The fractional generalized cumulative residual entropy, a broader version of the cumulative residual entropy, holds significance in assessing the uncertainty model of random variables and maintains straightforward connections with reliability models and crucial information. This article represents and modifies some novel features of the fractional generalized cumulative residual entropy and discusses the weak convergence. Additionally, the measure is utilized to assess uniformity, involving the derivation of the limit distribution and an approximation of the test statistic's distribution. Furthermore, the concept of stability is addressed. Moreover, the presentation includes the critical points and power analysis against alternative distributions of this test statistic. Furthermore, a simulation study is carried out to compare the power value of the proposed test with that of other tests of uniformity. Moreover, the uniformity test utilizes real data on daily smokers in the countries of the Euro Area. Finally, our model's exponential distribution is applied to our model's empirical form.
Citation: Alaa M. Abd El-Latif, Hanan H. Sakr, Mohamed Said Mohamed. Fractional generalized cumulative residual entropy: properties, testing uniformity, and applications to Euro Area daily smoker data[J]. AIMS Mathematics, 2024, 9(7): 18064-18082. doi: 10.3934/math.2024881
The fractional generalized cumulative residual entropy, a broader version of the cumulative residual entropy, holds significance in assessing the uncertainty model of random variables and maintains straightforward connections with reliability models and crucial information. This article represents and modifies some novel features of the fractional generalized cumulative residual entropy and discusses the weak convergence. Additionally, the measure is utilized to assess uniformity, involving the derivation of the limit distribution and an approximation of the test statistic's distribution. Furthermore, the concept of stability is addressed. Moreover, the presentation includes the critical points and power analysis against alternative distributions of this test statistic. Furthermore, a simulation study is carried out to compare the power value of the proposed test with that of other tests of uniformity. Moreover, the uniformity test utilizes real data on daily smokers in the countries of the Euro Area. Finally, our model's exponential distribution is applied to our model's empirical form.

| [1] |
S. Abe, Stability of Tsallis entropy and instabilities of Renyi and normalized Tsallis entropies: a basis for q-exponential distributions, Phys. Rev. E, 66 (2002), 046134. http://dx.doi.org/10.1103/PhysRevE.66.046134 doi: 10.1103/PhysRevE.66.046134

|
| [2] |
S. Abe, G. Kaniadakis, A. M. Scarfone, Stabilities of generalized entropies, J. Phys. A: Math. Gen., 37 (2004), 10513. http://dx.doi.org/10.1088/0305-4470/37/44/004 doi: 10.1088/0305-4470/37/44/004
|
| [3] |
G. Alomani, M. Kayid, Stochastic properties of fractional generalized cumulative residual entropy and its extensions, Entropy, 24 (2022), 1041. http://dx.doi.org/10.3390/e24081041 doi: 10.3390/e24081041
|
| [4] | B. C. Arnold, N. Balakrishnan, H. N. Nagaraja, A First Course in Order Statistics, New York: Wiley, 1992. |
| [5] |
A. Di Crescenzo, S. Kayal, A. Meoli, Fractional generalized cumulative entropy and its dynamic version, Commun. Nonlinear Sci. Numer. Simul., 102 (2021), 105899. http://dx.doi.org/10.1016/j.cnsns.2021.105899 doi: 10.1016/j.cnsns.2021.105899
|
| [6] |
A. Di Crescenzo, M. Longobardi, On cumulative entropies, J. Stat. Plann. Infer., 139 (2009), 4072–4087. http://dx.doi.org/10.1016/j.jspi.2009.05.038 doi: 10.1016/j.jspi.2009.05.038
|
| [7] | Daily Smokers (indicator), OECD, 2024. http://dx.doi.org/10.1787/1ff488c2-en |
| [8] |
E. J. Dudewicz, E. C. Van der Meulen, Entropy-based tests of uniformity, J. Am. Stat. Assoc., 76 (1981), 967–974. http://dx.doi.org/10.1080/01621459.1981.10477750 doi: 10.1080/01621459.1981.10477750
|
| [9] |
G. T. Howard, A generalization of the Glivenko-Cantelli theorem, Ann. Math. Stat., 30 (1959), 828–830. http://dx.doi.org/10.1214/aoms/1177706212 doi: 10.1214/aoms/1177706212
|
| [10] |
B. Johannesson, N. Giri, On approximations involving the beta distribution, Commun. Stat. Simul. Comput., 24 (1995), 489–503. http://dx.doi.org/10.1080/03610919508813253 doi: 10.1080/03610919508813253
|
| [11] |
M. S. Mohamed, H. M. Barakat, S. A. Alyami, M. A. Abd Elgawad, Cumulative residual tsallis entropy-based test of uniformity and some new findings, Mathematics, 10 (2022), 771. http://dx.doi.org/10.3390/math10050771 doi: 10.3390/math10050771
|
| [12] |
M. S. Mohamed, H. M. Barakat, S. A. Alyami, M. A. Abd Elgawad, Fractional entropy-based test of uniformity with power comparisons, J. Math., 2021 (2021), 5331260. http://dx.doi.org/10.1155/2021/5331260 doi: 10.1155/2021/5331260
|
| [13] |
J. Navarro, Y. del Aguila, M. Asadi, Some new results on the cumulative residual entropy, J. Stat. Plann. Infer., 140 (2010), 310–322. http://dx.doi.org/10.1016/j.jspi.2009.07.015 doi: 10.1016/j.jspi.2009.07.015
|
| [14] |
H. A. Noughabi, Cumulative residual entropy applied to testing uniformity, Commun. Stat. Theory Meth., 51 (2022), 4151–4161. http://dx.doi.org/10.1080/03610926.2020.1811339 doi: 10.1080/03610926.2020.1811339
|
| [15] |
G. Psarrakos, J. Navarro, Generalized cumulative residual entropy and record values, Metrika, 76 (2013), 623–640. http://dx.doi.org/10.1007/s00184-012-0408-6 doi: 10.1007/s00184-012-0408-6
|
| [16] | C. M. Ramsay, Loading gross premiums for risk without using utility theory, Trans. Soc. Actuar., 45 (1993), 305–349. |
| [17] |
M. Rao, Y. Chen, B. C. Vemuri, F. Wang, Cumulative residual entropy: a new measure of information, IEEE Trans. Inf. Theory, 50 (2004), 1220–1228. http://dx.doi.org/10.1109/TIT.2004.828057 doi: 10.1109/TIT.2004.828057
|
| [18] |
M. A. Stephens, EDF statistics for goodness of fit and some comparisons, J. Am. Stat. Assoc., 69 (1974), 730–737. http://dx.doi.org/10.1080/01621459.1974.10480196 doi: 10.1080/01621459.1974.10480196
|
| [19] |
A. Toomaj, A. Di Crescenzo, Connections between weighted generalized cumulative residual entropy and variance, Mathematics, 8 (2020), 1072. http://dx.doi.org/10.3390/math8071072 doi: 10.3390/math8071072
|
| [20] | S. Wang, An actuarial index of the right-tail risk, N. Am. Actuar. J., 2 (1998), 88–101. |
| [21] |
F. Xiao, Quantum X-entropy in generalized quantum evidence theory, Inform. Sci., 643 (2023), 119177. http://dx.doi.org/10.1016/j.ins.2023.119177 doi: 10.1016/j.ins.2023.119177
|
| [22] |
H. Xiong, P. Shang, Y. Zhang, Fractional cumulative residual entropy, Commun. Nonlinear Sci. Numer. Simul., 78 (2019), 104879. http://dx.doi.org/10.1016/j.cnsns.2019.104879 doi: 10.1016/j.cnsns.2019.104879
|
| [23] | L. Yang, Study on cumulative residual entropy and variance as risk measure, In: Fifth International Conference on Business Intelligence and Financial Engineering, 2012. |
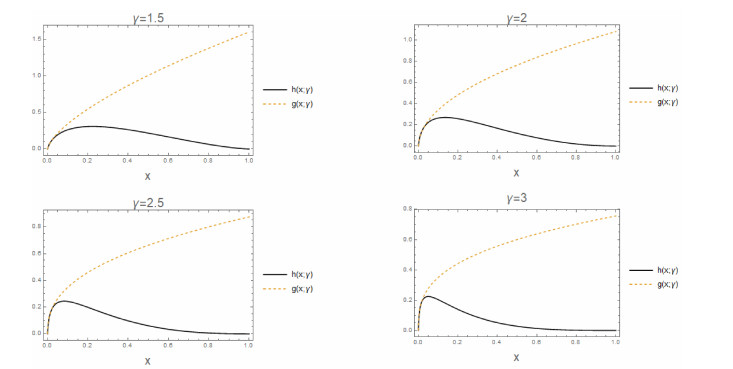






Figures(7) / Tables(4)

Alaa M. Abd El-Latif, Hanan H. Sakr, Mohamed Said Mohamed. Fractional generalized cumulative residual entropy: properties, testing uniformity, and applications to Euro Area daily smoker data[J]. AIMS Mathematics, 2024, 9(7): 18064-18082. doi: 10.3934/math.2024881







 DownLoad:
DownLoad: