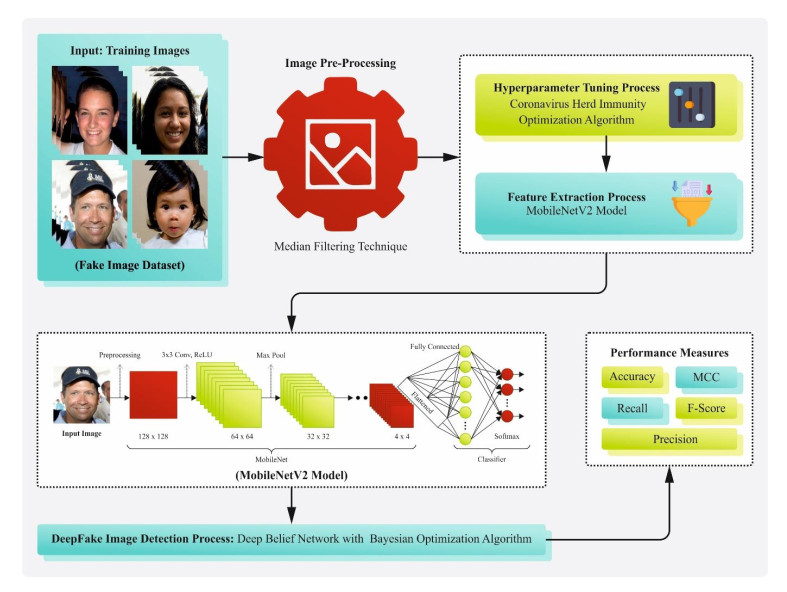
Deepfake images are combined media constructed from deep learning (DL) methods, usually Generative Adversarial Networks (GANs), to manipulate visual content, often giving rise to convincing and fabricating descriptions of scenes or people. The Bayesian machine learning (ML) model has made crucial strides over the past two decades, illustrating promise in diverse applications. In deepfake images, detection utilizes computer vision (CV) and ML to spot manipulated content by analyzing unique artefacts and patterns. Recent techniques utilize DL to train neural networks to discriminate between real and fake images, improving the fight against digital manipulation and preserving media integrity. These systems can efficiently detect subtle inconsistencies or anomalies specific to deepfake creations by learning from large datasets of both real and deepfake images. This enables the mitigation of fraudulent content and reliable detection in digital media. We introduce a new Coronavirus Herd Immunity Optimizer with a Deep Learning-based Deepfake Image Detection and Classification (CHIODL-DIDC) technique. The CHIODL-DIDC technique aimed to detect and classify the existence of fake images. To accomplish this, the CHIODL-DIDC technique initially used a median filtering (MF) based image filtering approach. Besides, the CHIODL-DIDC technique utilized the MobileNetv2 model for extracting feature vectors. Moreover, the hyperparameter tuning of the MobileNetv2 model was accomplished using the CHIO method. For deepfake image detection, the CHIODL-DIDC technique implements the deep belief network (DBN) model. Finally, the Bayesian optimization algorithm (BOA) was utilized to select the effectual hyperparameter of the DBN model. The CHIODL-DIDC method's empirical analysis was examined using a benchmark fake image dataset. The performance validation of the CHIODL-DIDC technique illustrated a superior accuracy value of 98.16% over other models under $ Acc{u}_{y} $ , $ Pre{c}_{n} $ , $ Rec{a}_{l} $ , $ {F}_{Score} $ , and MCC metrics.
Citation: Wahida Mansouri, Amal Alshardan, Nazir Ahmad, Nuha Alruwais. Deepfake image detection and classification model using Bayesian deep learning with coronavirus herd immunity optimizer[J]. AIMS Mathematics, 2024, 9(10): 29107-29134. doi: 10.3934/math.20241412
Deepfake images are combined media constructed from deep learning (DL) methods, usually Generative Adversarial Networks (GANs), to manipulate visual content, often giving rise to convincing and fabricating descriptions of scenes or people. The Bayesian machine learning (ML) model has made crucial strides over the past two decades, illustrating promise in diverse applications. In deepfake images, detection utilizes computer vision (CV) and ML to spot manipulated content by analyzing unique artefacts and patterns. Recent techniques utilize DL to train neural networks to discriminate between real and fake images, improving the fight against digital manipulation and preserving media integrity. These systems can efficiently detect subtle inconsistencies or anomalies specific to deepfake creations by learning from large datasets of both real and deepfake images. This enables the mitigation of fraudulent content and reliable detection in digital media. We introduce a new Coronavirus Herd Immunity Optimizer with a Deep Learning-based Deepfake Image Detection and Classification (CHIODL-DIDC) technique. The CHIODL-DIDC technique aimed to detect and classify the existence of fake images. To accomplish this, the CHIODL-DIDC technique initially used a median filtering (MF) based image filtering approach. Besides, the CHIODL-DIDC technique utilized the MobileNetv2 model for extracting feature vectors. Moreover, the hyperparameter tuning of the MobileNetv2 model was accomplished using the CHIO method. For deepfake image detection, the CHIODL-DIDC technique implements the deep belief network (DBN) model. Finally, the Bayesian optimization algorithm (BOA) was utilized to select the effectual hyperparameter of the DBN model. The CHIODL-DIDC method's empirical analysis was examined using a benchmark fake image dataset. The performance validation of the CHIODL-DIDC technique illustrated a superior accuracy value of 98.16% over other models under $ Acc{u}_{y} $ , $ Pre{c}_{n} $ , $ Rec{a}_{l} $ , $ {F}_{Score} $ , and MCC metrics.

| [1] |
S. Solaiyappan, Y. X. Wen, Machine learning based medical image deepfake detection: A comparative study, Mach. Learn. Appl., 8 (2022), 100298. https://doi.org/10.1016/j.mlwa.2022.100298 doi: 10.1016/j.mlwa.2022.100298

|
| [2] |
T. Zhang, Deepfake generation and detection, a survey, Multimed. Tools Appl., 81 (2022), 6259–6276. https://doi.org/10.1007/s11042-021-11733-y doi: 10.1007/s11042-021-11733-y
|
| [3] | C. C. Hsu, C. Y. Lee, Y. X. Zhuang, Learning to detect fake face images in the wild, In 2018 international symposium on computers, consumers, and control (IS3C), IEEE, 2018,388–391. https://doi.org/10.1109/IS3C.2018.00104 |
| [4] | H. Chi, M. Peng, Toward robust deep learning systems against deepfake for digital forensics, In Cybersecurity and HighPerformance Computing Environments, Chapman and Hall/CRC, 2022,309–331. |
| [5] |
M. Tanaka, S. Shiota, H. Kiya, A detection method of operating fake images using robust hashing, J. Imaging, 7 (2021), 134. https://doi.org/10.3390/jimaging7080134 doi: 10.3390/jimaging7080134
|
| [6] | Z. Liu, X. Qi, P. H. S. Torr, Global texture enhancement for fake face detection in the wild, In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, 8060–8069. https://doi.org/10.1109/CVPR42600.2020.00808 |
| [7] |
J. Yang, A. Li, S. Xiao, W. Lu, X. Gao, Mtdnet: Learning to detect deepfakes images by multi-scale texture difference, IEEE T. Inf. Foren. Sec., 16 (2021), 4234–4245. https://doi.org/10.1109/TIFS.2021.3102487 doi: 10.1109/TIFS.2021.3102487
|
| [8] | L. Nataraj, T. Manhar, S. Chandrasekaran, A. Flenner, J. H. Bappy, A. K. R. Chowdhury, et al., Detecting gan generated fake images using cooccurrence matrices, arXiv Preprint, 2019. https://doi.org/10.2352/ISSN.2470-1173.2019.5.MWSF-532 |
| [9] | J. Pu, N. Mangaokar, L. Kelly, P. Bhattacharya, K. Sundaram, M. Javed, et al., Deepfake videos in the wild: Analysis and detection, In: Proceedings of the Web Conference, 2021 (2021), 981–992. https://doi.org/10.1145/3442381.34499 |
| [10] |
M. Masood, M. Nawaz, K. Mahmood, A. Javed, A. Irtaza, H. Malik, Deepfakes generation and detection: Stateof-the-art, open challenges, countermeasures, and way forward, Appl. Intell., 53 (2023), 3974–4026. https://doi.org/10.1007/s10489-022-03766-z doi: 10.1007/s10489-022-03766-z
|
| [11] |
R. D. Sushir, D. G. Wakde, S. S. Bhutada, Enhanced blind image forgery detection using an accurate deep learning based hybrid DCCAE and ADFC, Multimed. Tools Appl., 83 (2024), 1725–1752. https://doi.org/10.1007/s11042-023-15475-x doi: 10.1007/s11042-023-15475-x
|
| [12] |
S. T. Suganthi, M. U. A. Ayoobkhan, N. Bacanin, K. Venkatachalam, H. Štěpán, T. Pavel, Deep learning model for deep fake face recognition and detection, PeerJ Comput. Sci., 8 (2022), e881. https://doi.org/10.7717/peerj-cs.881 doi: 10.7717/peerj-cs.881
|
| [13] | S. Ghosh, S. Kayal, M. Malakar, A. Sengupta, S. Srimani, A. Das, FaceDig: A deep neural network-based fake image detection scheme, In: Emerging Electronic Devices, Circuits and Systems: Select Proceedings of EEDCS Workshop Held in Conjunction with ISDCS, Singapore: Springer Nature, 2022,395–404. https://doi.org/10.1007/978-981-99-0055-8_33 |
| [14] | E. Hashmi, S. Y. Yayilgan, M. M. Yamin, S. Ali, M. Abomhara, Advancing fake news detection: Hybrid deep learning with fasttext and explainable AI, IEEE Access, 2024. https://doi.org/10.1109/ACCESS.2024.3381038 |
| [15] | A. Boyd, P. Tinsley, K. W. Bowyer, A. Czajka, Cyborg: Blending human saliency into the loss improves deep learning-based synthetic face detection, In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2023, 6108–6117. https://doi.org/10.1109/WACV56688.2023.00605 |
| [16] |
S. Li, V. Dutta, X. He, T. Matsumaru, Deep learning based one-class detection system for fake faces generated by GAN network, Sensors, 22 (2022), 7767. https://doi.org/10.3390/s22207767 doi: 10.3390/s22207767
|
| [17] |
S. M. Dwivedi, S. B. Wankhade, Deep learning based semantic model for multimodal fake news detection, Int. J. Intell. Eng. Syst., 17 (2024). https://doi.org/10.22266/ijies2024.0229.55 doi: 10.22266/ijies2024.0229.55
|
| [18] |
C. Mallick, S. Mishra, M. R. Senapati, A cooperative deep learning model for fake news detection in online social networks, J. Amb. Intel. Hum. Comp., 14 (2023), 4451–4460. https://doi.org/10.1007/s12652-023-04562-4 doi: 10.1007/s12652-023-04562-4
|
| [19] |
I. Zhang, D. Zhao, C. P. Lim, H. Asadi, H. Huang, Y. Yu, et al., Video deepfake classification using particle swarm optimization-based evolving ensemble models, Knowl.-Based Syst., 289 (2024), 111461. https://doi.org/10.1016/j.knosys.2024.111461 doi: 10.1016/j.knosys.2024.111461
|
| [20] |
P. Chen, M. Xu, J. Qi, DeepFake detection against adversarial examples based on D‐VAEGAN, IET Image Process., 18 (2024), 615–626. https://doi.org/10.1049/ipr2.12973 doi: 10.1049/ipr2.12973
|
| [21] |
K. Omar, R. H. Sakr, M. F. Alrahmawy, An ensemble of CNNs with self-attention mechanism for DeepFake video detection, Neural Comput. Appl., 36 (2024), 2749–2765. https://doi.org/10.1007/s00521-023-09196-3 doi: 10.1007/s00521-023-09196-3
|
| [22] | L. Yang, W. Shu, Y. Wang, Z. Lian, Integration model of deep forgery video detection based on rPPG and spatiotemporal signal, In International Conference on Green, Pervasive, and Cloud Computing, Singapore: Springer Nature, 2023,113–127. https://doi.org/10.1007/978-981-99-9893-7_9 |
| [23] | A. A. Hasanaath, H. Luqman, R. F. Katib, S. Anwar, FSBI: Deepfakes detection with frequency enhanced self-blended images, Hamzah and KATIB, RAED FAROUQ and Anwar, Saeed, 2024. https://doi.org/10.2139/ssrn.4869258 |
| [24] | P. K. Rangarajan, M. Sukesh, D. M. Abinandhini, Y. Jaikanth, Detecting AI-generated images with CNN and Interpretation using Explainable AI, In 2024 IEEE International Conference on Contemporary Computing and Communications (InC4), IEEE, 1 (2024), 1–6. https://doi.org/10.1109/InC460750.2024.10649158 |
| [25] |
H. Ilyas, A. Javed, K. M. Malik, AVFakeNet: A unified end-to-end dense swin transformer deep learning model for audio-visual deepfakes detection, Appl. Soft Comput., 136 (2023), 110124. https://doi.org/10.1016/j.asoc.2023.110124 doi: 10.1016/j.asoc.2023.110124
|
| [26] | T. Ige, C. Kiekintveld, A. Piplai, Deep learning-based speech and vision synthesis to improve phishing attack detection through a multilayer adaptive framework, arXiv Preprint, 2024. https://doi.org/10.20944/preprints202402.1557.v1 |
| [27] | B. Liu, B. Liu, M. Ding, T. Zhu, Detection of diffusion model-generated faces by assessing smoothness and noise tolerance, In 2024 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), IEEE, 2024, 1–6. https://doi.org/10.1109/BMSB62888.2024.10608232 |
| [28] |
A. Noor, Y. Zhao, R. Khan, L. Wu, F. Y. Abdalla, Median filters combined with denoising convolutional neural network for Gaussian and impulse noises, Multimed. Tools Appl., 79 (2020), 18553–18568. https://doi.org/10.1007/s11042-020-08657-4 doi: 10.1007/s11042-020-08657-4
|
| [29] | A. D. Raha, M. Gain, R. Debnath, A. Adhikary, Y. Qiao, M. M. Hassan, et al., Attention to Monkeypox: An interpretable Monkeypox detection technique using attention mechanism, IEEE Access, 2024. |
| [30] | H. Selim, A. Y. Haikal, L. M. Labib, M. M. Saafan, MCHIAO: A modified coronavirus herd immunity-Aquila optimization algorithm based on chaotic behavior for solving engineering problems, Neural Comput. Appl., 2024, 1–85. https://doi.org/10.1007/s00521-024-09533-0 |
| [31] |
M. Guo, R. Lv, Z. Miao, F. Fei, Z. Fu, E. Wu, et al., Load forecasting and operation optimization of ice-storage air conditioners based on improved deep-belief network, Processes, 12 (2024), 523. https://doi.org/10.3390/pr12030523 doi: 10.3390/pr12030523
|
| [32] |
R. Zhou, S. Qiu, M. Li, S. Meng, Q. Zhang, Short-term air traffic flow prediction based on CEEMD-LSTM of Bayesian optimization and differential processing, Electronics, 13 (2024), 1896. https://doi.org/10.3390/electronics13101896 doi: 10.3390/electronics13101896
|
| [33] | https://www.kaggle.com/datasets/xhlulu/140k-real-and-fake-faces |
| [34] | S. A. Raza, U. Habib, M. Usman, A. A. Cheema, M. S. Khan, MMGANGuard: A robust approach for detecting fake images generated by GANs using multi-model techniques, IEEE Access, 2024. https://doi.org/10.1109/ACCESS.2024.3393842 |
| [35] |
J. Gao, M. Micheletto, G. Orrù, S. Concas, X. Feng, G. L. Marcialis, et al., Texture and artifact decomposition for improving generalization in deep-learning-based deepfake detection, Eng. Appl. Artif. Intel., 133 (2024), 108450. https://doi.org/10.1016/j.engappai.2024.108450 doi: 10.1016/j.engappai.2024.108450
|













Figures(14) / Tables(4)

Wahida Mansouri, Amal Alshardan, Nazir Ahmad, Nuha Alruwais. Deepfake image detection and classification model using Bayesian deep learning with coronavirus herd immunity optimizer[J]. AIMS Mathematics, 2024, 9(10): 29107-29134. doi: 10.3934/math.20241412







 DownLoad:
DownLoad: