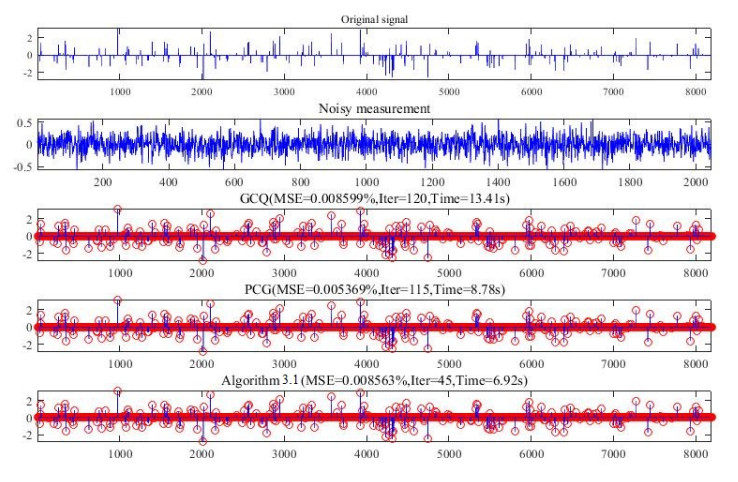
For sparse signal reconstruction (SSR) problem in compressive sensing (CS), by the splitting technique, we first transform it into a continuously differentiable convex optimization problem, and then a new self-adaptive gradient projection algorithm is proposed to solve the SSR problem, which has fast solving speed and pinpoint accuracy when the dimension increases. Global convergence of the proposed algorithm is established in detail. Without any assumptions, we establish global $ R- $linear convergence rate of the proposed algorithm, which is a new result for constrained convex (rather than strictly convex) quadratic programming problem. Furthermore, we can also obtain an approximate optimal solution in a finite number of iterations. Some numerical experiments are made on the sparse signal recovery and image restoration to exhibit the efficiency of the proposed algorithm. Compared with the state-of-the-art algorithms in SSR problem, the proposed algorithm is more accurate and efficient.
Citation: Hengdi Wang, Jiakang Du, Honglei Su, Hongchun Sun. A linearly convergent self-adaptive gradient projection algorithm for sparse signal reconstruction in compressive sensing[J]. AIMS Mathematics, 2023, 8(6): 14726-14746. doi: 10.3934/math.2023753
For sparse signal reconstruction (SSR) problem in compressive sensing (CS), by the splitting technique, we first transform it into a continuously differentiable convex optimization problem, and then a new self-adaptive gradient projection algorithm is proposed to solve the SSR problem, which has fast solving speed and pinpoint accuracy when the dimension increases. Global convergence of the proposed algorithm is established in detail. Without any assumptions, we establish global $ R- $linear convergence rate of the proposed algorithm, which is a new result for constrained convex (rather than strictly convex) quadratic programming problem. Furthermore, we can also obtain an approximate optimal solution in a finite number of iterations. Some numerical experiments are made on the sparse signal recovery and image restoration to exhibit the efficiency of the proposed algorithm. Compared with the state-of-the-art algorithms in SSR problem, the proposed algorithm is more accurate and efficient.

| [1] |
E. J. Candès, J. Romberg, T. Tao, Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information, IEEE T. Inform. Theory, 52 (2006), 489–509. https://doi.org/10.1109/TIT.2005.862083 doi: 10.1109/TIT.2005.862083

|
| [2] |
E. J. Candès, M. B. Wakin, An introduction to compressive sampling, IEEE Signal Proc. Mag., 25 (2008), 21–30. https://doi.org/10.1109/MSP.2007.914731 doi: 10.1109/MSP.2007.914731
|
| [3] |
D. L. Donoho, For most large underdetermined systems of equations, the minimal $\ell_1$-norm near-solution approximates the sparsest near-solution, Commun. Pur. Appl. Math., 59 (2006), 907–934. https://doi.org/10.1002/cpa.20131 doi: 10.1002/cpa.20131
|
| [4] |
B. K. Natarajan, Sparse approximate solutions to linear systems, SIAM J. Comput., 24 (1995), 227–234. https://doi.org/10.1137/S0097539792240406 doi: 10.1137/S0097539792240406
|
| [5] |
S. S. Chen, D. L. Donoho, M. A. Saunders, Automatic decomposition by basis pursuit, SIAM Rev., 43 (2001), 129–159. https://doi.org/10.1137/S003614450037906X doi: 10.1137/S003614450037906X
|
| [6] |
S. J. Kim, K. Koh, M. Lustig, S. Boyd, D. Gorinevsky, An interior-point method for large-scale $\ell_1$-regularized least squares, IEEE J-STSP, 1 (2007), 606–617. https://doi.org/10.1109/JSTSP.2007.910971 doi: 10.1109/JSTSP.2007.910971
|
| [7] |
M. A. T. Figueiredo, R. D. Nowak, S. J. Wright, Gradient projection for sparse reconstruction: Application to compressed sensing and other inverse problems, IEEE J-STSP, 1 (2007), 586–597. https://doi.org/10.1109/JSTSP.2007.910281 doi: 10.1109/JSTSP.2007.910281
|
| [8] |
Y. H. Dai, Y. K. Huang, X. W. Liu, A family of spectral gradient methods for optimization, Comput. Optim. Appl., 74 (2019), 43–65. https://doi.org/10.1007/s10589-019-00107-8 doi: 10.1007/s10589-019-00107-8
|
| [9] |
S. Huang, Z. Wan, A new nonmonotone spectral residual method for nonsmooth nonlinear equations, J. Comput. Appl. Math., 313 (2017), 82–101. https://doi.org/10.1016/j.cam.2016.09.014 doi: 10.1016/j.cam.2016.09.014
|
| [10] |
L. Zheng, L. Yang, Y. Liang, A conjugate gradient projection method for solving equations with convex constraints, J. Comput. Appl. Math., 375 (2020), 112781. https://doi.org/10.1016/j.cam.2020.112781 doi: 10.1016/j.cam.2020.112781
|
| [11] |
J. F. Yang, Y. Zhang, Alternating direction algorithms for $\ell_1-$problems in compressive sensing, SIAM J. Sci. Comput., 33 (2011), 250–278. https://doi.org/10.1137/090777761 doi: 10.1137/090777761
|
| [12] |
I. Daubechies, M. Defrise, C. D. Mol, An iterative thresholding algorithm for linear inverse problems with a sparsity constraint, Commun. Pur. Appl. Math., 57 (2004), 1413–1457. https://doi.org/10.1002/cpa.20042 doi: 10.1002/cpa.20042
|
| [13] |
M. A. T. Figueiredo, R. D. Nowak, An EM algorithm for wavelet-based image restoration, IEEE T. Image Process., 12 (2003), 906C916. https://doi.org/10.1109/TIP.2003.814255 doi: 10.1109/TIP.2003.814255
|
| [14] |
E. T. Hale, W. T. Yin, Y. Zhang, Fixed-point continuation for $\ell_1$-Minimization: Methodology and convergence, SIAM J. Optim., 19 (2008), 1107–1130. https://doi.org/10.1137/070698920 doi: 10.1137/070698920
|
| [15] |
A. Beck, M. Teboulle, A fast iterative shrinkage-thresholding algorithm for linear inverse problems, SIAM J. Imaging Sci., 2 (2009), 183–202. https://doi.org/10.1137/080716542 doi: 10.1137/080716542
|
| [16] |
J. M. Bioucas-Dias, M. A. T. Figueiredo, A new TwIst: Two-step iterative shrinkage/thresholding algorithm for image restoration, IEEE T. Image Process., 16 (2007), 2992–3004. https://doi.org/10.1109/TIP.2007.909319 doi: 10.1109/TIP.2007.909319
|
| [17] |
P. L. Combettes, J. C. Pesquet, Proximal thresholding algorithm for minimization over orthonormal bases, SIAM J. Optim., 18 (2007), 1351–1376. https://doi.org/10.1137/060669498 doi: 10.1137/060669498
|
| [18] |
E. van den Berg, M. P. Friedlander, Probing the Pareto frontier for basis pursuit solutions, SIAM J. Sci. Comput., 31 (2008), 890–912. https://doi.org/10.1137/080714488 doi: 10.1137/080714488
|
| [19] |
S. Becker, J. Bobin, E. J. Cands, NESTA: A fast and accurate first-order method for sparse recovery, SIAM J. Imaging Sci., 4 (2011), 1–39. https://doi.org/10.1137/090756855 doi: 10.1137/090756855
|
| [20] |
S. J. Wright, R. D. Nowak, M. A. T. Figueiredo, Sparse reconstruction by separable approximation, IEEE Trans. Signal Proces., 57 (2009), 2479–2493. https://doi.org/10.1109/TSP.2009.2016892 doi: 10.1109/TSP.2009.2016892
|
| [21] |
N. Keskar, J. Nocedal, F. Oztoprak, A. Waechter, A second-order method for convex $\ell_1$-regularized optimization with active-set prediction, Optim. Metod. Softw., 31 (2016), 605–621. https://doi.org/10.1080/10556788.2016.1138222 doi: 10.1080/10556788.2016.1138222
|
| [22] | X. T. Xiao, Y. F. Li, Z. W. Wen, L. W. Zhang, Semi-smooth second-order type methods for composite convex programs, arXiv: 1603.07870v2 [math.OC], 2016. https://doi.org/10.48550/arXiv.1603.07870 |
| [23] |
A. Milzarek, M. Ulbrich, A semismooth Newton method with multidimensional filter globalization for $l_1$-optimization, SIAM J. Optim., 24 (2014), 298–333. https://doi.org/10.1137/120892167 doi: 10.1137/120892167
|
| [24] |
R. H. Byrd, J. Nocedal, F. Oztoprak, An inexact successive quadratic approximation method for $L_1$ regularized optimization, Math. Program., 157 (2016), 375–396. https://doi.org/10.1007/s10107-015-0941-y doi: 10.1007/s10107-015-0941-y
|
| [25] |
Y. H. Xiao, H. Zhu, A conjugate gradient method to solve convex constrained monotone equations with applications in compressive sensing, J. Math. Anal. Appl., 405 (2013), 310–319. https://doi.org/10.1016/j.jmaa.2013.04.017 doi: 10.1016/j.jmaa.2013.04.017
|
| [26] |
M. Sun, M. Y. Tian, A class of derivative-free CG projection methods for nonsmooth equations with an application to the LASSO problem, B. Iran. Math. Soc., 46 (2020), 183–205. https://doi.org/10.1007/s41980-019-00250-2 doi: 10.1007/s41980-019-00250-2
|
| [27] |
H. C. Sun, M. Sun, B. H. Zhang, An inverse matrix-free proximal point algorithm for compressive sensing, ScienceAsia, 44 (2018), 311–318. https://doi.org/10.2306/scienceasia1513-1874.2018.44.311 doi: 10.2306/scienceasia1513-1874.2018.44.311
|
| [28] |
D. X. Feng, X. Y. Wang, A linearly convergent algorithm for sparse signal reconstruction, J. Fix. Point Theory Appl., 20 (2018), 154. https://doi.org/10.1007/s11784-018-0635-1 doi: 10.1007/s11784-018-0635-1
|
| [29] |
Y. H. Xiao, Q. Y. Wang, Q. J. Hu, Non-smooth equations based method for $\ell_1$-norm problems with applications to compressed sensing, Nonlinear Anal., 74 (2011), 3570–3577. https://doi.org/10.1016/j.na.2011.02.040 doi: 10.1016/j.na.2011.02.040
|
| [30] |
J. K. Liu, S. J. Li, A projection method for convex constrained monotone nonlinear equations with applications, Comput. Math. Appl., 70 (2015), 2442–2453. https://doi.org/10.1016/j.camwa.2015.09.014 doi: 10.1016/j.camwa.2015.09.014
|
| [31] |
J. K. Liu, Y. M. Feng, A derivative-free iterative method for nonlinear monotone equations with convex constraints, Numer. Algorithms, 82 (2019), 245–262. https://doi.org/10.1007/s11075-018-0603-2 doi: 10.1007/s11075-018-0603-2
|
| [32] |
Y. J. Wang, G. L. Zhou, L. Caccetta, W. Q. Liu, An alternative lagrange-dual based algorithm for sparse signal reconstruction, IEEE Trans. Signal Proces., 59 (2011), 1895–1901. https://doi.org/10.1109/TSP.2010.2103066 doi: 10.1109/TSP.2010.2103066
|
| [33] |
G. Landi, A modified Newton projection method for $\ell_1$-regularized least squares image deblurring, J. Math. Imaging Vis., 51 (2015), 195–208. https://doi.org/10.1007/s10851-014-0514-3 doi: 10.1007/s10851-014-0514-3
|
| [34] |
B. Xue, J. K. Du, H. C. Sun, Y. J. Wang, A linearly convergent proximal ADMM with new iterative format for BPDN in compressed sensing problem, AIMS Mathematics, 7 (2022), 10513–10533. https://doi.org/10.3934/math.2022586 doi: 10.3934/math.2022586
|
| [35] |
H. J. He, D. R. Han, A distributed Douglas-Rachford splitting method for multi-block convex minimization problems, Adv. Comput. Math., 42 (2016), 27–53. https://doi.org/10.1007/s10444-015-9408-1 doi: 10.1007/s10444-015-9408-1
|
| [36] |
M. Sun, J. Liu, A proximal Peaceman-Rachford splitting method for compressive sensing, J. Appl. Math. Comput., 50 (2016), 349–363. https://doi.org/10.1007/s12190-015-0874-x doi: 10.1007/s12190-015-0874-x
|
| [37] |
B. S. He, F. Ma, X. M. Yuan, Convergence study on the symmetric version of ADMM with larger step sizes, SIAM J. Imaging Sci., 9 (2016), 1467–1501. https://doi.org/10.1137/15M1044448 doi: 10.1137/15M1044448
|
| [38] |
H. J. He, C. Ling, H. K. Xu, An implementable splitting algorithm for the $\ell_1$-norm regularized split feasibility problem, J. Sci. Comput., 67 (2016), 281–298. https://doi.org/10.1007/s10915-015-0078-4 doi: 10.1007/s10915-015-0078-4
|
| [39] |
B. Qu, N. H. Xiu, A note on the CQ algorithm for the split feasibility problem, Inverse Probl., 21 (2005), 1655–1665. https://doi.org/10.1088/0266-5611/21/5/009 doi: 10.1088/0266-5611/21/5/009
|
| [40] | E. H. Zarantonello, Projections on convex sets in Hilbert space and spectral theory, In: Contributions to Nonlinear Functional Analysis, New York: Academic Press, 1971. https://doi.org/10.1016/B978-0-12-775850-3.50013-3 |
| [41] |
M. A. Noor, General variational inequalities, Appl. Math. Lett., 1 (1988), 119–121. https://doi.org/10.1016/0893-9659(88)90054-7 doi: 10.1016/0893-9659(88)90054-7
|
| [42] |
J. M. Ortega, W. C. Rheinboldt, Iterative solution of nonlinear equations in several variables, Classics Appl. Math., 2000. https://doi.org/10.1137/1.9780898719468 doi: 10.1137/1.9780898719468
|
| [43] |
N. H. Xiu, J. Z. Zhang, Global projection-type error bound for general variational inequalities, J. Optim. Theory Appl., 112 (2002), 213–228. https://doi.org/10.1023/a:1013056931761 doi: 10.1023/a:1013056931761
|
| [44] |
M. K. Riahi, I. A. Qattan, On the convergence rate of Fletcher-Reeves nonlinear conjugate gradient methods satisfying strong Wolfe conditions: Application to parameter identification in problems governed by general dynamics, Math. Method Appl. Sci., 45 (2022), 3644–3664. https://doi.org/10.1002/mma.8009 doi: 10.1002/mma.8009
|
| [45] |
M. K. Riahi, A new approach to improve ill-conditioned parabolic optimal control problem via time domain decomposition, Numer. Algorithms, 3 (2016), 635–666. https://doi.org/10.1007/s11075-015-0060-0 doi: 10.1007/s11075-015-0060-0
|
| [46] |
E. J. Cand$\grave{e}$s, Y. Plan, Tight oracle inequalities for low-rank matrix recovery from a minimal number of noisy random measurements, IEEE Trans. Inform. Theory, 57 (2011), 2342–2359. https://doi.org/10.1109/TIT.2011.2111771 doi: 10.1109/TIT.2011.2111771
|
| [47] |
W. D. Wang, F. Zhang, J. J. Wang, Low-rank matrix recovery via regularized nuclear norm minimization, Appl. Comput. Harmon. Anal., 54 (2021), 1–19. https://doi.org/10.1016/j.acha.2021.03.001 doi: 10.1016/j.acha.2021.03.001
|


Figures(3) / Tables(3)

Hengdi Wang, Jiakang Du, Honglei Su, Hongchun Sun. A linearly convergent self-adaptive gradient projection algorithm for sparse signal reconstruction in compressive sensing[J]. AIMS Mathematics, 2023, 8(6): 14726-14746. doi: 10.3934/math.2023753







 DownLoad:
DownLoad: