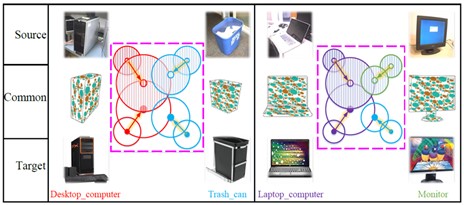
General learning algorithms trained on a specific dataset often have difficulty generalizing effectively across different domains. In traditional pattern recognition, a classifier is typically trained on one dataset and then tested on another, assuming both datasets follow the same distribution. This assumption poses difficulty for the solution to be applied in real-world scenarios. The challenge of making a robust generalization from data originated from diverse sources is called the domain adaptation problem. Many studies have suggested solutions for mapping samples from two domains into a shared feature space and aligning their distributions. To achieve distribution alignment, minimizing the maximum mean discrepancy (MMD) between the feature distributions of the two domains has been proven effective. However, this alignment of features between two domains ignores the essential class-wise alignment, which is crucial for adaptation. To address the issue, this study introduced a discriminative, class-wise deep kernel-based MMD technique for unsupervised domain adaptation. Experimental findings demonstrated that the proposed approach not only aligns the data distribution of each class in both source and target domains, but it also enhances the adaptation outcomes.
Citation: Hsiau-Wen Lin, Yihjia Tsai, Hwei Jen Lin, Chen-Hsiang Yu, Meng-Hsing Liu. Unsupervised domain adaptation with deep network based on discriminative class-wise MMD[J]. AIMS Mathematics, 2024, 9(3): 6628-6647. doi: 10.3934/math.2024323
General learning algorithms trained on a specific dataset often have difficulty generalizing effectively across different domains. In traditional pattern recognition, a classifier is typically trained on one dataset and then tested on another, assuming both datasets follow the same distribution. This assumption poses difficulty for the solution to be applied in real-world scenarios. The challenge of making a robust generalization from data originated from diverse sources is called the domain adaptation problem. Many studies have suggested solutions for mapping samples from two domains into a shared feature space and aligning their distributions. To achieve distribution alignment, minimizing the maximum mean discrepancy (MMD) between the feature distributions of the two domains has been proven effective. However, this alignment of features between two domains ignores the essential class-wise alignment, which is crucial for adaptation. To address the issue, this study introduced a discriminative, class-wise deep kernel-based MMD technique for unsupervised domain adaptation. Experimental findings demonstrated that the proposed approach not only aligns the data distribution of each class in both source and target domains, but it also enhances the adaptation outcomes.

| [1] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, In: Proceedings of conference on computer vision and pattern recognition (CVPR), 2016,770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [2] |
S. Ren, K. He, R. Girshick, J. Sun, Faster R-cnn: Towards real-time object detection with region proposal networks, IEEE Trans. Pattern Anal. Machine Intel., 39 (2017), 1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031 doi: 10.1109/TPAMI.2016.2577031

|
| [3] | K. He, G. Gkioxari, P. Dollár, R. Girshick, Mask R-CNN, In: 2017 IEEE International conference on computer vision (ICCV), 2017, 2980–2988. https://doi.org/10.1109/ICCV.2017.322 |
| [4] |
S. J. Pan, Q. Yang, A survey on transfer learning, IEEE Trans. Knowl. Data Eng., 22 (2010), 1345–1359. https://doi.org/10.1109/TKDE.2009.191 doi: 10.1109/TKDE.2009.191
|
| [5] | J. Huang, A. J. Smola, A. Gretton, K. M. Borgwardt, B. Schö lkopf, Correcting sample selection bias by unlabeled data, In: Advances in neural information processing systems, The MIT Press, 2007. https://doi.org/10.7551/mitpress/7503.003.0080 |
| [6] |
S. Li, S. Song, G. Huang, Prediction reweighting for domain adaptation, IEEE Trans. Neural Netw. Learn. Syst., 28 (2017), 1682–169. https://doi.org/10.1109/TNNLS.2016.2538282 doi: 10.1109/TNNLS.2016.2538282
|
| [7] | M. Baktashmotlagh, M. T. Harandi, B. C. Lovell, M. Salzmann, Domain adaptation on the statistical manifold, In: 2014 IEEE conference on computer vision and pattern recognition, 2014, 2481–2488. https://doi.org/10.1109/CVPR.2014.318 |
| [8] | M. Long, J. Wang, G. Ding, J. Sun, P. S. Yu, Transfer feature learning with joint distribution adaptation, In: 2013 IEEE international conference on computer vision, 2013, 2200–2207. https://doi.org/10.1109/ICCV.2013.274 |
| [9] | M. Long, J. Wang, G. Ding, J. Sun, P. S. Yu, Transfer joint matching for unsupervised domain adaptation, In: 2014 IEEE conference on computer vision and pattern recognition, 2014, 1410–1417. https://doi.org/10.1109/CVPR.2014.183 |
| [10] | M. Baktashmotlagh, M. T. Harandi, B. C. Lovell, M. Salzmann, Unsupervised domain adaptation by domain invariant projection, In: 2013 IEEE international conference on computer vision, 2013,769–776. https://doi.org/10.1109/ICCV.2013.100 |
| [11] | S. J. Pan, J. T. Kwok, Q. Yang, Transfer learning via dimensionality reduction, In: Proceedings of the AAAI conference on artificial intelligence, 23 (2008), 677–682. |
| [12] |
M. Long, J. Wang, G. Ding, S. J. Pan, P. S. Yu, Adaptation regularization: A general framework for transfer learning, IEEE Trans. Knowl. Data Eng., 26 (2014), 1076–1089. https://doi.org/10.1109/TKDE.2013.111 doi: 10.1109/TKDE.2013.111
|
| [13] |
L. Bruzzone, M. Marconcini, Domain adaptation problems: A DASVM classification technique and a circular validation strategy, IEEE Trans. Pattern Anal. Machine Intell., 32 (2010), 770–787. https://doi.org/10.1109/TPAMI.2009.57 doi: 10.1109/TPAMI.2009.57
|
| [14] | W. Zhang, W. Ouyang, W. Li, D. Xu, Collaborative and adversarial network for unsupervised domain adaptation, In: 2018 IEEE/CVF conference on computer vision and pattern recognition, 2018. https://doi.org/10.1109/CVPR.2018.00400 |
| [15] | K. Bousmalis, N. Silberman, D. Dohan, D. Erhan, D. Krishnan, Unsupervised pixel-level domain adaptation with generative adversarial networks, In: 2017 IEEE conference on computer vision and pattern recognition (CVPR), 2017, 95–104. https://doi.org/10.1109/CVPR.2017.18 |
| [16] | Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, et al., Domain adversarial training of neural networks, J. Machine Learn. Res., 17 (2016), 1–35. |
| [17] | E. Tzeng, J. Hoffman, K. Saenko, T. Darrell, Adversarial discriminative domain adaptation, In: 2017 IEEE conference on computer vision and pattern recognition (CVPR), 2017, 2962–2971. https://doi.org/10.1109/CVPR.2017.316 |
| [18] | M. Long, Y. Cao, J. Wang, M. I. Jordan, Learning transferable features with deep adaptation networks, In: Proceedings of the 32nd international conference on international conference on machine learning, 37 (2015), 97–105. |
| [19] | M. Long, H. Zhu, J. Wang, M. I. Jordan, Unsupervised domain adaptation with residual transfer networks, In: Proceedings of the 30th international conference on neural information processing systems, 2016, 136–144. https://dl.acm.org/doi/10.5555/3157096.3157112 |
| [20] | B. Sun and K. Saenko, Deep coral: Correlation alignment for deep domain adaptation, In: European conference on computer vision, 2016,443–450. https://doi.org/10.1007/978-3-319-49409-8_35 |
| [21] | M. Ghifary, W. B. Kleijn, M. Zhang, D. Balduzzi, W. Li, Deep reconstruction-classification networks for unsupervised domain adaptation, In: European conference on computer vision, 2016,597–613. https://doi.org/10.1007/978-3-319-46493-0_36 |
| [22] |
S. Khan, M. Asim, S. Khan, A. Musyafa, Q. Wu, Unsupervised domain adaptation using fuzzy rules and stochastic hierarchical convolutional neural networks, Comput. Elect. Eng., 105 (2023), 108547. https://doi.org/10.1016/j.compeleceng.2022.108547 doi: 10.1016/j.compeleceng.2022.108547
|
| [23] |
S. Khan, Y. Guo, Y. Ye, C. Li, Q. Wu, Mini-batch dynamic geometric embedding for unsupervised domain adaptation, Neural Process. Lett., 55 (2023), 2063–2080. https://doi.org/10.1007/s11063-023-11167-7 doi: 10.1007/s11063-023-11167-7
|
| [24] |
L. Zhang, W. Zuo, D. Zhang, LSDT: Latent sparse domain transfer learning for visual adaptation, IEEE Trans. Image Process., 25 (2016), 1177–1191. https://doi.org/10.1109/TIP.2016.2516952 doi: 10.1109/TIP.2016.2516952
|
| [25] | Y. Chen, W. Li, C. Sakaridis, D. Dai, L. V. Gool, Domain adaptive faster R-CNN for object detection in the wild, In: 2018 IEEE/CVF conference on computer vision and pattern recognition, 2018, 3339–3348. https://doi.org/10.1109/CVPR.2018.00352 |
| [26] | K. Bousmalis, N. Silberman, D. Dohan, D. Erhan, D. Krishnan, Unsupervised pixel-level domain adaptation with generative adversarial networks, In: 2017 IEEE conference on computer vision and pattern recognition (CVPR), 2017, 95–104. https://doi.org/10.1109/CVPR.2017.18 |
| [27] | H. Xu, J. Zheng, A. Alavi, R. Chellappa, Cross-domain visual recognition via domain adaptive dictionary learning, arXiv: 1804.04687, 2018. https://doi.org/10.48550/arXiv.1804.04687 |
| [28] | A. Gretton, K. M. Borgwardt, M. J. Rasch, B. Scholkopf, A. Smola, A kernel two-sample test, J. Machine Learn. Res., 13 (2012), 723–773. https://doi.org/10.5555/2188385.2188410 |
| [29] |
S. J. Pan, I. W. Tsang, J. T. Kwok, Q. Yang, Domain adaptation via transfer component analysis, IEEE Trans. Neural Netw., 22 (2011), 199–210. https://doi.org/10.1109/TNN.2010.2091281 doi: 10.1109/TNN.2010.2091281
|
| [30] |
K. M. Borgwardt, A. Gretton, M. J. Rasch, H. P. Kriegel, B. Scholkopf, A. J. Smola, Integrating structured biological data by kernel maximum mean discrepancy, Bioinformatics, 22 (2006), e49–e57. https://doi.org/10.1093/bioinformatics/btl242 doi: 10.1093/bioinformatics/btl242
|
| [31] |
S. Si, D. Tao, B. Geng, Bregman divergence-based regularization for transfer subspace learning, IEEE Trans. Knowl. Data Eng., 22 (2010), 929–942. https://doi.org/10.1109/TKDE.2009.126 doi: 10.1109/TKDE.2009.126
|
| [32] | J. Blitzer, K. Crammer, A. Kulesza, F. Pereira, J. Wortman, Learning bounds for domain adaptation, In: Advances in neural information processing systems, 20 (2007), 129–136. |
| [33] | W. Wang, H. Li, Z. Ding, Z. Wang, Rethink maximum mean discrepancy for domain adaptation, arXiv: 2007.00689, 2020. https://doi.org/10.48550/arXiv.2007.00689 |
| [34] | L. Devroye, G. Lugosi, Combinatorial methods in density estimation, In: Combinatorial methods in density estimation, New York: Springer, 2001. https://doi.org/10.1007/978-1-4613-0125-7 |
| [35] |
Y. Baraud, L. Birgé, Rho-estimators revisited: General theory and applications, Ann. Statist., 46 (2018), 3767–3804. https://doi.org/10.1214/17-AOS1675 doi: 10.1214/17-AOS1675
|
| [36] | J. Liang, D. Hu, J. Feng, Do we really need to access the source data? Source hypothesis transfer for unsupervised domain adaptation, In: Proceedings of the 37th international conference on machine learning, 119 (2020), 6028–6039. |
| [37] | L. Song, A. Gretton, D. Bickson, Y. Low, C. Guestrin, Kernel belief propagation, In: Proceedings of the 14th international conference on artificial intelligence and statistics, 15 (2011), 707–715. |
| [38] | M. Park, W. Jitkrittum, D. Sejdinovic, K2-ABC: Approximate bayesian computation with kernel embeddings, In: Proceedings of the 19th international conference on artificial intelligence and statistics, 51 (2015), 398–407. |
| [39] | W. Jitkrittum, W. Xu, Z. Szabo, K. Fukumizu, A. Gretton, A linear-time kernel goodness-of-fit test, In: Advances in neural information processing systems, 2017, 262–271. |
| [40] |
Y. Li, K. Swersky, R. S. Zemel, Generative moment matching networks, arXiv:1502.02761, 2015. https://doi.org/10.48550/arXiv.1502.02761 doi: 10.48550/arXiv.1502.02761
|
| [41] |
S. Zhao, J. Song, S. Ermon, Infovae: Information maximizing variational autoencoders, arXiv:1706.02262, 2018. https://doi.org/10.48550/arXiv.1706.02262 doi: 10.48550/arXiv.1706.02262
|
| [42] | R. Müller, S. Kornblith, G. Hinton, When does label smoothing help? In: 33rd Conference on neural information processing systems, 2019. |
| [43] | Y. Grandvalet, Y. Bengio, Semi-supervised learning by entropy minimization, In: Advances in neural information processing systems, 17 (2004), 529–536. |
| [44] |
Y. Lecun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based learning applied to document recognition, Proc. IEEE, 86 (1998), 2278–2324. https://doi.org/10.1109/5.726791 doi: 10.1109/5.726791
|
| [45] |
J. J. Hull, A database for handwritten text recognition research, IEEE Trans. Pattern Anal. Machine Intell., 16 (1994), 550–55. https://doi.org/10.1109/34.291440 doi: 10.1109/34.291440
|
| [46] | Y. Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, A. Ng, Reading digits in natural images with unsupervised feature learning, Proc. Int. Conf. Neural Inf. Process. Syst. Workshops, 2011. |
| [47] | K. Saenko, B. Kulis, M. Fritz, T. Darrell, Adapting visual category models to new domains, In: Lecture notes in computer science, Berlin: Springer, 6314 (2010), 213–226. https://doi.org/10.1007/978-3-642-15561-1_16 |
| [48] |
K. Saito, Y. Ushiku, T. Harada, K. Saenko, Adversarial dropout regularization, arXiv:1711.01575, 2018. https://doi.org/10.48550/arXiv.1711.01575 doi: 10.48550/arXiv.1711.01575
|
| [49] | M. Long, Z. Cao, J. Wang, M. I. Jordan, Conditional adversarial domain adaptation, In: 32nd Conference on neural information processing systems, 2018, 1647–1657. |
| [50] | J. Hoffman, E. Tzeng, T. Park, J. Y. Zhu, P. Isola, K. Saenko, et al., Cycada: Cycle-consistent adversarial domain adaptation, In: Proceedings of the 35th international conference on machine learning, 2018, 1989–1998. |
| [51] | C. Y. Lee, T. Batra, M. H. Baig, D. Ulbricht, Sliced wasserstein discrepancy for unsupervised domain adaptation, In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2019, 10285–10295. |
| [52] | Z. Pei, Z. Cao, M. Long, J. Wang, Multi-adversarial domain adaptation, In: Thirty-second AAAI conference on artificial intelligence, 32 (2018). https://doi.org/10.1609/aaai.v32i1.11767 |



Figures(4) / Tables(3)

Hsiau-Wen Lin, Yihjia Tsai, Hwei Jen Lin, Chen-Hsiang Yu, Meng-Hsing Liu. Unsupervised domain adaptation with deep network based on discriminative class-wise MMD[J]. AIMS Mathematics, 2024, 9(3): 6628-6647. doi: 10.3934/math.2024323







 DownLoad:
DownLoad: