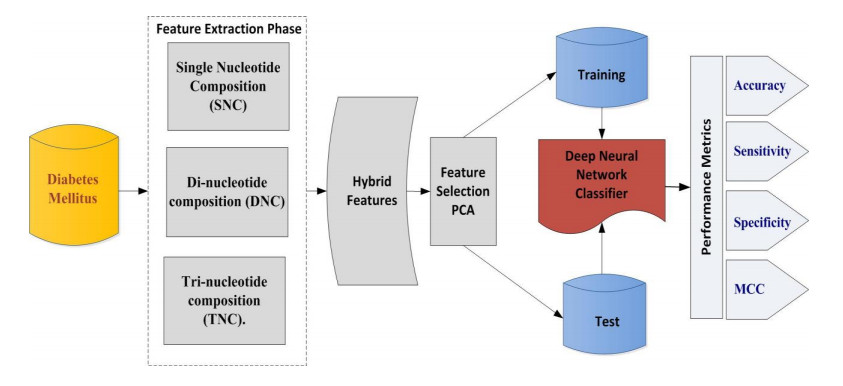
Diabetes mellitus is a severe, chronic disease that occurs when blood glucose levels rise above certain limits. Many complications arise if diabetes remains untreated and unidentified. Early prediction of diabetes is the most high-quality way to forestall and manipulate diabetes and its complications. With the rising incidence of diabetes, machine learning and deep learning algorithms have been increasingly used to predict diabetes and its complications due to their capacity to care for massive and complicated facts sets. This research aims to develop an intelligent computational model that can accurately predict the probability of diabetes in patients at an early stage. The proposed predictor employs hybrid pseudo-K-tuple nucleotide composition (PseKNC) for sequence formulation, an unsupervised principal component analysis (PCA) algorithm for discriminant feature selection, and a deep neural network (DNN) as a classifier. The experimental results show that the proposed technique can perform better on benchmark datasets. Furthermore, overall assessment performance compared to existing predictors indicated that our predictor outperformed the cutting-edge predictors using 10-fold cross validation. It is anticipated that the proposed model could be a beneficial tool for diabetes diagnosis and precision medicine.
Citation: Salman khan, Muhammad Naeem, Muhammad Qiyas. Deep intelligent predictive model for the identification of diabetes[J]. AIMS Mathematics, 2023, 8(7): 16446-16462. doi: 10.3934/math.2023840
Diabetes mellitus is a severe, chronic disease that occurs when blood glucose levels rise above certain limits. Many complications arise if diabetes remains untreated and unidentified. Early prediction of diabetes is the most high-quality way to forestall and manipulate diabetes and its complications. With the rising incidence of diabetes, machine learning and deep learning algorithms have been increasingly used to predict diabetes and its complications due to their capacity to care for massive and complicated facts sets. This research aims to develop an intelligent computational model that can accurately predict the probability of diabetes in patients at an early stage. The proposed predictor employs hybrid pseudo-K-tuple nucleotide composition (PseKNC) for sequence formulation, an unsupervised principal component analysis (PCA) algorithm for discriminant feature selection, and a deep neural network (DNN) as a classifier. The experimental results show that the proposed technique can perform better on benchmark datasets. Furthermore, overall assessment performance compared to existing predictors indicated that our predictor outperformed the cutting-edge predictors using 10-fold cross validation. It is anticipated that the proposed model could be a beneficial tool for diabetes diagnosis and precision medicine.

| [1] |
J. M. Lachin, D. M. Nathan, Understanding metabolic memory: The prolonged influence of glycemia during the diabetes control and complications trial (DCCT) on future risks of complications during the study of the epidemiology of diabetes interventions and complications (EDIC), Diabetes Care, 44 (2021), 2216–2224. http://doi.org/10.2337/dc20-3097 doi: 10.2337/dc20-3097

|
| [2] |
C. Greenhill, How does leptin decrease hyperglycaemia in T1DM and T2DM?, Nat. Rev. Endocrinol., 10 (2014), 511. http://doi.org/10.1038/nrendo.2014.104 doi: 10.1038/nrendo.2014.104
|
| [3] |
J. Schofield, J. Ho, H. Soran, Cardiovascular risk in type 1 diabetes mellitus, Diabetes Ther., 10 (2019), 773–789. http://doi.org/10.1007/s13300-019-0612-8 doi: 10.1007/s13300-019-0612-8
|
| [4] |
H. Cho, C. H. Kim, E. Q. Knight, H. W. Oh, B. Park, D. G. Kim, et al., Changes in brain metabolic connectivity underlie autistic-like social deficits in a rat model of autism spectrum disorder, Sci. Rep., 7 (2017), 13213. http://doi.org/10.1038/s41598-017-13642-3 doi: 10.1038/s41598-017-13642-3
|
| [5] |
M. Huber, L. Beyer, C. Prix, S. Schönecker, C. Palleis, B.-S. Rauchmann, et al., Metabolic correlates of dopaminergic loss in dementia with Lewy bodies, Mov. Disord., 35 (2020), 595–605. http://doi.org/10.1002/mds.27945 doi: 10.1002/mds.27945
|
| [6] |
F. S. Chiwanga, M. A. Njelekela, M. B. Diamond, F. Bajunirwe, D. Guwatudde, J. Nankya-Mutyoba, et al., Urban and rural prevalence of diabetes and pre-diabetes and risk factors associated with diabetes in Tanzania and Uganda, Global Health Action, 9 (2016), 31440. http://doi.org/10.3402/gha.v9.31440 doi: 10.3402/gha.v9.31440
|
| [7] |
A. Basit, A. Fawwad, H. Qureshi, A. S. Shera, Prevalence of diabetes, pre-diabetes and associated risk factors: second National Diabetes Survey of Pakistan (NDSP), 2016–2017, BMJ Open, 8 (2018), e020961. http://doi.org/10.1136/bmjopen-2017-020961 doi: 10.1136/bmjopen-2017-020961
|
| [8] |
M. D. Campbell, T. Sathish, P. Z. Zimmet, K. R. Thankappan, B. Oldenburg, D. R. Owens, et al., Benefit of lifestyle-based T2DM prevention is influenced by prediabetes phenotype, Nat. Rev. Endocrinol., 16 (2020), 395–400. http://doi.org/10.1038/s41574-019-0316-1 doi: 10.1038/s41574-019-0316-1
|
| [9] |
C. Ao, L. Yu, Q. Zou, Prediction of bio-sequence modifications and the associations with diseases, Brief. Funct. Genomics, 20 (2021), 1–18. http://doi.org/10.1093/bfgp/elaa023 doi: 10.1093/bfgp/elaa023
|
| [10] |
M. Higazy, A. El-Mesady, A. M. S. Mahdy, S. Ullah, A. Al-Ghamdi, Numerical, approximate solutions, and optimal control on the deathly Lassa hemorrhagic fever disease in pregnant women, J. Funct. Space., 2021 (2021), 2444920. http://doi.org/10.1155/2021/2444920 doi: 10.1155/2021/2444920
|
| [11] |
A. El-Mesady, A. Elsonbaty, W. Adel, On nonlinear dynamics of a fractional order monkeypox virus model, Chaos Soliton. Fract., 164 (2022), 112716. http://doi.org/10.1016/j.chaos.2022.112716 doi: 10.1016/j.chaos.2022.112716
|
| [12] |
I. Johansson, A. Norhammar, Diabetes and heart failure notions from epidemiology including patterns in low-, middle- and high-income countries, Diabetes Res. Clin. Pract., 177 (2021), 108822. http://doi.org/10.1016/j.diabres.2021.108822 doi: 10.1016/j.diabres.2021.108822
|
| [13] |
E. W. Gregg, N. Sattar, M. K. Ali, The changing face of diabetes complications, Lancet Diabetes Endocrinol., 4 (2016), 537–547. http://doi.org/10.1016/S2213-8587(16)30010-9 doi: 10.1016/S2213-8587(16)30010-9
|
| [14] |
J. Kälsch, L. P. Bechmann, D. Heider, J. Best, P. Manka, H. Kälsch, et al., Normal liver enzymes are correlated with severity of metabolic syndrome in a large population based cohort, Sci. Rep., 5 (2015), 13058. http://doi.org/10.1038/srep13058 doi: 10.1038/srep13058
|
| [15] |
Q. Zou, K. Qu, Y. Luo, D. Yin, Y. Ju, H. Tang, Predicting diabetes mellitus with machine learning techniques, Front. Genet., 9 (2018), 515. http://doi.org/10.3389/fgene.2018.00515 doi: 10.3389/fgene.2018.00515
|
| [16] |
U. M. Butt, S. Letchmunan, M. Ali, F. H. Hassan, A. Baqir, H. H. R. Sherazi, Machine learning based diabetes classification and prediction for healthcare applications, J. Healthc. Eng., 2021 (2021), 9930985. http://doi.org/10.1155/2021/9930985 doi: 10.1155/2021/9930985
|
| [17] |
R. Rajni, A. Amandeep, RB-Bayes algorithm for the prediction of diabetic in Pima Indian dataset, International Journal of Electrical and Computer Engineering, 9 (2019), 4866–4872. http://doi.org/10.11591/ijece.v9i6.pp4866-4872 doi: 10.11591/ijece.v9i6.pp4866-4872
|
| [18] |
D. Sisodia, D. S. Sisodia, Prediction of diabetes using classification algorithms, Procedia Computer Science, 132 (2018), 1578–1585. http://doi.org/10.1016/j.procs.2018.05.122 doi: 10.1016/j.procs.2018.05.122
|
| [19] | N. Pradhan, G. Rani, V. S. Dhaka, R. C. Poonia, 14-Diabetes prediction using artificial neural network, In: Deep learning techniques for biomedical and health informatics, Academic Press, 2020,327–339. https://doi.org/10.1016/B978-0-12-819061-6.00014-8 |
| [20] |
K.-C. Chou, Impacts of bioinformatics to medicinal chemistry, Med. Chem., 11 (2015), 218–234. http://doi.org/10.2174/1573406411666141229162834 doi: 10.2174/1573406411666141229162834
|
| [21] |
P. Du, S. Gu, Y. Jiao, PseAAC-General: fast building various modes of general form of chou's pseudo-amino acid composition for large-scale protein datasets, Int. J. Mol. Sci., 15 (2014), 3495–3506. http://doi.org/10.3390/ijms15033495 doi: 10.3390/ijms15033495
|
| [22] |
K.-C. Chou, Pseudo amino acid composition and its applications in bioinformatics, proteomics and system biology, Curr. Proteomics, 6 (2009), 262–274. http://doi.org/10.2174/157016409789973707 doi: 10.2174/157016409789973707
|
| [23] |
K. Chou, An insightful recollection since the birth of Gordon Life Science Institute about 17 years ago, Adv. Sci. Eng. Res., 4 (2019), 31–36. http://doi.org/10.33495/aser_v4i2.19.105 doi: 10.33495/aser_v4i2.19.105
|
| [24] |
B. Liu, F. Liu, L. Fang, X. Wang, K.-C. Chou, repRNA: a web server for generating various feature vectors of RNA sequences, Mol. Genet. Genomics, 291 (2016), 473–481. http://doi.org/10.1007/s00438-015-1078-7 doi: 10.1007/s00438-015-1078-7
|
| [25] |
B. Liu, F. Liu, L. Fang, X. Wang, K.-C. Chou, RepDNA: a Python package to generate various modes of feature vectors for DNA sequences by incorporating user-defined physicochemical properties and sequence-order effects, Bioinformatics, 31 (2015), 1307–1309. http://doi.org/10.1093/bioinformatics/btu820 doi: 10.1093/bioinformatics/btu820
|
| [26] |
W. Chen, T. Y. Lei, D. C. Jin, H. Lin, K.-C. Chou, PseKNC: a flexible web server for generating pseudo K-tuple nucleotide composition, Anal. Biochem., 456 (2014), 53–60. http://doi.org/10.1016/j.ab.2014.04.001 doi: 10.1016/j.ab.2014.04.001
|
| [27] |
H. Lin, E. Z. Deng, H. Ding, W. Chen, K.-C. Chou, IPro54-PseKNC: a sequence-based predictor for identifying sigma-54 promoters in prokaryote with pseudo k-tuple nucleotide composition, Nucleic Acids Res., 42 (2014), 12961–12972. http://doi.org/10.1093/nar/gku1019 doi: 10.1093/nar/gku1019
|
| [28] |
W. Chen, P. M. Feng, H. Lin, K.-C. Chou, ISS-PseDNC: identifying splicing sites using pseudo dinucleotide composition, Biomed Res. Int., 2014 (2014), 623149. http://doi.org/10.1155/2014/623149 doi: 10.1155/2014/623149
|
| [29] |
J. Lu, R. T. Kerns, S. D. Peddada, P. R. Bushelet, Principal component analysis-based filtering improves detection for Affymetrix gene expression arrays, Nucleic Acids Res., 39 (2011), e86. http://doi.org/10.1093/nar/gkr241 doi: 10.1093/nar/gkr241
|
| [30] | T. Postelnicu, Probit analysis, In: International encyclopedia of statistical science, Berlin, Heidelberg: Springer, 2011, 1128–1131. http://doi.org/10.1007/978-3-642-04898-2_461 |
| [31] |
R. Bro, A. K. Smilde, Principal component analysis, Anal. Methods, 6 (2014), 2812–2831. http://doi.org/10.1039/c3ay41907j doi: 10.1039/c3ay41907j
|
| [32] |
G. P. Zhou, D. Chen, S. Liao, R.-B. Huang, Recent progresses in studying helix-helix interactions in proteins by incorporating the Wenxiang diagram into the NMR spectroscopy, Curr. Top. Med. Chem., 16 (2015), 581–590. http://doi.org/10.2174/1568026615666150819104617 doi: 10.2174/1568026615666150819104617
|
| [33] |
P. Geladi, H. Isaksson, L. Lindqvist, S. Wold, K. Esbensen, Principal component analysis of multivariate images, Chemom. Intell. Lab. Syst., 5 (1989), 209–220. http://doi.org/10.1016/0169-7439(89)80049-8 doi: 10.1016/0169-7439(89)80049-8
|
| [34] |
C. Goodall, Principal component analysis, Technometrics, 30 (1988), 351–352. http://doi.org/10.2307/1270093 doi: 10.2307/1270093
|
| [35] | X. Liu, P. He, W. Chen, J. Gao, Multi-task deep neural networks for natural language understanding, In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, 2019, 4487–4496. http://doi.org/10.18653/v1/p19-1441 |
| [36] | N. Tishby, N. Zaslavsky, Deep learning and the information bottleneck principle, In: 2015 IEEE Information Theory Workshop (ITW), Jerusalem, Israel, 2015, 1–5. http://doi.org/10.1109/ITW.2015.7133169 |
| [37] |
S. Khan, M. Khan, N. Iqbal, M. Li, D. M. Khan, Spark-based parallel deep neural network model for classification of large scale RNAs into piRNAs and non-piRNAs, IEEE Access, 8 (2020), 136978–136991. http://doi.org/10.1109/ACCESS.2020.3011508 doi: 10.1109/ACCESS.2020.3011508
|
| [38] |
R. M. Cichy, A. Khosla, D. Pantazis, A. Torralba, A. Oliva, Comparison of deep neural networks to spatio-temporal cortical dynamics of human visual object recognition reveals hierarchical correspondence, Sci. Rep., 6 (2016), 27755. http://doi.org/10.1038/srep27755 doi: 10.1038/srep27755
|
| [39] |
A. Majid, M. M. Khan, N. Iqbal, M. A. Jan, M. Khan, Salman, Application of parallel vector space model for large-scale DNA sequence analysis, J. Grid Comput., 17 (2019), 313–324. http://doi.org/10.1007/s10723-018-9451-5 doi: 10.1007/s10723-018-9451-5
|
| [40] |
T. Hussain, H. F. Maqbool, N. Iqbal, M. Khan, Salman, A. A. Dehghani-Sanij, Computational model for the recognition of lower limb movement using wearable gyroscope sensor, Int. J. Sens. Networks, 30 (2019), 35–45. http://doi.org/10.1504/IJSNET.2019.099230 doi: 10.1504/IJSNET.2019.099230
|
| [41] |
J. H. Miao, K. H. Miao, Cardiotocographic diagnosis of fetal health based on multiclass morphologic pattern predictions using deep learning classification, Int. J. Adv. Comput. Sci. Appl., 9 (2018), 1–11. http://doi.org/10.14569/IJACSA.2018.090501 doi: 10.14569/IJACSA.2018.090501
|
| [42] |
N. Inayat, M. Khan, N. Iqbal, S. Khan, M. Raza, D. M. Khan, et al., iEnhancer-DHF: identification of enhancers and their strengths using optimize deep neural network with multiple features extraction methods, IEEE Access, 9 (2021), 40783–40796. http://doi.org/10.1109/ACCESS.2021.3062291 doi: 10.1109/ACCESS.2021.3062291
|
| [43] |
F. Khan, M. Khan, N. Iqbal, S. Khan, D. M. Khan, A. Khan, et al., Prediction of recombination spots using novel hybrid feature extraction method via deep learning approach, Front. Genet., 11 (2020), 1052. http://doi.org/10.3389/fgene.2020.539227 doi: 10.3389/fgene.2020.539227
|
| [44] |
S. Khan, M. Khan, N. Iqbal, M. A. A. Rahman, M. K. A. Karim, Deep-piRNA: bi-layered prediction model for PIWI-interacting RNA using discriminative features, Comput. Mater. Con., 72 (2022), 2243–2258. http://doi.org/10.32604/cmc.2022.022901 doi: 10.32604/cmc.2022.022901
|
| [45] |
S. Khan, M. Khan, N. Iqbal, S. A. Khan, K.-C. Chou, Prediction of piRNAs and their function based on discriminative intelligent model using hybrid features into Chou's PseKNC, Chemom. Intell. Lab. Syst., 203 (2020), 104056. http://doi.org/10.1016/j.chemolab.2020.104056 doi: 10.1016/j.chemolab.2020.104056
|
| [46] |
S. Khan, M. Khan, N. Iqbal, T. Hussain, S. A. Khan, K.-C. Chou, A two-level computation model based on deep learning algorithm for identification of piRNA and their functions via Chou's 5-steps rule, Int. J. Pept. Res. Ther., 26 (2020), 795–809. http://doi.org/10.1007/s10989-019-09887-3 doi: 10.1007/s10989-019-09887-3
|
| [47] |
J. Ma, R. P. Sheridan, A. Liaw, G. E. Dahl, V. Svetnik, Deep neural nets as a method for quantitative structure-activity relationships, J. Chem. Inf. Model., 55 (2015), 263–274. http://doi.org/10.1021/ci500747n doi: 10.1021/ci500747n
|
| [48] |
M. K. K. Leung, H. Y. Xiong, L. J. Lee, B. J. Frey, Deep learning of the tissue-regulated splicing code, Bioinformatics, 30 (2014), i121–i129. http://doi.org/10.1093/bioinformatics/btu277 doi: 10.1093/bioinformatics/btu277
|
| [49] |
M. Helmstaedter, K. L. Briggman, S. C. Turaga, V. Jain, H. S. Seung, W. Denk, Connectomic reconstruction of the inner plexiform layer in the mouse retina, Nature, 500 (2013), 168–174. http://doi.org/10.1038/nature12346 doi: 10.1038/nature12346
|
| [50] |
G. Hinton, L. Deng, D. Yu, G. E. Dahl, A. Mohamed, N. Jaitly, et al., Deep neural networks for acoustic modeling in speech recognition: the shared views of four research groups, IEEE Signal Proc. Mag., 29 (2012), 82–97. http://doi.org/10.1109/MSP.2012.2205597 doi: 10.1109/MSP.2012.2205597
|
| [51] | T. N. Sainath, A. Mohamed, B. Kingsbury, B. Ramabhadran, Deep convolutional neural networks for LVCSR, In: 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 2013, 8614–8618. http://doi.org/10.1109/ICASSP.2013.6639347 |
| [52] |
A. Krizhevsky, I. Sutskever, G. E. Hinton, ImageNet classification with deep convolutional neural networks, Commun. ACM, 60 (2017), 84–90. http://doi.org/10.1145/3065386 doi: 10.1145/3065386
|
| [53] |
C. Farabet, C. Couprie, L. Najman, Y. LeCun, Learning hierarchical features for scene labeling, IEEE Trans. Pattern Anal. Mach. Intell., 35 (2013), 1915–1929. http://doi.org/10.1109/TPAMI.2012.231 doi: 10.1109/TPAMI.2012.231
|
| [54] |
U. R. Acharya, S. L. Oh, Y. Hagiwara, J. H. Tan, H. Adeli, Deep convolutional neural network for the automated detection and diagnosis of seizure using EEG signals, Comput. Biol. Med., 100 (2018), 270–278. http://doi.org/10.1016/j.compbiomed.2017.09.017 doi: 10.1016/j.compbiomed.2017.09.017
|
| [55] |
Z. Zhu, E. Albadawy, A. Saha, J. Zhang, M. R. Harowicz, M. A. Mazurowski, Deep learning for identifying radiogenomic associations in breast cancer, Comput. Biol. Med., 109 (2019), 85–90. http://doi.org/10.1016/j.compbiomed.2019.04.018 doi: 10.1016/j.compbiomed.2019.04.018
|
| [56] | T. Mikolov, S. Kombrink, L. Burget, J. Černocký, S. Khudanpur, Extensions of recurrent neural network language model, In: 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 2011, 5528–5531. http://doi.org/10.1109/ICASSP.2011.5947611 |
| [57] | A. Bordes, S. Chopra, J. Weston, Question answering with subgraph embeddings, In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Stroudsburg, PA, USA, Association for Computational Linguistics, 2014,615–620. http://doi.org/10.3115/v1/D14-1067 |
| [58] |
A. Baratloo, M. Hosseini, A. Negida, G. E. Ashal, Part 1: simple definition and calculation of accuracy, sensitivity and specificity, Emergency, 3 (2015), 48–49. http://doi.org/10.22037/emergency.v3i2.8154 doi: 10.22037/emergency.v3i2.8154
|
| [59] |
J. Chen, H. Liu, J. Yang, K.-C. Chou, Prediction of linear B-cell epitopes using amino acid pair antigenicity scale, Amino Acids, 33 (2007), 423–428. http://doi.org/10.1007/s00726-006-0485-9 doi: 10.1007/s00726-006-0485-9
|
| [60] |
Y. Guo, L. Yu, Z. Wen, M. Li, Using support vector machine combined with auto covariance to predict protein-protein interactions from protein sequences, Nucleic Acids Res., 36 (2008): 3025–3030. http://doi.org/10.1093/nar/gkn159 doi: 10.1093/nar/gkn159
|
| [61] |
M. F. Sabooh, N. Iqbal, M. Khan, M. Khan, H. F. Maqbool, Identifying 5-methylcytosine sites in RNA sequence using composite encoding feature into Chou's PseKNC, J. Theor. Biol., 452 (2018), 1–9. http://doi.org/10.1016/j.jtbi.2018.04.037 doi: 10.1016/j.jtbi.2018.04.037
|
| [62] |
P. M. Feng, W. Chen, H. Lin, K.-C. Chou, IHSP-PseRAAAC: identifying the heat shock protein families using pseudo reduced amino acid alphabet composition, Anal. Biochem., 442 (2013), 118–125. http://doi.org/10.1016/j.ab.2013.05.024 doi: 10.1016/j.ab.2013.05.024
|
| [63] |
Y. Xu, J. Ding, L.-Y. Wu, K.-C. Chou, iSNO-PseAAC: predict cysteine S-nitrosylation sites in proteins by incorporating position specific amino acid propensity into pseudo amino acid composition, PLoS One, 8 (2013), e55844. http://doi.org/10.1371/journal.pone.0055844 doi: 10.1371/journal.pone.0055844
|
| [64] |
W. Chen, P. M. Feng, H. Lin, K.-C. Chou, IRSpot-PseDNC: identify recombination spots with pseudo dinucleotide composition, Nucleic Acids Res., 41 (2013), e68. http://doi.org/10.1093/nar/gks1450 doi: 10.1093/nar/gks1450
|
| [65] |
B. Liu, F. Yang, K.-C. Chou, 2L-piRNA: a two-layer ensemble classifier for identifying Piwi-interacting RNAs and their function, Mol. Ther.-Nucl. Acids, 7 (2017), 267–277. http://doi.org/10.1016/j.omtn.2017.04.008 doi: 10.1016/j.omtn.2017.04.008
|
| [66] |
A. R. Hedar, M. Almaraashi, A. E. Abdel-Hakim, M. Abdulrahim, Hybrid machine learning for solar radiation prediction in reduced feature spaces, Energies, 14 (2021), 7970. https://doi.org/10.3390/en14237970 doi: 10.3390/en14237970
|




Figures(5) / Tables(3)

Salman khan, Muhammad Naeem, Muhammad Qiyas. Deep intelligent predictive model for the identification of diabetes[J]. AIMS Mathematics, 2023, 8(7): 16446-16462. doi: 10.3934/math.2023840







 DownLoad:
DownLoad: