Citation: Mingli Lei, Daijun Wei. A measure of identifying influential community based on the state of critical functionality[J]. Mathematical Biosciences and Engineering, 2020, 17(6): 7167-7191. doi: 10.3934/mbe.2020368

| [1] | A. Clauset, M. E. J. Newman, C. Moore, Finding community structure in very large networks, Phys. Rev. E, 70 (2004), 066111. |
| [2] | Y. Deng, Uncertainty measure in evidence theory, Sci. China Inf. Sci., 64 (2021), http://10.1007/s11432--020--3006--9. |
| [3] | J. Ramirez Marquez, M. Claudio, Vulnerability metrics and analysis for communities in complex networks, Reliab. Eng. Syst. Saf., 96 (2011), 1360-1366. |
| [4] | Y. Zhang, M. K. Lindell, C. S. Prater, Vulnerability of community businesses to environmental disasters, Disasters, 33 (2009), 38-57. |
| [5] | M. Hu, X. Wang, X. Wen, Y. Xia, Microbial community structures in different wastewater treatment plants as revealed by 454-pyrosequencing analysis, Bioresour. Technol., 117 (2012), 72-79. |
| [6] | A. Tyakht, E. Kostryukova, A. Popenko, M. Belenikin, A. Pavlenko, A. Larin, et al., Human gut microbiota community structures in urban and rural populations in russia, Nat. Commun., 4 (2014), 1-9. |
| [7] | O. Koren, D. Knights, A. Gonzalez, L. Waldron, N. Segata, R. Knight, et al., A guide to enterotypes across the human body: meta-analysis of microbial community structures in human microbiome datasets, PLOS Comput. Biol., 9 (2013), e1002863. |
| [8] | B. H. Morrow, Identifying and mapping community vulnerability, Disasters, 23 (1999), 1-18. |
| [9] | M. Girvan, M. E. J. Newman, Community structure in social and biological networks, Proc. Natl. Acad. Sci. USA, 99 (2002), 7821-7826. |
| [10] | P. M. Gleiser, L. Danon, Community structure in jazz, Adv. Complex Syst., 6 (2003), 565-573. |
| [11] | M. E. J. Newman, M. Girvan, Finding and evaluating community structure in networks, Phys. Rev. E, 69 (2004), 026113. |
| [12] | S. Srinivas, C. Rajendran, Community detection and influential node identification in complex networks using mathematical programming, Expert Syst. Appl., 135 (2019), 296-312. |
| [13] | Z. H. Deng, H. H. Qiao, Q. Song, L. Gao, A complex network community detection algorithm based on label propagation and fuzzy c-means, Physica A, 519 (2019), 217-226. |
| [14] | F. Liu, Y. Deng, A fast algorithm for network forecasting time series, IEEE Access, 7 (2019), 102554-102560. |
| [15] | J. Zhao, H. Mo, Y. Deng, An efficient network method for time series forecasting based on the DC algorithm and visibility relation, IEEE Access, 8 (2020), http://10.1109/ACCESS.2020.2964067. |
| [16] | L. C. Freeman, A set of measures of centrality based on betweenness, Sociometry, 40 (1977), 35-41. |
| [17] | Z. Ghalmane, C. Cherifi, H. Cherifi, M. E. Hassouni, Centrality in complex networks with overlapping community structure, Sci. Rep., 9 (2019), 10133. |
| [18] | H. Cherifi, G. Palla, B. K. Szymanski, X. Lu, On community structure in complex networks: challenges and opportunities, Appl. Netw. Sci., 4 (2019), https://doi.org/10.1007/s41109-019-0238-9. |
| [19] | M. E. J. Newman, Fast algorithm for detecting community structure in networks, Phys. Rev. E, 69 (2004), 066133. |
| [20] | M. E. J. Newman, Modularityand community structure in networks, Proc. Natl. Acad. Sci. USA, 103 (2006), 8577-8582. |
| [21] | U. N. Raghavan, R. Albert, S. Kumara, Near linear time algorithm to detect community structures in large-scale networks, Phys. Rev. E, 76 (2007), 036106. |
| [22] | H. F. Zhou, J. Li, J. H. Li, F. C. Zhang, Y. A. Cui, A graph clustering method for community detection in complex networks, Physica A, 469 (2017), 551-562. |
| [23] | C. M. Rocco, J. Moronta, J. E. Ramirez-Marquez, K. Barker, Effects of multi-state links in network community detection, Reliab. Eng. Syst. Saf., 163 (2017), 46-56. |
| [24] | G. Cantin, C. J. Silva, Influence of the topology on the dynamics of a complex network of hiv/aids epidemic models, Math. Biosci. Eng., 4 (2019), 1145-1169. |
| [25] | M. Liu, S. He, Y. Sun, The impact of media converge on complex networks on disease transmission, Math. Biosci. Eng., 16 (2019), 6335-6349. |
| [26] | Z. Zhuang, Z. Lu, Z. Huang, C. Liu, W. Qin, A novel complex network based dynamic rule selection approach for open shop scheduling problem with release dates, Math. Biosci. Eng., 16 (2019), 4491-4505. |
| [27] | D. Wei, X. Zhang, S. Mahadevan, Measuring the vulnerability of community structure in complex networks, Reliab. Eng. Syst. Saf., 174 (2018), 41-52. |
| [28] | B. Sluban, J. Smailović, S. Battiston, I. Mozetič, Sentiment leaning of influential communities in social networks, Comput. Soc. Networks, 2 (2015), 9-29. |
| [29] | M. Lei, D. Wei, Identifying influence for community in complex networks, IEEE 30th CCDC, (2018), 5346-5349. |
| [30] | X. Wu, Z. Liu, How community structure influences epidemic spread in social networks, Physica A, 387 (2008), 623-630. |
| [31] | R. H. Li, L. Qin, J. X. Yu, R. Mao, Influential community search in large networks, Proc. VlDB Endow., 8 (2015), 509-520. |
| [32] | W. Chen, J. Liu, Z. Chen, J. Chen, A top-r k influential community search algorithm., Int. J. Performability Eng., 14 (2018), 2652-2662. |
| [33] | R. H. Li, L. Qin, J. X. Yu, R. Mao, Finding influential communities in massive networks, VLDB J., 26 (2017), 751-776. |
| [34] | J. Zhao, Y. Song, Y. Deng, A novel model to identify the influential nodes: Evidence Theory Centrality, IEEE Access, 8 (2020), 46773-46780. |
| [35] | S. Oldham, B. Fulcher, L. Parkes, A. Arnatkevicit, A. Fornito, Consistency and differences between centrality measures across distinct classes of networks, PloS One, 14 (2019), 1-23. |
| [36] | J. Zhao, Y. Wang, Y. Deng, Identifying influential nodes in complex networks from global perspective, Chaos Solitons Fract., 133 (2020), 109637. |
| [37] | M. Perc, O. Peek, S. M. Kamal, Impact of density and interconnectedness of influential players on social welfare, Appl. Math. Comput., 249 (2014), 19-23. |
| [38] | D. Chen, L. Lü, M. Shang, Y. Zhang, T. Zhou, Identifying influential nodes in complex networks, Physica A, 391 (2012), 1777-1787. |
| [39] | P. Bonacich, P. Lloyd, Eigenvector-like measures of centrality for asymmetric relations, Soc. Networks, 23 (2001), 191-201. |
| [40] | L. Lü, Y. Zhang, C. Yeung, T. Zhou, Leaders in social networks, the delicious case, PloS One, 6 (2011), 1-9. |
| [41] | D. Kempe, J. Kleinberg, E. Tardos, Influential nodes in a diffusion model for social networks, Lect. Notes Comput. Sci., 3580 (2005), 1127-1138. |
| [42] | M. Kimura, K. Saito, Tractable models for information diffusion in social networks, ECML PKDD, 4231 (2006), 259-271. |
| [43] | M. Kimura, K. Saito, R. Nakano, H. Motoda, Extracting influential nodes on a social network for information diffusion, Data Min. Knowl. Discov., 20 (2010), 70-97. |
| [44] | F. Liu, Z. Wang, Y. Deng, Gmm: A generalized mechanics model for identifying the importance of nodes in complex networks, Knowl. Based Syst., 193 (2020), 105464. |
| [45] | G. Yang, T. P. Benko, M. Cavaliere, J. Huang, M. Perc, Identification of influential invaders in evolutionary populations, Sci. Rep., 9 (2019), 7305-7317. |
| [46] | J. Zhao, Y. Song, F. Liu, Y. Deng, The identification of influential nodes based on structure similarity, Conn. Sci., 32 (2020), 1-18. |
| [47] | U. Bhatia, D. Kumar, E. Kodra, A. R. Ganguly, Network science based quantification of resilience demonstrated on the indian railways network, Plos One, 10 (2015), 1-17. |
| [48] | T. Wen, D. Pelusi, Y. Deng, Vital spreaders identification in complex networks with multi-local dimension, Knowl.Based Syst., 195 (2020), 105717. |
| [49] | Y. Zhao, S. Li, F. Jin, Identification of influential nodes in social networks with community structure based on label propagation, Neurocomput., 210 (2016), 33-44. |
| [50] | Z. Zhao, X. Wang, W. Zhang, Z. Zhu, A community-based approach to identifying influential spreaders, Entropy, 17 (2015), 2228-2252. |
| [51] | Z. Ghalmane, M. E. Hassouni, C. Cherifi, H. Cherifi, Centrality in modular networks, EPJ Data Sci., 8 (2019), 15. |
| [52] | J. E. Ramirez-Marquez, C. M. Rocco, K. Barker, J. Moronta, Quantifying the resilience of community structures in networks, Reliab. Eng. Syst. Saf., 169 (2018), 466-474. |
| [53] | P. Zhang, J. Wang, X. Li, M. Li, Z. Di, Y. Fan, Clustering coefficient and community structure of bipartite networks, Physica A, 387 (2008), 6869-6875. |
| [54] | R. A. Erdös P, On the evolution of random graphs, Publ. Math. Inst. Hung. Acad. Sci., 5 (1960), 15-27. |
| [55] | A. L. Barabási, R. Albert, Emergence of scaling in random networks, Science, 286 (1999), 509-512. |
| [56] | D. J. Watts, S. H. Strogatz, Collective dynamics of small-world networks, Nature, 393 (1998), 440-442. |
| [57] | V. E. Krebs, Mapping networks of terrorist cells, Connections, 24 (2002), 43-52. |
| [58] | V. Batagelj, A. Mrvar, Pajek datasets, 2006. Available from: http://vlado.fmf.uni-lj.si/pub/networks/data/mix/USAir97.net. |
| [59] | V. E. Krebs, Unpublished, 2007. Available from: http://www.orgnet.com/. |
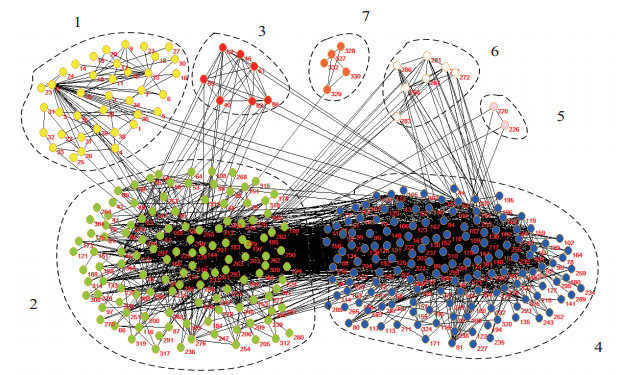
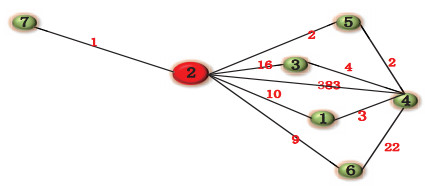
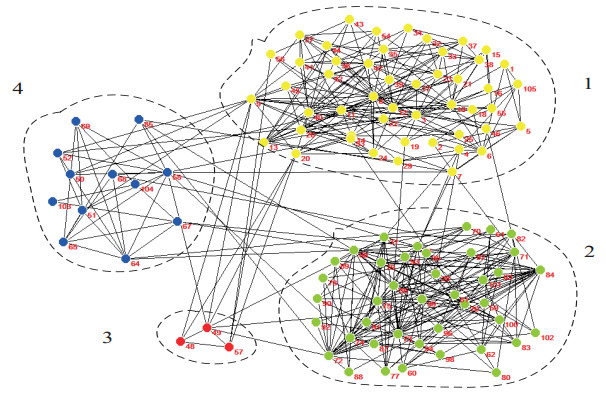
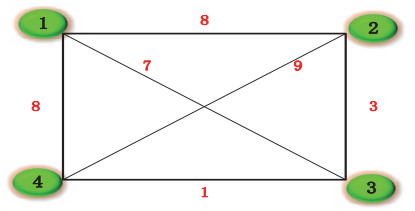
Figures(12) / Tables(12)

Mingli Lei, Daijun Wei. A measure of identifying influential community based on the state of critical functionality[J]. Mathematical Biosciences and Engineering, 2020, 17(6): 7167-7191. doi: 10.3934/mbe.2020368







 DownLoad:
DownLoad: