Citation: Hongli Niu, Kunliang Xu. A hybrid model combining variational mode decomposition and an attention-GRU network for stock price index forecasting[J]. Mathematical Biosciences and Engineering, 2020, 17(6): 7151-7166. doi: 10.3934/mbe.2020367

| [1] | C. Zhang, H. Pan, Y. Ma, X. Huang, Analysis of Asia Pacific stock markets with a novel multiscale model, Phys. A, 534 (2019), 120939. |
| [2] | A. L. D. Loureiro, V. L. Miguéis, L. F. M. da Silva, Exploring the use of deep neural networks for sales forecasting in fashion retail, Decis. Support Syst., 114 (2018), 81-93. |
| [3] |
J. Wang, J. Wang, Forecasting stock market indexes using principle component analysis and stochastic time effective neural networks, Neurocomputing, 156 (2015), 68-78. doi: 10.1016/j.neucom.2014.12.084

|
| [4] | Y. Xu, S. B. Cohen, Stock movement prediction from tweets and historical prices, In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, 2018. |
| [5] |
D.P. Mandic, J.A. Chambers, Exploiting inherent relationships in RNN architectures, Neural Networks, 12 (1999), 1341-1345. doi: 10.1016/S0893-6080(99)00076-3
|
| [6] | T. Deng, X. He, Z. Zeng, Recurrent neural network for combined economic and emission dispatch, Applied Intelligence, Appl. Intell., 48 (2018), 2180-2198. |
| [7] | S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural Comput., 9 (1997), 1735-1780. |
| [8] | K. Wang, X. Qi, H. Liu, Photovoltaic power forecasting based LSTM-Convolutional Network, Energy, 189 (2019), 116225. |
| [9] | Z. Karevan, J. A. K. Suykens, Transductive LSTM for time-series prediction: An application to weather forecasting, Neural Networks, 125 (2020), 1-9. |
| [10] | B. Zhao, Z. P. Wang, W. J. Ji, X. Gao, X. B. Li, A Short-term Power Load Forecasting Method Based on Attention Mechanism of CNN-GRU, Power Syst. Technol., 12 (2019). |
| [11] | Z. Y. Peng, S. Peng, L. D. Fu, B. C. Lu, J. J. Tang, K. Wang, et al., A novel deep learning ensemble model with data denoising for short-term wind speed forecasting, Energy Convers. Manage., 207 (2020), 112524. |
| [12] | W. Y. Wu, W. L. Liao, J. Miao, G. L. Du, Using Gated Recurrent Unit Network to Forecast Short-Term Load Considering Impact of Electricity Price, Energy Procedia, 158 (2019) 3369-3374. |
| [13] | J. Zhang, D. Li, Y. Hao, Z. Tan, A hybrid model using signal processing technology, econometric models and neural network for carbon spot price forecasting, J. Cleaner Prod., 204 (2018), 958-964. |
| [14] |
J. Wang, L. Y. Tang, Y. Y. Luo, P. Ge, A weighted EMD-based prediction model based on TOPSIS and feed forward neural network for noised time series, Knowl. Based Syst., 132 (2017), 167-178. doi: 10.1016/j.knosys.2017.06.022
|
| [15] |
J. Cao, Z. Li, J. Li, Financial time series forecasting model based on CEEMDAN and LSTM, Phys. A, 519 (2019), 127-139. doi: 10.1016/j.physa.2018.11.061
|
| [16] | K. Dragomiretskiy, D. Zosso, Variational mode decomposition, IEEE Trans. Signal Process., 62 (2014), 531-544. |
| [17] |
S. Lahmiri, Intraday stock price forecasting based on variational mode decomposition, J. Comput. Sci., 12 (2016), 23-27. doi: 10.1016/j.jocs.2015.11.011
|
| [18] |
S. Lahmiri, A variational mode decomposition approach for analysis and forecasting of economic and financial time series, Expert Syst. Appl., 55 (2016), 268-273. doi: 10.1016/j.eswa.2016.02.025
|
| [19] | S. Lahmiri, Comparing variational and empirical mode decomposition in forecasting day-ahead energy prices, IEEE Syst. J., 11 (2015), 1907-1910. |
| [20] | Q. Zhu, F. Zhang, S. Liu, Y. Wu, L. Wang, A hybrid VMD-BiGRU model for rubber futures time series forecasting, Appl. Soft Comput., 84 (2019), 105739. |
| [21] |
C. Li, G. Tang, X. Xue, A. Saeed, X. Hu, Short-term wind speed interval prediction based on ensemble GRU model, IEEE Trans. Sustainable Energy, 11 (2020), 1370-1380. doi: 10.1109/TSTE.2019.2926147
|
| [22] | R. Wang, C. Li, W. Fu, G. Tang, Deep learning method based on gated recurrent unit and variational mode decomposition for short-term wind power interval prediction, IEEE Trans. Neural Networks Learn. Syst., 31 (2019), 3814-3827. |
| [23] | S. Boyd, N. Parikh, E. Chu, B. Peleato. J. Eckstein, Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers, Now Foundations and Trends, 2011. |
| [24] | Y. Liu, C. Yang, K. Huang, W. Cui, Non-ferrous metals price forecasting based on variational mode decomposition and LSTM network, Knowl. Based Syst., 188 (2020), 105006. |
| [25] | J. W. E, J. M. Ye, L. L. He, H. H. Jin, Energy price prediction based on independent component analysis and gated recurrent unit neural network, Energy, 189 (2019), 116278. |
| [26] |
S. Chen, L. Ge, Exploring the attention mechanism in LSTM-based Hong Kong stock price movement prediction, Quant. Finance, 19 (2019), 1507-1515. doi: 10.1080/14697688.2019.1622287
|
| [27] |
R. Desimon, J. Duncan, Neural mechanisms of selective visual attention, Annu. Rev. Neurosci., 18 (1995), 193-222. doi: 10.1146/annurev.ne.18.030195.001205
|
| [28] | M. T. Luong, H. Pham, C. D. Manning, Effective approaches to attention-based neural machine translation, arXiv: 1508.04025. |
| [29] | L. Li, S. Tang, Y. Zhang, L. Deng, Q. Tian, GLA: global-local attention for image description, IEEE Trans. Multimedia, 20 (2017), 726-737. |
| [30] |
S. Wang, X. Wang, S. Wang, D. Wang, Bi-directional long short-term memory method based on attention mechanism and rolling update for short-term load forecasting, Int. J. Electric. Power Energy Syst., 109 (2019), 470-479. doi: 10.1016/j.ijepes.2019.02.022
|
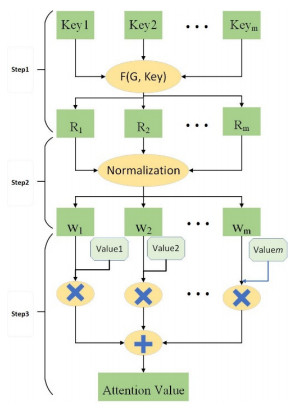
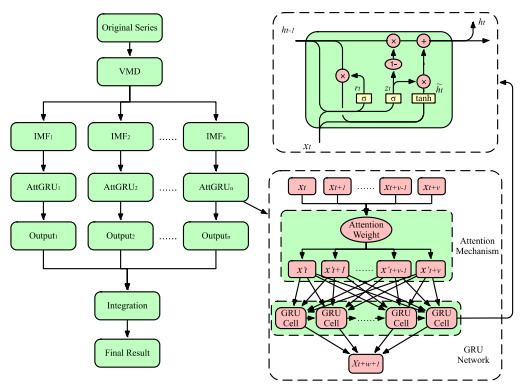
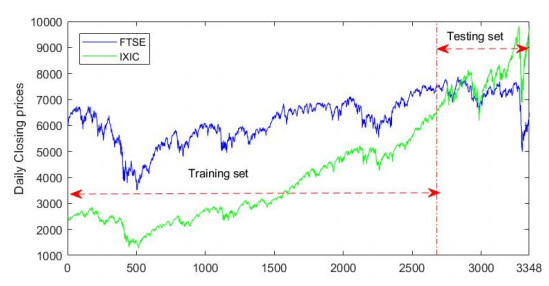
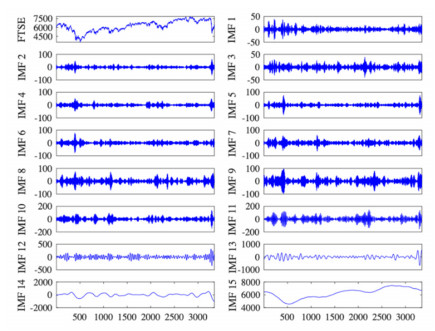
Figures(8) / Tables(5)

Hongli Niu, Kunliang Xu. A hybrid model combining variational mode decomposition and an attention-GRU network for stock price index forecasting[J]. Mathematical Biosciences and Engineering, 2020, 17(6): 7151-7166. doi: 10.3934/mbe.2020367







 DownLoad:
DownLoad: