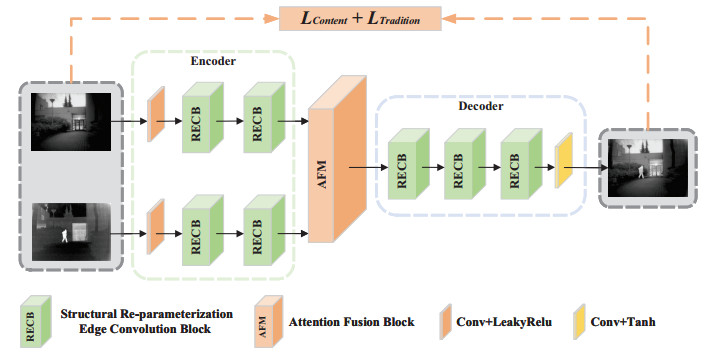
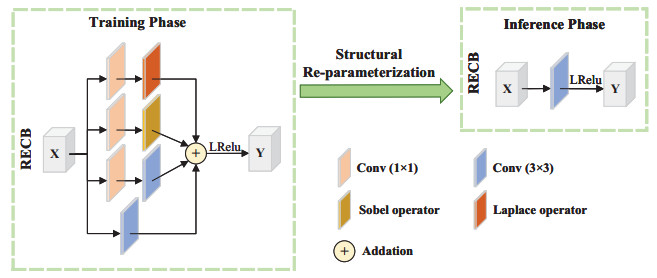
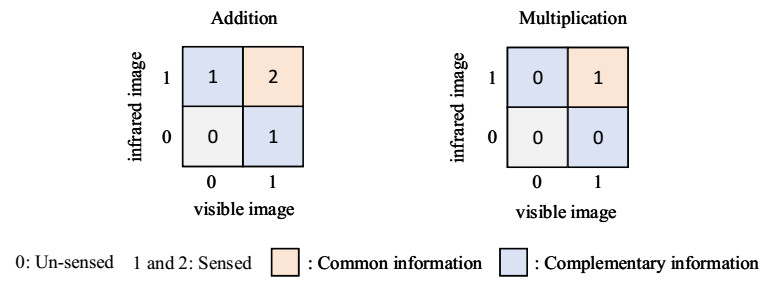
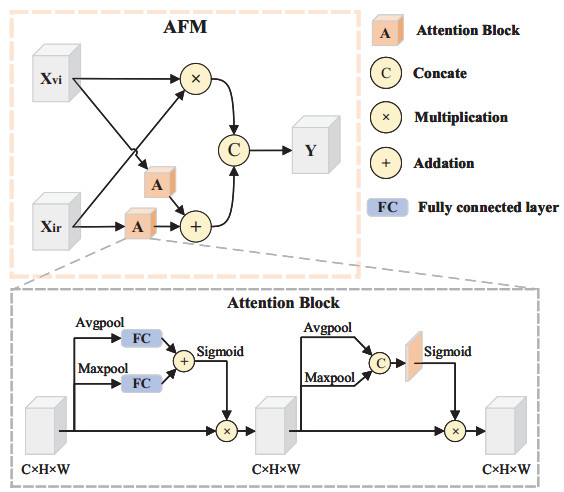
The purpose of infrared and visible image fusion is to integrate the complementary information from heterogeneous images in order to enhance their detailed scene information. However, existing deep learning fusion methods suffer from an imbalance between fusion performance and computational resource consumption. Additionally, fusion layers or fusion rules fail to effectively combine heteromodal feature information. To address these challenges, this paper presents a novel algorithm called infrared and visible image fusion network base on fast edge convolution (FECFusion). During the training phase, the proposed algorithm enhances the extraction of texture features in the source image through the utilization of structural re-parameterization edge convolution (RECB) with embedded edge operators. Subsequently, the attention fusion module (AFM) is employed to sufficiently fuze both unique and public information from the heteromodal features. In the inference stage, we further optimize the training network using the structural reparameterization technique, resulting in a VGG-like network architecture. This optimization improves the fusion speed while maintaining the fusion performance. To evaluate the performance of the proposed FECFusion algorithm, qualitative and quantitative experiments are conducted. Seven advanced fusion algorithms are compared using MSRS, TNO, and M3FD datasets. The results demonstrate that the fusion algorithm presented in this paper achieves superior performance in multiple evaluation metrics, while consuming fewer computational resources. Consequently, the proposed algorithm yields better visual results and provides richer scene detail information.
Citation: Zhaoyu Chen, Hongbo Fan, Meiyan Ma, Dangguo Shao. FECFusion: Infrared and visible image fusion network based on fast edge convolution[J]. Mathematical Biosciences and Engineering, 2023, 20(9): 16060-16082. doi: 10.3934/mbe.2023717
The purpose of infrared and visible image fusion is to integrate the complementary information from heterogeneous images in order to enhance their detailed scene information. However, existing deep learning fusion methods suffer from an imbalance between fusion performance and computational resource consumption. Additionally, fusion layers or fusion rules fail to effectively combine heteromodal feature information. To address these challenges, this paper presents a novel algorithm called infrared and visible image fusion network base on fast edge convolution (FECFusion). During the training phase, the proposed algorithm enhances the extraction of texture features in the source image through the utilization of structural re-parameterization edge convolution (RECB) with embedded edge operators. Subsequently, the attention fusion module (AFM) is employed to sufficiently fuze both unique and public information from the heteromodal features. In the inference stage, we further optimize the training network using the structural reparameterization technique, resulting in a VGG-like network architecture. This optimization improves the fusion speed while maintaining the fusion performance. To evaluate the performance of the proposed FECFusion algorithm, qualitative and quantitative experiments are conducted. Seven advanced fusion algorithms are compared using MSRS, TNO, and M3FD datasets. The results demonstrate that the fusion algorithm presented in this paper achieves superior performance in multiple evaluation metrics, while consuming fewer computational resources. Consequently, the proposed algorithm yields better visual results and provides richer scene detail information.

| [1] |
J. Chen, X. Li, L. Luo, J. Ma, Multi-focus image fusion based on multi-scale gradients and image matting, Trans. Multimedia, 24 (2021), 655–667. https://doi.org/10.1109/TMM.2021.3057493 doi: 10.1109/TMM.2021.3057493

|
| [2] |
S. Karim, G. Tong, J. Li, A. Qadir, U. Farooq, Y. Yu, Current advances and future perspectives of image fusion: A comprehensive review, Inf. Fusion, 90 (2023), 185–217. https://doi.org/10.1016/j.inffus.2022.09.019 doi: 10.1016/j.inffus.2022.09.019
|
| [3] |
H. Zhang, H. Xu, X. Tian, J. Jiang, J. Ma, Image fusion meets deep learning: A survey and perspective, Inf. Fusion, 76 (2021), 323–336. https://doi.org/10.1016/j.inffus.2021.06.008 doi: 10.1016/j.inffus.2021.06.008
|
| [4] |
H. Liu, F. Chen, Z. Zeng, X. Tan, AMFuse: Add–multiply-based cross-modal fusion network for multi-spectral semantic segmentation, Remote Sens., 14 (2022), 3368. https://doi.org/10.3390/rs14143368 doi: 10.3390/rs14143368
|
| [5] | P. Gao, T. Tian, T. Zhao, L. Li, N. Zhang, J. Tian, GF-detection: Fusion with GAN of infrared and visible images for vehicle detection at nighttime, Remote Sens., 14 (2022), 2771. https://doi.org/10.3390/rs14122771 |
| [6] |
J. Chen, X. Li, L. Luo, X. Mei, J. Ma, Infrared and visible image fusion based on target-enhanced multiscale transform decomposition, Inf. Sci., 508 (2020), 64–78. https://doi.org/10.1016/j.ins.2019.08.066 doi: 10.1016/j.ins.2019.08.066
|
| [7] |
H. Tang, G. Liu, L. Tang, D. P. Bavirisetti, J. Wang, MdedFusion: A multi-level detail enhancement decomposition method for infrared and visible image fusion, Infrared Phys. Technol., 127 (2022), 104435. https://doi.org/10.1016/j.infrared.2022.104435 doi: 10.1016/j.infrared.2022.104435
|
| [8] |
Y. Li, G. Li, D. P. Bavirisetti, X. Gu, X. Zhou, Infrared-visible image fusion method based on sparse and prior joint saliency detection and LatLRR-FPDE, Digital Signal Process., 134 (2023), 103910. https://doi.org/10.1016/j.dsp.2023.103910 doi: 10.1016/j.dsp.2023.103910
|
| [9] |
J. Ma, C. Chen, C. Li, J. Huang, Infrared and visible image fusion via gradient transfer and total variation minimization, Inf. Fusion, 31 (2016), 100–109. https://doi.org/10.1016/j.inffus.2016.02.001 doi: 10.1016/j.inffus.2016.02.001
|
| [10] |
J. Ma, Z. Zhou, B. Wang, H. Zong, Infrared and visible image fusion based on visual saliency map and weighted least square optimization, Infrared Phys. Technol., 82 (2017), 8–17. https://doi.org/10.1016/j.infrared.2017.02.005 doi: 10.1016/j.infrared.2017.02.005
|
| [11] |
L. Tang, Y. Deng, Y. Ma, J. Huang, J. Ma, SuperFusion: A versatile image registration and fusion network with semantic awareness, IEEE/CAA J. Autom. Sin., 9 (2022), 2121–2137. https://doi.org/10.1109/JAS.2022.106082 doi: 10.1109/JAS.2022.106082
|
| [12] |
J. Ma, L. Tang, M. Xu, H. Zhang, G. Xiao, STDFusionNet: An infrared and visible image fusion network based on salient target detection, IEEE Trans. Instrum. Meas., 70 (2021), 1–13. https://doi.org/10.1109/TIM.2021.3075747 doi: 10.1109/TIM.2021.3075747
|
| [13] |
J. Ma, L. Tang, F. Fan, J. Huang, X. Mei, Y. Ma, SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer, IEEE/CAA J. Autom. Sin., 9 (2022), 1200–1217. https://doi.org/10.1109/JAS.2022.105686 doi: 10.1109/JAS.2022.105686
|
| [14] |
H. Li, Y. Cen, Y. Liu, X. Chen, Z. Yu, Different input resolutions and arbitrary output resolution: A meta learning-based deep framework for infrared and visible image fusion, IEEE Trans. Image Process., 30 (2021), 4070–4083. https://doi.org/10.1109/TIP.2021.3069339 doi: 10.1109/TIP.2021.3069339
|
| [15] |
H. Liu, M. Ma, M. Wang, Z. Chen, Y. Zhao, SCFusion: Infrared and visible fusion based on salient compensation, Entropy, 25 (2023), 985. https://doi.org/10.3390/e25070985 doi: 10.3390/e25070985
|
| [16] |
Y. Long, H. Jia, Y. Zhong, Y. Jiang, Y. Jia, RXDNFuse: A aggregated residual dense network for infrared and visible image fusion, Inf. Fusion, 69 (2021), 128–141. https://doi.org/10.1016/j.inffus.2020.11.009 doi: 10.1016/j.inffus.2020.11.009
|
| [17] |
Q. Pu, A. Chehri, G. Jeon, L. Zhang, X. Yang, DCFusion: Dual-headed fusion strategy and contextual information awareness for infrared and visible remote sensing image, Remote Sens., 15 (2023), 144. https://doi.org/10.3390/rs15010144 doi: 10.3390/rs15010144
|
| [18] |
H. Xu, X. Wang, J. Ma, DRF: Disentangled representation for visible and infrared image fusion, IEEE Trans. Instrum. Meas., 70 (2021), 1–13. https://doi.org/10.1109/TIM.2021.3056645 doi: 10.1109/TIM.2021.3056645
|
| [19] |
H. Li, X. J. Wu, J. Kittler, RFN-Nest: An end-to-end residual fusion network for infrared and visible images, Inf. Fusion, 73 (2021), 72–86. https://doi.org/10.1016/j.inffus.2021.02.023 doi: 10.1016/j.inffus.2021.02.023
|
| [20] |
H. Xu, M. Gong, X. Tian, J. Huang, J. Ma, CUFD: An encoder–decoder network for visible and infrared image fusion based on common and unique feature decomposition, Comput. Vision Image Understanding, 218 (2022), 103407. https://doi.org/10.1016/j.cviu.2022.103407 doi: 10.1016/j.cviu.2022.103407
|
| [21] |
H. Li, X. J. Wu, T. Durrani, NestFuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models, IEEE Trans. Instrum. Meas., 69 (2020), 9645–9656. https://doi.org/10.1109/TIM.2020.3005230 doi: 10.1109/TIM.2020.3005230
|
| [22] | H. Zhang, H. Xu, Y. Xiao, X. Guo, J. Ma, Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity, in Proceedings of the AAAI Conference on Artificial Intelligence, 34 (2020), 12797–12804. https://doi.org/10.1609/aaai.v34i07.6975 |
| [23] |
W. Xue, A. Wang, L. Zhao, FLFuse-Net: A fast and lightweight infrared and visible image fusion network via feature flow and edge compensation for salient information, Infrared Phys. Technol., 127 (2022), 104383. https://doi.org/10.1016/j.infrared.2022.104383 doi: 10.1016/j.infrared.2022.104383
|
| [24] | X. Zhang, H. Zeng, L. Zhang, Edge-oriented convolution block for real-time super resolution on mobile devices, in Proceedings of the 29th ACM International Conference on Multimedia, (2021), 4034–4043. https://doi.org/10.1145/3474085.3475291 |
| [25] | P. K. A. Vasu, J. Gabriel, J. Zhu, O. Tuzel, A. Ranjan, MobileOne: An improved one millisecond mobile backbone, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2023), 7907–7917. https://doi.org/10.48550/arXiv.2206.04040 |
| [26] | P. K. A. Vasu, J. Gabriel, J. Zhu, O. Tuzel, A. Ranjan, FastViT: A fast hybrid vision transformer using structural reparameterization, preprint, arXiv: 2303.14189. https://doi.org/10.48550/arXiv.2303.14189 |
| [27] | X. Ding, X. Zhang, J. Han, G. Ding, Scaling up your kernels to 31x31: Revisiting large kernel design in cnns, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2022), 11963–11975. https://doi.org/10.1109/CVPR52688.2022.01166 |
| [28] |
X. Liao, J. Yin, M. Chen, Z. Qin, Adaptive payload distribution in multiple images steganography based on image texture features, IEEE Trans. Dependable Secure Comput., 19 (2020), 897–911. https://doi.org/10.1109/TDSC.2020.3004708 doi: 10.1109/TDSC.2020.3004708
|
| [29] |
X. Liao, Y. Yu, B. Li, Z. Li, Z. Qin, A new payload partition strategy in color image steganography, IEEE Trans. Circuits Syst. Video Technol., 30 (2019), 685–696. https://doi.org/10.1109/TCSVT.2019.2896270 doi: 10.1109/TCSVT.2019.2896270
|
| [30] |
J. Tan, X. Liao, J. Liu, Y. Cao, H. Jiang, Channel attention image steganography with generative adversarial networks, IEEE Trans. Network Sci. Eng., 9 (2021), 888–903. https://doi.org/10.1109/TNSE.2021.3139671 doi: 10.1109/TNSE.2021.3139671
|
| [31] |
Y. Zhang, Y. Liu, P. Sun, H. Yan, X. Zhao, L. Zhang, IFCNN: A general image fusion framework based on convolutional neural network, Inf. Fusion, 54 (2020), 99–118. https://doi.org/10.1016/j.inffus.2019.07.011 doi: 10.1016/j.inffus.2019.07.011
|
| [32] |
H. Zhang, J. Ma, SDNet: A versatile squeeze-and-decomposition network for real-time image fusion, Int. J. Comput. Vision, 129 (2021), 2761–2785. https://doi.org/10.1007/s11263-021-01501-8 doi: 10.1007/s11263-021-01501-8
|
| [33] |
L. Tang, J. Yuan, J. Ma, Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network, Inf. Fusion, 82 (2022), 28–42. https://doi.org/10.1016/j.inffus.2021.12.004 doi: 10.1016/j.inffus.2021.12.004
|
| [34] | X. Ding, Y. Guo, G. Ding, J. Han, Acnet: Strengthening the kernel skeletons for powerful cnn via asymmetric convolution blocks, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2019), 1911–1920. https://doi.org/10.1109/ICCV.2019.00200 |
| [35] | X. Ding, X. Zhang, N. Ma, et al., Repvgg: Making vgg-style convnets great again, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2021), 13733–13742. https://doi.org/10.1109/CVPR46437.2021.01352 |
| [36] | X. Ding, X. Zhang, J. Han, G. Ding, Diverse branch block: Building a convolution as an inception-like unit, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2021), 10886–10895. https://doi.org/10.1109/CVPR46437.2021.01074 |
| [37] |
L. Tang, J. Yuan, H. Zhang, X. Jiang, J. Ma, PIAFusion: A progressive infrared and visible image fusion network based on illumination aware, Inf. Fusion, 83 (2022), 79–92. https://doi.org/10.1016/j.inffus.2022.03.007 doi: 10.1016/j.inffus.2022.03.007
|
| [38] | A. Toet, TNO image fusion dataset, 2014. Available from: https://figshare.com/articles/dataset/TNOImageFusionDataset/1008029. |
| [39] | J. Liu, X. Fan, Z. Huang, G. Wu, R. Liu, W. Zhong, et al., Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2022), 5802–5811. https://doi.org/10.1109/CVPR52688.2022.00571 |
| [40] |
Y. J. Rao, In-fibre Bragg grating sensors, Meas. Sci. Technol., 8 (1997), 355. https://doi.org/10.1088/0957-0233/8/4/002 doi: 10.1088/0957-0233/8/4/002
|
| [41] |
G. Qu, D. Zhang, P. Yan, Information measure for performance of image fusion, Electron. Lett., 38 (2002), 1. https://doi.org/10.1049/el:20020212 doi: 10.1049/el:20020212
|
| [42] |
Y. Han, Y. Cai, Y. Cao, X. Xu, A new image fusion performance metric based on visual information fidelity, Inf. Fusion, 14 (2013), 127–135. https://doi.org/10.1016/j.inffus.2011.08.002 doi: 10.1016/j.inffus.2011.08.002
|
| [43] |
V. Aslantas, E. Bendes, A new image quality metric for image fusion: The sum of the correlations of differences, AEU-Int. J. Electron. Commun., 69 (2015), 1890–1896. https://doi.org/10.1016/j.aeue.2015.09.004 doi: 10.1016/j.aeue.2015.09.004
|
| [44] |
J. W. Roberts, J. A. V. Aardt, F. B. Ahmed, Assessment of image fusion procedures using entropy, image quality, and multispectral classification, J. Appl. Remote Sens., 2 (2008), 023522. https://doi.org/10.1117/1.2945910 doi: 10.1117/1.2945910
|
| [45] |
C. S. Xydeas, V. Petrovic, Objective image fusion performance measure, Electron. Lett., 36 (2000), 308–309. https://doi.org/10.1049/el:20000267 doi: 10.1049/el:20000267
|
| [46] |
H. Li, X. J. Wu, DenseFuse: A fusion approach to infrared and visible images, IEEE Trans. Image Process., 28 (2018), 2614–2623. https://doi.org/10.1109/TIP.2018.2887342 doi: 10.1109/TIP.2018.2887342
|
| [47] |
J. Ma, W. Yu, P. Liang, C. Li, J. Jiang, FusionGAN: A generative adversarial network for infrared and visible image fusion, Inf. Fusion, 48 (2019), 11–26. https://doi.org/10.1016/j.inffus.2018.09.004 doi: 10.1016/j.inffus.2018.09.004
|
| [48] |
H. Xu, J. Ma, J. Jiang, X. Guo, H. Ling, U2Fusion: A unified unsupervised image fusion network, IEEE Trans. Pattern Anal. Mach. Intell., 44 (2020), 502–518. https://doi.org/10.1109/TPAMI.2020.3012548 doi: 10.1109/TPAMI.2020.3012548
|
| [49] | L. C. Chen, Y. Zhu, G. Papandreou, F. Schroff, H. Adam, Encoder-decoder with atrous separable convolution for semantic image segmentation, in Proceedings of the European Conference on Computer Vision (ECCV), (2018), 801–818. https://doi.org/10.1007/978-3-030-01234-2_49 |
| [50] | M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, et al., The cityscapes dataset for semantic urban scene understanding, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2016), 3213–3223. https://doi.org/10.1109/CVPR.2016.350 |







Figures(11) / Tables(5)

Zhaoyu Chen, Hongbo Fan, Meiyan Ma, Dangguo Shao. FECFusion: Infrared and visible image fusion network based on fast edge convolution[J]. Mathematical Biosciences and Engineering, 2023, 20(9): 16060-16082. doi: 10.3934/mbe.2023717







 DownLoad:
DownLoad: