Citation: Celia Schacht, Annabel Meade, H.T. Banks, Heiko Enderling, Daniel Abate-Daga. Estimation of probability distributions of parameters using aggregate population data: analysis of a CAR T-cell cancer model[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 7299-7326. doi: 10.3934/mbe.2019365

| [1] | H. T. Banks, Z. R. Kenz and W. C. Thompson, A review of selected techniques in inverse problem nonparametric probability distribution estimation, CRSC-TR12-13, Center for Research in Scien-tific Computation, N. C. State University, Raleigh, NC, May 2012; J. Inverse Ill-Pose. Probl., 20 (2012), 429–460. |
| [2] | H. T. Banks, S. Hu and W. C. Thompson, Chapter 5 of Modeling and Inverse Problems in the Presence of Uncertainty, Chapman and Hall/CRC, New York, 2014. |
| [3] | H. T. Banks, L. W.Botsford, F. Kappel, et al., Modeling and estimation in size structured popu-lation models, LCDS/CCS Rep. 87-13, March, 1987, Brown Univ.; Proc. 2nd Course on Math. Ecology (Trieste, December, 1986), World Scientific Press, Singapore (1988), 521–541. |
| [4] | H. T. Banks and H. T. Tran, Chapter 9.7 of Mathematical and Experimental Modeling of Physical and Biological Processes, CRC Press, Boca Raton, FL, January 2, 2009 |
| [5] | H. T. Banks, J. L. Davis, S. L. Ernstberger, et al., Experimental design and estimation of growth rate distributions in size-structured shrimp populations, CRSC TR08-20, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, November, 2008; Inverse Probl., 25 (2009), 095003 (28 pp). |
| [6] | H. T. Banks, L. W. Botsford, F. Kappel, et al., Estimation of growth and survival in size-structured cohort data: An application to larval striped bass (Morone saxatilis), CAMS Tech. Rep. 89-10, University of Southern California, 1989; J. Math. Biol., 30 (1991), 125–150. |
| [7] | H. T. Banks and B. G. Fitzpatrick, Estimation of growth rate distributions in size-structured popu-lation models, CAMS Tech. Rep. 90-2, University of Southern California, January, 1990; Q. Appl. Math., 49 (1991), 215–235. |
| [8] | D. Abate-Daga and M. L. Davila, CAR models: next-generation CAR modifications for enhanced T-cell function, Mol. Ther-Oncolytics, 3 (2016), 16014. |
| [9] | E. K. Moon, C. Carpenito, J. Sun, et al., Expression of a functional CCR2 receptor enhances tumor localization and tumor eradication by retargeted human T cells expressing a mesothelin-specific chimeric antibody receptor, Clin. Cancer Res., 17 (2011), 4719–4730. |
| [10] | H. T. Banks and N. L. Gibson, Well-posedness in Maxwell systems with distributions of polariza-tion relaxation parameters, CRSC-TR04-01, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, January, 2004; Appl. Math. Lett., 18 (2005), 423–430. |
| [11] | H. T. Banks and N. L. Gibson, Electromagnetic inverse problems involving distributions of di-electric mechanisms and parameters, CRSC-TR05-29, August, 2005; Q. Appl. Math., 64 (2006), 749–795. |
| [12] | H. T. Banks and D. M. Bortz, Inverse problems for a class of measure dependent dynamical systems, J. Inverse Ill-pose. Probl., 13 (2005), 103–121. |
| [13] | H. T. Banks, D. M. Bortz and S. E. Holte, Incorporation of variability into the mathematical modeling of viral delays in HIV infection dynamics, Math. Biosci., 183 (2003), 63–91. |
| [14] | H. T. Banks, D. M. Bortz, G. A. Pinter, et al., Modeling and imaging techniques with potential for application in bioterrorism, CRSC TR03-02, January 2003; Chapter 6 in Bioterrorism: Math-ematical Modeling Applications in Homeland Security (H.T. Banks and C. Castillo-Chavez, eds.), Front. Appl. Math., FR28, SIAM, Philadelphia, 2003, 129–154. |
| [15] | H. T. Banks, J. H. Barnes, A. Eberhardt, et al., Modeling and computation of propagating waves from coronary stenosis, Comput. Appl. Math., 21 (2002), 767–788. |
| [16] | H. T. Banks, S. Hu, Z. R. Kenz, et al., Material parameter estimation and hypothesis testing on a 1D viscoelastic stenosis model: methodology, CRSC-TR12-09, April, 2012; J. Inverse Ill-pose. Probl., 21 (2013), 25–57. |
| [17] | H. T. Banks, S. Hu, Z. R. Kenz, et al., Model validation for a noninvasive arterial stenosis detection problem, CRSC-TR12-22, December, 2012; Math. Biosci. Eng., 11 (2013), 427–448. |
| [18] | H. T. Banks and G. A. Pinter, A probabilistic multiscale approach to hysteresis in shear wave propagation in biotissue, CRSC-TR04-03, January, 2004; SIAM J. Multiscale Model. Sim., 3 (2005), 395–412. |
| [19] | H. T. Banks, Chapter 14.4 of A Functional Analysis Framework for Modeling, Estimation and Control in Science and Engineering, Taylor and Frances Publishing, 2012. |
| [20] | G. de Vries, T. Hillen, M. Lewis, et al., A Course in Mathematical Biology: Quantitative Modelling with Mathematical and Computational Methods, SIAM, Philadephia, 2006. |
| [21] | S. I. Rubinow, Introduction to Mathematical Biology, John Wiley & Sons, New York, 1975. |
| [22] | L. J. Allen, An Introduction to Mathematical Biology. Pearson Education, Inc., Pearson Prentice Hall, Upper Saddle River, NJ, 2007. |
| [23] | M. Braun and M. Golubitsky, Differential Equations and their Applications. Vol. 4. Springer-Verlag New York, Inc., New York, NY, 1983. |
| [24] | G. E. Collins and A. G. Akritas, Polynomial real root isolation using Descarte's rule of signs, Proceedings of the third ACM symposium on Symbolic and algebraic computation, ACM, 1976. |
| [25] | H. T. Banks, L. Bekele-Maxwell, L. Bociu, et al., The complex-step method for sensitivity analysis of non-smooth problems arising in biology, CRSC-TR15-11, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, October, 2015; Eurasia. J. Math. Comput. Appl., 3 (2015), 16–68. |
| [26] | H. T. Banks, K. Bekele-Maxwell, R. A. Everett, et al., Dynamic modeling of problem drinkers undergoing behavioral treatment, CRSC-TR16-12, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, October, October, 2016; Bull. Math. Biol., 79 (2017), 1254–1273. |
| [27] | H. T. Banks and K. L. Bihari, Modeling and estimating uncertainty in parameter estimation, CRSC-TR99-40, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, October, 2016; December, 1999; Inverse Probl., 17 (2001), 95–111. |
| [28] | H. T. Banks, K. B. Flores, I. G. Rosen, et al., The Prohorov Metric Framework and aggregate data inverse problems for random PDEs, CRSC-TR18-05, Center for Research in Scientific Computa- tion, N. C. State University, Raleigh, NC, June, 2018; Commun. Appl. Anal., 22 (2018), 415–446. |
| [29] | H. T. Banks, J. Catenacci and S. Hu, Use of difference-based methods to explore statistical and mathematical model discrepancy in inverse problems, CRSC-TR15-05, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, May, 2015. J. Inverse Ill-pose. P., 24 (2016), 413-–433. |
| [30] | H. T. Banks, J. E. Banks, N. G. Cody, et al., Population model for the decline of Homalodisca vitripennis (HEMIPTERA: CICADELLIDAE) over a ten-year period, CRSC-TR18-06, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, June, 2018; J. Biol. Dyn., 13 (2019), 422–446. |
| [31] | H. T. Banks and K. Kunisch, Estimation Techniques for Distributed Parameter Systems, Birkhas-ser, Boston, 1989. |
| [32] | H. T. Banks and P. Kareiva, Parameter estimation techniques for transport equations with applica-tion to population dispersal and tissue bulk flow models, J. Math. Biol., 17 (1983), 253–273. |
| [33] | A. C. Atkinson and R. A. Bailey, One hundred years of the design of experiments on and off the pages of Biometrika, Biometrika, 88 (2001), 53–97. |
| [34] | A. C. Atkinson and A. N. Donev, Optimum Experimental Designs, Oxford University Press, New York, 1992. |
| [35] | M. P. F. Berger and W. K. Wong (Editors), Applied Optimal Designs, John Wiley & Sons, Chich-ester, UK, 2005. |
| [36] | V. V. Fedorov, Theory of Optimal Experiments, Academic Press, New York and London, 1972. |
| [37] | V. V. Fedorov and P. Hackel, Model-Oriented Design of Experiments, Springer-Verlag, New York, 1997. |
| [38] | W. Mueller and M. Stehlik, Issues in the optimal design of computer simulation experiments, Appl. Stoch. Model. Bus., 25 (2009), 163–177. |
| [39] | M. Patan and B. Bogacka, Optimum experimental designs for dynamic systems in the presence of correlated errors, Comput. Stat. Data An., 51 (2007), 5644–5661. |
| [40] | D. Ucinski and A. C. Atkinson, Experimental design for time-dependent models with correlated observations, Stud. Nonlinear Dyn. E., 8 (2004), Article 13: The Berkeley Electronic Press. |
| [41] | H. T. Banks, K. Holm and F. Kappel, Comparison of optimal design methods in inverse problems, CRSC-TR10-11, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, July, 2010; Inverse Probl., 27 (2011), 075002. |
| [42] | H. T. Banks, A. Cintr'on-Arias and F. Kappel, Parameter selection methods in inverse problem for-mulation, CRSC-TR10-03, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, revised November 2010; Mathematical Model Development and Validation in Physi-ology: Application to the Cardiovascular and Respiratory Systems, Lecture Notes in Mathematics, Vol. 2064, Mathematical Biosciences Subseries; Springer-Verlag, Berlin, 2013. |
| [43] | M. Avery, H. T. Banks, K. Basu, et al., Experimental design and inverse problems in plant bi-ological modeling, CRSC-TR11-12, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, October, 2011; J. Inverse Ill-pose. P., 20 (2012), 169–191. |
| [44] | H. T. Banks and K. L. Rehm, Experimental design for vector output systems, CRSC-TR12-11, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, April, 2012; Inverse Probl. Sci. En., 22 (2014), 557–590. |
| [45] | H. T. Banks and K. L. Rehm, Experimental design for distributed parameter vector systems, CRSC-TR12-17, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, August, 2012; Appl. Math. Lett., 26 (2013), 10–14. |
| [46] | H. T. Banks, S. Dediu, S. L. Ernstberger, et al., Generalized sensitivities and optimal experimental design, CRSC-TR08-12, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, September, 2008, revised November, 2009; J. Inverse Ill-pose. P., 18 (2010), 25–83. |
| [47] | B. M. Adams, H. T. Banks, M. Davidian, et al., Model fitting and prediction with HIV treatment interruption data, CRSC TR05-40, Center for Research in Scientific Computation, N. C. State University, Raleigh, NC, October, 2005; Bull. Math. Biol., 69 (2007), 563–584. |
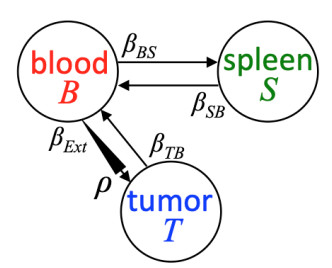
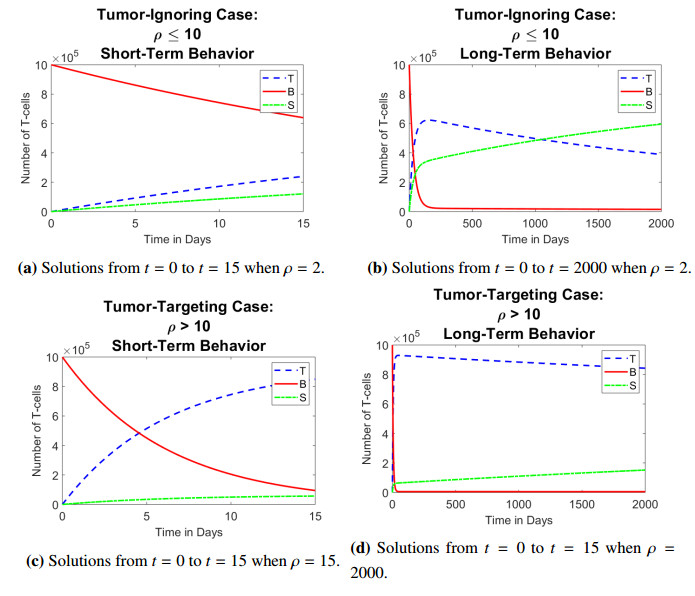
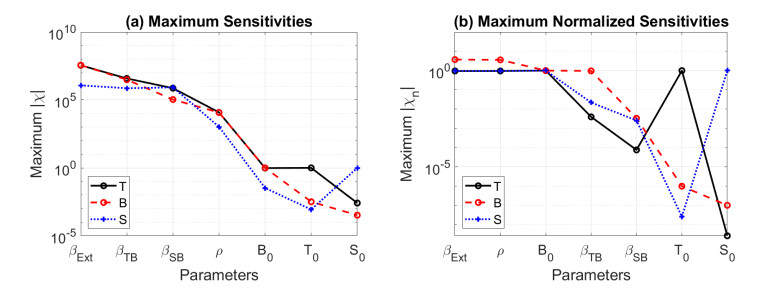
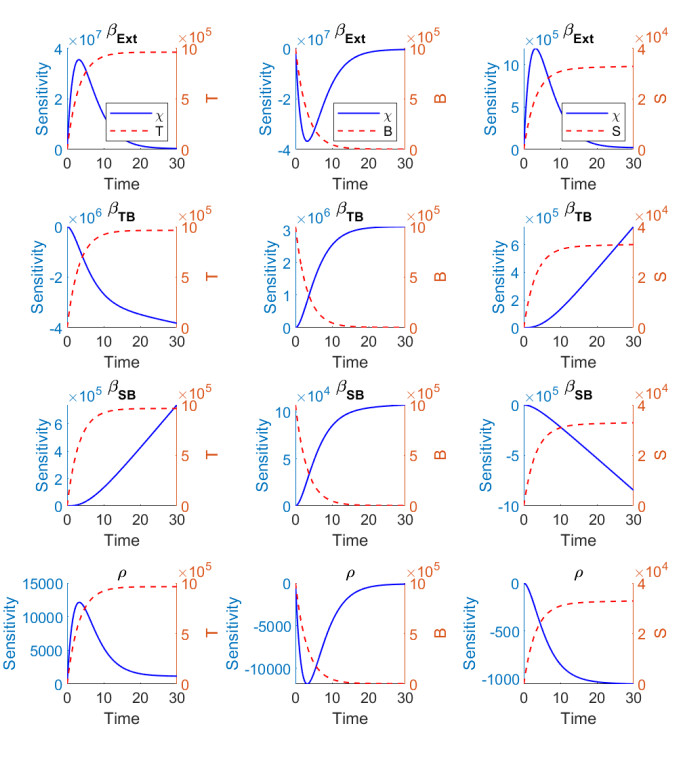
Figures(13) / Tables(1)

Celia Schacht, Annabel Meade, H.T. Banks, Heiko Enderling, Daniel Abate-Daga. Estimation of probability distributions of parameters using aggregate population data: analysis of a CAR T-cell cancer model[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 7299-7326. doi: 10.3934/mbe.2019365







 DownLoad:
DownLoad: