ifpri.org/utils/getfile/collection/p15738coll2/id/131105/filename/131316.pdf (Accessed on 13 May 2020). |
| [37] | UNFCCC (United Nations Framework Convention on Climate Change) (2019) Building resilient livelihood in Sudan. Available from: https://unfccc.int/climate-action/momentum-for-change/women-for-results/building-resielient-livelihoods-i-sudan (Accessed 15 April 2020). |
| [38] |
Wouterse F (2019) The role of empowerment in agricultural production: evidence from rural households in Niger. J Dev Stud 55: 565-580. doi: 10.1080/00220388.2017.1408797
|
| [39] |
Luthar SS Cicchetti D (2000) The construct of resilience: Implications for interventions and social policies. Dev Psychopathol 12: 857-885. doi: 10.1017/S0954579400004156
|
| [40] |
Keil A, Zeller M, Wida A, et al. (2007) What determines farmers' resilience towards ENSO-related drought? An empirical assessment in Central Sulawesi, Indonesia. Climatic Change 86: 291-307. doi: 10.1007/s10584-007-9326-4
|
| [41] |
Lokosang L, Ramroop S, Zewotir T (2014) Indexing household resilience to food insecurity shocks: The case of South Sudan. Agrekon 53: 137-159. doi: 10.1080/03031853.2014.915486
|
| [42] | Lieber E (2009) Mixing qualitative and quantitative methods: Insights into design and analysis issues.J Ethnographic Qual Res 3(4): 218-227. |
| [43] | Mason KO (2005) Measuring women's empowerment: Learning from cross-national research. In: Narayan D, (ed.), Measuring empowerment: Cross-disciplinary perspectives, Washington, DC: World Bank, 89-102. |
| [44] | FBDM (Frances Baard Municipal District Municipality) (2019) Frances Baard Municipal District in the Northern Cape. Kimberly, South Africa. Available from: https://municipalities.co.za/map/134/frances-baard-district-municipality (Accessed 31 March 2021). |
| [45] | DAFF (Department of Agriculture, Forestry and Fisheries) (2018) Drought status in the agriculture sector. Portfolio Committee on Water and Sanitation. Pretoria, South Africa. |
| [46] | Malapit H, Kovarik C, Sproule K, et al. (2015). Instructional guide on the abbreviated women's empowerment in Agriculture Index (A-WEAI). World Dev 52: 71-91. |
| [47] | Cochran WG (1977) Sampling techniques, 3de Edition. New York: John Wiley and Sons. |
| [48] | Bartlett JE, Kotrick JW, Higgins CC (2001) Organizational research : Determining appropriate sample size in survey research. Inf Technol Learn Perform J 19: 43-50. |
| [49] | Northern Cape Department of Agriculture (2019) List of smallholder women livestock farmers. Kimberly, South Africa. |
| [50] | Alkire S, Meinzen-Dick R, Peterman A, et al. (2013) The women's empowerment in Agriculture Index. World Dev 52: 71-91. |
| [51] | Malhotra A, Schuler SR (2005) Women's empowerment as a variable in international development. In: Narayan D, (ed.), Measuring empowerment: Cross-disciplinary perspectives, Washington, DC: World Bank, 71-88. |
| [52] | SNV Netherlands (Stichting Nederlandse Vrijwilligers) (2017) Empowering women in agribusiness through social and behavioral change. Available from: http://www.snv.org/public/cms/sites/default/files/explore/download/empowering_women_in_agribusiness_through_social_behaviour_change_kenya_vietnam.pdf (Accessed on 21 October 2020). |
| [53] | Petesch P, Smulovitz C, Walton M (2005) Evaluating empowerment: A framework with cases from Latin America. In: Narayan D, (ed.), Measuring empowerment: Cross-disciplinary perspectives, Washington, DC: World Bank, 39-67. |
| [54] | Anderson H (2014) Collaborative-dialogue based research as everyday practice: Questioning our myths. In: Simon G, Chard A, (ed.), Systemic Inquiry Innovations in Reflexive Practice Research, Farnhill, UK, 60-73. |
| [55] |
Metelerkamp L, Drimie S, Biggs R (2019) We're ready, the system's not—youth perspectives on agricultural careers in South Africa. Agrekon 58: 154-179. doi: 10.1080/03031853.2018.1564680
|
| [56] |
Achandi EL, Kidane A, Hepelwa A, et al. (2019) Women's empowerment: The case of smallholder rice farmers in Kilombero District, Tanzania. Agrekon 58: 324-339. doi: 10.1080/03031853.2019.1587484
|
| [57] | Nabikolo D, Bashaasha B, Mangheni MN, et al. (2012) Determinants of climate change adaptation among male and female-headed farm households in Eastern Uganda. Afr Crop Sci J 20: 203-212. |
| [58] | Leder S (2015) Linking women's empowerment and their resilience. Literature review. International Water Management Institute (IWMI), Nepal, South Asia. |
| [59] | Isaga N (2018) Access to bank credit by smallholder farmers in Tanzania: A case study. Afrika Focus 31: 241-256. |
| [60] |
Johnson NL, Kovarik C, Meinzen-Dick R, et al. (2016) Gender, assets, and agricultural development: Lessons from eight projects. World Dev 83: 295-311. doi: 10.1016/j.worlddev.2016.01.009
|
| [61] |
Anderson CL, Reynolds TW, Gugerty MK (2017) Husband and wife perspectives on farm household decision-making authority and evidence on Intra-household Accord in Rural Tanzania. World Dev 90: 169-183. doi: 10.1016/j.worlddev.2016.09.005
|
| [62] |
Huyer S (2016) Closing the gender gap in agriculture. Gender Techn Dev 20: 105-116. doi: 10.1177/0971852416643872
|
| [63] |
Fisher M, Carr ER (2015) The influence of gendered roles and responsibilities on the adoption of technologies that mitigate drought risk: The case of drought-tolerant maize seed in eastern Uganda. Global Environ Chang 35: 82-92. doi: 10.1016/j.gloenvcha.2015.08.009
|
| [64] | Shean A, Alnouri S (2014) Rethinking resilience: Prioritizing gender integration to enhance household and community resilience to food insecurity in the Sahel. Available from: https://www.mercycorps.org/research-resources/rethinking-resilience (Accessed on 12 April 2020). |
| [65] | Tambo JA (2016) Adaptation and resilience to climate change and variability in north-east Ghana. Int J Disast Risk Re 17: 85-94. |
| [66] | Hassen A (2008) Vulnerability to drought risk and famine: Local responses and external interventions among the afar of Ethiopia, a study on the Aghini pastoral community. Ph.D. thesis, University of Bayreuth, Germany. |
| [67] | Bahta YT, Jordaan A, Muyambo F (2016) Communal farmers' perception of drought in South Africa: Policy implication for drought risk reduction. Int J Disast Risk Re 20: 39-50. |
| [68] | Iglesias A, Moneo M, Quiroga S (2007) Methods for evaluating social vulnerability to drought, Opt Méditerr Ser B 58: 129-133. |
| [69] |
Galiè A, Teufel N, Korir L, et al. (2018) The women's empowerment in Livestock Index. Soc Indic Res 142: 799-825. doi: 10.1007/s11205-018-1934-z
|
| [70] |
Akter S, Rutsaert P, Luis J, et al. (2017) Women's empowerment and gender equity in agriculture: A different perspective from Southeast Asia. Food Policy 69: 270-279. doi: 10.1016/j.foodpol.2017.05.003
|
| [71] |
van den Bold M, Dillon A, Olney D, et al. (2015) Can integrated agriculture-nutrition programs change gender norms on land and asset ownership? Evidence from Burkina Faso. J Dev Stud 51: 1155-1174. doi: 10.1080/00220388.2015.1036036
|
| [72] |
Opiyo FEO, Wasonga OV, Nyangito MM (2014) Measuring household vulnerability to climate-induced stresses in pastoral rangelands of Kenya: Implications for resilience programming. Pastoralism 4: 1-15. doi: 10.1186/2041-7136-4-1
|
| [73] |
Mustaffa CS, Asyiek F (2015) Conceptualizing framework for women empowerment in indonesia: Integrating the role of media, interpersonal communication, cosmopolite, extension agent and culture as predictors variables. Asian Soc Sci 11: 225-239. doi: 10.5539/ass.v11n16p225
|
| [74] |
Bhattarai B, Beilin R, Ford R (2015) Gender, agrobiodiversity, and climate change: A study of adaptation practices in the Nepal Himalayas. World Dev 70: 122-132. doi: 10.1016/j.worlddev.2015.01.003
|
Figures(3) / Tables(9)

Lindie V. Maltitz, Yonas T. Bahta. Empowerment of smallholder female livestock farmers and its potential impacts to their resilience to agricultural drought[J]. AIMS Agriculture and Food, 2021, 6(2): 603-630. doi: 10.3934/agrfood.2021036







 DownLoad:
DownLoad: