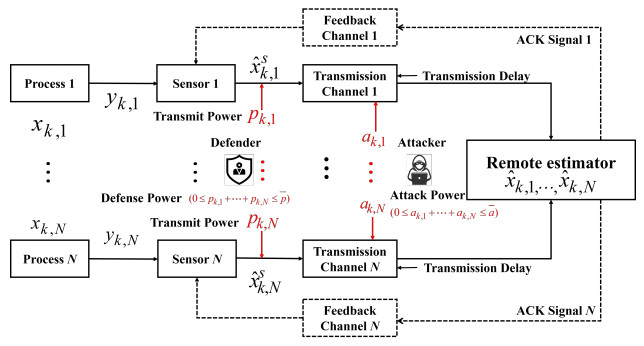
In cyber-physical systems, the state information from multiple processes is sent simultaneously to remote estimators through wireless channels. However, with the introduction of open media such as wireless networks, cyber-physical systems may become vulnerable to denial-of-service attacks, which can pose significant security risks and challenges to the systems. To better understand the impact of denial-of-service attacks on cyber-physical systems and develop corresponding defense strategies, several research papers have explored this issue from various perspectives. However, most current works still face three limitations. First, they only study the optimal strategy from the perspective of one side (either the attacker or defender). Second, these works assume that the attacker possesses complete knowledge of the system's dynamic information. Finally, the power exerted by both the attacker and defender is assumed to be small and discrete. All these limitations are relatively strict and not suitable for practical applications. In this paper, we addressed these limitations by establishing a continuous power game problem of a denial-of-service attack in a multi-process cyber-physical system with asymmetric information. We also introduced the concept of the age of information to comprehensively characterize data freshness. To solve this problem, we employed the multi-agent deep deterministic policy gradient algorithm. Numerical experiments demonstrate that the algorithm is effective for solving the game problem and exhibits convergence in multi-agent environments, outperforming other algorithms.
Citation: Zhiqiang Hang, Xiaolin Wang, Fangfei Li, Yi-ang Ren, Haitao Li. Learning-based DoS attack game strategy over multi-process systems[J]. Mathematical Modelling and Control, 2024, 4(4): 424-438. doi: 10.3934/mmc.2024034
In cyber-physical systems, the state information from multiple processes is sent simultaneously to remote estimators through wireless channels. However, with the introduction of open media such as wireless networks, cyber-physical systems may become vulnerable to denial-of-service attacks, which can pose significant security risks and challenges to the systems. To better understand the impact of denial-of-service attacks on cyber-physical systems and develop corresponding defense strategies, several research papers have explored this issue from various perspectives. However, most current works still face three limitations. First, they only study the optimal strategy from the perspective of one side (either the attacker or defender). Second, these works assume that the attacker possesses complete knowledge of the system's dynamic information. Finally, the power exerted by both the attacker and defender is assumed to be small and discrete. All these limitations are relatively strict and not suitable for practical applications. In this paper, we addressed these limitations by establishing a continuous power game problem of a denial-of-service attack in a multi-process cyber-physical system with asymmetric information. We also introduced the concept of the age of information to comprehensively characterize data freshness. To solve this problem, we employed the multi-agent deep deterministic policy gradient algorithm. Numerical experiments demonstrate that the algorithm is effective for solving the game problem and exhibits convergence in multi-agent environments, outperforming other algorithms.

| [1] |
M. Huang, K. Ding, S. Dey, Y. Li, L. Shi, Learning-based DoS attack power allocation in multiprocess systems, IEEE Trans. Neural Networks Learn. Syst., 34 (2023), 8017–8030. https://doi.org/10.1109/TNNLS.2022.3148924 doi: 10.1109/TNNLS.2022.3148924

|
| [2] |
M. Huang, K. Tsang, Y. Li, L. Li, L. Shi, Strategic DoS attack in continuous space for cyber-physical systems over wireless networks, IEEE Trans. Signal Inf. Process. Networks, 8 (2022), 421–432. https://doi.org/10.1109/TSIPN.2022.3174969 doi: 10.1109/TSIPN.2022.3174969
|
| [3] | D. Möller, H. Vakilzadian, Cyber-physical systems in smart transportation, 2016 IEEE International Conference on Electro Information Technology (EIT), 2016. https://doi.org/10.1109/EIT.2016.7535338 |
| [4] | A. Kasun, W. Chathurika, M. Daniel, R. Craig, M. Milos, Framework for data driven health monitoring of cyber-physical systems, 2018 Resil Week (RWS), 2018, 25–30. https://doi.org/10.1109/rweek.2018.8473535 |
| [5] |
G. Liang, R. W. Steven, J. Zhao, F. Luo, Z. Dong, The 2015 Ukraine blackout: implications for false data injection attacks, of cyber-physical systems, IEEE Trans. Power Syst., 32 (2017), 3317–3318. https://doi.org/10.1109/TPWRS.2016.2631891 doi: 10.1109/TPWRS.2016.2631891
|
| [6] |
I. Stojmenovic, S. Wen, X. Huang, H. Luan, An overview of Fog computing and its security issues, Concurrency Comput. Practice Exper., 28 (2016), 2991–3005. https://doi.org/10.1002/cpe.3485 doi: 10.1002/cpe.3485
|
| [7] | P. Griffioen, S. Weerakkody, O. Ozel, Y. Mo, B. Sinopoli, A tutorial on detecting security attacks on cyber-physical systems, 2019 18th European Control Conference (ECC), 2019,979–984. https://doi.org/10.23919/ecc.2019.8796117 |
| [8] |
J. Qin, M. Li, L. Shi, X. Yu, Optimal denial-of-service attack scheduling with energy constraint over packet-dropping networks, IEEE Trans. Autom. Control, 63 (2018), 1648–1663. https://doi.org/10.1109/TAC.2017.2756259 doi: 10.1109/TAC.2017.2756259
|
| [9] |
H. Zhang, P. Cheng, L. Shi, J. Chen, Optimal denial-of-service attack scheduling with energy constraint, IEEE Trans. Autom. Control, 60 (2015), 3023–3028. https://doi.org/10.1109/TAC.2015.2409905 doi: 10.1109/TAC.2015.2409905
|
| [10] |
S. Li, C. K. Ahn, Z. Xiang, Decentralized sampled-data control for cyber-physical systems subject to DoS attacks, IEEE Syst. J., 15 (2021), 5126–5134. https://doi.org/10.1109/JSYST.2020.3019939 doi: 10.1109/JSYST.2020.3019939
|
| [11] | Y. Mo, B. Sinopoli, L. Shi, E. Garone, Infinite-horizon sensor scheduling for estimation over lossy networks, 2012 IEEE 51st IEEE Conference on Decision and Control (CDC), 2012, 3317–3322. https://doi.org/10.1109/cdc.2012.6425859 |
| [12] |
R. Gan, Y. Xiao, J. Shao, J. Qin, An analysis on optimal attack schedule based on channel hopping scheme in cyber-physical systems, IEEE Trans. Cybern., 51 (2021), 994–1003. https://doi.org/10.1109/TCYB.2019.2914144 doi: 10.1109/TCYB.2019.2914144
|
| [13] |
X. Ren, J. Wu, S. Dey, L. Shi, Attack allocation on remote state estimation in multi-systems: structural results and asymptotic solution, Automatica, 87 (2018), 184–194. https://doi.org/10.1016/j.automatica.2017.09.021 doi: 10.1016/j.automatica.2017.09.021
|
| [14] | Z. Guo, J. Wang, L. Shi, Optimal denial-of-service attack on feedback channel against acknowledgment-based sensor power schedule for remote estimation, 2017 IEEE 56th Annual Conference on Decision and Control (CDC), 2017. https://doi.org/10.1109/cdc.2017.8264567 |
| [15] | X. Wang, J. He, S. Zhu, C. Chen, X. Guan, Learning-based attack schedule against remote state estimation in cyber-physical systems, 2019 American Control Conference (ACC), 2019, 4503–4508. https://doi.org/10.23919/acc.2019.8814961 |
| [16] |
X. Wang, C. Chen, J. He, S. Zhu, X. Guan, Learning-based online transmission path selection for secure estimation in edge computing systems, IEEE Trans. Ind. Inf., 17 (2021), 3577–3587. https://doi.org/10.1109/TII.2020.3012090 doi: 10.1109/TII.2020.3012090
|
| [17] |
P. Dai, W. Yu, H. Wang, G. Wen, Y. Lv, Distributed reinforcement learning for cyber-physical system With multiple remote state estimation under DoS attacker, IEEE Trans. Networks Sci. Eng., 7 (2020), 3212–3222. https://doi.org/10.1109/TNSE.2020.3018871 doi: 10.1109/TNSE.2020.3018871
|
| [18] |
J. Clifton, E. Laber, $Q$-Learning: theory and applications, Ann. Rev. Stat. Appl., 7 (2020), 279–301. https://doi.org/10.1146/annurev-statistics-031219-041220 doi: 10.1146/annurev-statistics-031219-041220
|
| [19] |
L. Wang, X. Liu, T. Li, J. Zhu, Skew-symmetric games and symmetric-based decomposition of finite games, Math. Modell. Control, 2 (2022), 257–267. https://doi.org/10.3934/mmc.2022024 doi: 10.3934/mmc.2022024
|
| [20] |
Z. Yue, L. Dong, S. Wang, Stochastic persistence and global attractivity of a two-predator one-prey system with $S$-type distributed time delays, Math, Modell. Control, 2 (2022), 272–281. https://doi.org/10.3934/mmc.2022026 doi: 10.3934/mmc.2022026
|
| [21] |
K. Ding, X. Ren, D. Quevedo, S. Dey, L. Shi, DoS attacks on remote state estimation with asymmetric information, IEEE Trans. Control Networks, 6 (2019), 653–666. https://doi.org/10.1109/TCNS.2018.2867157 doi: 10.1109/TCNS.2018.2867157
|
| [22] | J. Champati, M. Mamduhi, K. Johansson, J. Gross, Performance characterization using AoI in a single-loop networked control system, IEEE INFOCOM 2019-IEEE Conference on Computer Communications Workshops, 2019,197–203. https://doi.org/10.1109/infcomw.2019.8845114 |
| [23] |
Q. He, D. Yuan, A. Ephremides, Optimal link scheduling for age minimization in wireless systems, IEEE Trans. Inf. Theory, 64 (2018), 5381–5394. https://doi.org/10.1109/TIT.2017.2746751 doi: 10.1109/TIT.2017.2746751
|
| [24] |
Y. Sun, E. Uysal-Biyikoglu, R. Yates, C. Koksal, N. Shroff, Update or wait: how to keep your data fresh, IEEE Trans. Inf. Theory, 63 (2017), 7492–7508. https://doi.org/10.1109/TIT.2017.2735804 doi: 10.1109/TIT.2017.2735804
|
| [25] |
X. Wang, C. Chen, J. He, S. Zhu, X. Guan, AoI-aware control and communication co-design for industrial IoT systems, IEEE Int. Things J., 8 (2021), 8464–8473. https://doi.org/10.1109/JIOT.2020.3046742 doi: 10.1109/JIOT.2020.3046742
|
| [26] |
L. Shi, P. Cheng, J. Chen, Sensor data scheduling for optimal state estimation with communication energy constraint, Automatica, 47 (2011), 1693–1698. https://doi.org/10.1016/j.automatica.2011.02.037 doi: 10.1016/j.automatica.2011.02.037
|
| [27] |
L. Shi, L. Xie, Optimal sensor power scheduling for state estimation of Gauss-Markov systems over a packet-dropping network, IEEE Trans. Signal Process., 60 (2012), 2701–2705. https://doi.org/10.1109/TSP.2012.2184536 doi: 10.1109/TSP.2012.2184536
|
| [28] |
L. Shi, L. Xie, R. Murray, Kalman filtering over a packet-delaying network: a probabilistic approach, Automatica, 45 (2009), 2134–2140. https://doi.org/10.1016/j.automatica.2009.05.018 doi: 10.1016/j.automatica.2009.05.018
|
| [29] |
L. Peng, L. Shi, X. Cao, C. Sun, Optimal attack energy allocation against remote state estimation, IEEE Trans. Autom. Control, 63 (2018), 2199–2205. https://doi.org/10.1109/TAC.2017.2775344 doi: 10.1109/TAC.2017.2775344
|
| [30] | R. Sutton, G. Andrew, Reinforcement learning: an introduction, MIT Press, 1998. |
| [31] |
K. Hazeghi, M. Puterman, Markov decision processes: discrete stochastic dynamic programming, J. Amer. Stat. Assoc., 90 (1995), 392. https://doi.org/10.2307/2291177 doi: 10.2307/2291177
|
| [32] | H. Tan, Reinforcement learning with deep deterministic policy gradient, 2021 International Conference on Artificial Intelligence, Big Data and Algorithms (CAIBDA), 2021, 82–85. https://doi.org/10.1109/CAIBDA53561.2021.00025 |
| [33] |
B. Shalabh, R. Sutton, M. Ghavamzadeh, M. Lee, Natural actor-critic algorithms, Automatica, 45 (2009), 2471–2482. https://doi.org/10.1016/j.automatica.2009.07.008 doi: 10.1016/j.automatica.2009.07.008
|
| [34] |
A. Rodriguez-Ramos, C. Sampedro, H. Bavle, P. de la Puente, P. Campoy, A deep reinforcement learning strategy for UAV autonomous landing on a moving platform, J. Intell. Robot. Syst., 93 (2019), 351–366. https://doi.org/10.1007/s10846-018-0891-8 doi: 10.1007/s10846-018-0891-8
|











Figures(12) / Tables(4)
Zhiqiang Hang, Xiaolin Wang, Fangfei Li, Yi-ang Ren, Haitao Li. Learning-based DoS attack game strategy over multi-process systems[J]. Mathematical Modelling and Control, 2024, 4(4): 424-438. doi: 10.3934/mmc.2024034







 DownLoad:
DownLoad: