Hard Thresholding Pursuit (HTP) is one of the important and efficient algorithms for reconstructing sparse signals. Unfortunately, the hard thresholding operator is independent of the objective function and hence leads to numerical oscillation in the course of iterations. To alleviate this drawback, the hard thresholding operator should be applied to a compressible vector. Motivated by this idea, we propose a new algorithm called Compressive Hard Thresholding Pursuit (CHTP) by introducing a compressive step first to the standard HTP. Convergence analysis and stability of CHTP are established in terms of the restricted isometry property of a sensing matrix. Numerical experiments show that CHTP is competitive with other mainstream algorithms such as the HTP, Orthogonal Matching Pursuit (OMP) and Subspace Pursuit (SP) algorithms both in the sparse signal reconstruction ability and average recovery runtime.
Citation: Liping Geng, Jinchuan Zhou, Zhongfeng Sun, Jingyong Tang. Compressive hard thresholding pursuit algorithm for sparse signal recovery[J]. AIMS Mathematics, 2022, 7(9): 16811-16831. doi: 10.3934/math.2022923
Hard Thresholding Pursuit (HTP) is one of the important and efficient algorithms for reconstructing sparse signals. Unfortunately, the hard thresholding operator is independent of the objective function and hence leads to numerical oscillation in the course of iterations. To alleviate this drawback, the hard thresholding operator should be applied to a compressible vector. Motivated by this idea, we propose a new algorithm called Compressive Hard Thresholding Pursuit (CHTP) by introducing a compressive step first to the standard HTP. Convergence analysis and stability of CHTP are established in terms of the restricted isometry property of a sensing matrix. Numerical experiments show that CHTP is competitive with other mainstream algorithms such as the HTP, Orthogonal Matching Pursuit (OMP) and Subspace Pursuit (SP) algorithms both in the sparse signal reconstruction ability and average recovery runtime.

| [1] |
E. J. Candes, T. Tao, Decoding by linear programming, IEEE T. Inform. Theory, 51 (2005), 4203–4215. http://dx.doi.org/10.1109/TIT.2005.858979 doi: 10.1109/TIT.2005.858979

|
| [2] |
D. L. Donoho, Y. Tsaig, Fast solution of $l_1$-norm minimization problems when the solution may be sparse, IEEE T. Inform. Theory, 54 (2008), 4789–4812. http://dx.doi.org/10.1109/TIT.2008.929958 doi: 10.1109/TIT.2008.929958
|
| [3] |
H. Ge, W. Chen, M. K. Ng, New RIP Bounds for recovery of sparse signals with partial support information via weighted ${\ell_{p}}$-minimization, IEEE T. Inform. Theory, 66 (2020), 3914–3928. http://dx.doi.org/10.1109/TIT.2020.2966436 doi: 10.1109/TIT.2020.2966436
|
| [4] |
A. H. Wan, Uniform RIP conditions for recovery of sparse signals by $\ell_p$, $(0<p\leq 1)$ minimization, IEEE T. Signal Proces., 28 (2020), 5379–5394. http://dx.doi.org/10.1109/TSP.2020.3022822 doi: 10.1109/TSP.2020.3022822
|
| [5] |
H. Cai, J. F. Cai, T. Wang, G. Yin, Accelerated structured alternating projections for robust spectrally sparse signal recovery, IEEE T. Signal Proces., 69 (2021), 809–821. http://dx.doi.org/10.1109/TSP.2021.3049618 doi: 10.1109/TSP.2021.3049618
|
| [6] |
C. H. Lee, B. D. Rao, H. Garudadri, A sparse conjugate gradient adaptive filter, IEEE Signal Proc. Let., 27 (2020), 1000–1004. http://dx.doi.org/10.1109/LSP.2020.3000459 doi: 10.1109/LSP.2020.3000459
|
| [7] |
T. Cai, L. Wang, Orthogonal matching pursuit for sparse signal recovery with noise, IEEE T. Inform. Theory, 57 (2011), 4680–4688. http://dx.doi.org/10.1109/TIT.2011.2146090 doi: 10.1109/TIT.2011.2146090
|
| [8] |
J. A. Tropp, A. C. Gilbert, Signal recovery from random measurements via orthogonal matching pursuit, IEEE T. Inform. Theory, 53 (2007), 4655–4666. http://dx.doi.org/10.1109/TIT.2007.909108 doi: 10.1109/TIT.2007.909108
|
| [9] |
J. Wen, R. Zhang, W. Yu, Signal-dependent performance analysis of orthogonal matching pursuit for exact sparse recovery, IEEE T. Signal Proces., 68 (2020), 5031–5046. http://dx.doi.org/10.1109/TSP.2020.3016571 doi: 10.1109/TSP.2020.3016571
|
| [10] |
D. Needell, J. A. Tropp, CoSaMP: Iterative signal recovery from incomplete and inaccurate samples, Appl. Comput. Harmon. A., 26 (2009), 301–321. http://dx.doi.org/10.1145/1859204.1859229 doi: 10.1145/1859204.1859229
|
| [11] |
W. Dai, O. Milenkovic, Subspace pursuit for compressive sensing signal reconstruction, IEEE T. Infrom. Theory, 55 (2009), 2230–2249. http://dx.doi.org/10.1109/TIT.2009.2016006 doi: 10.1109/TIT.2009.2016006
|
| [12] |
N. Han, S. Li, J. Lu, Orthogonal subspace based fast iterative thresholding algorithms for joint sparsity recovery, IEEE Signal Proces. Let., 28 (2021), 1320–1324. http://dx.doi.org/10.1109/LSP.2021.3089434 doi: 10.1109/LSP.2021.3089434
|
| [13] |
T. Blumensath, M. E. Davies, Iterative hard thresholding for compressed sensing, Appl. Comput. Harmon. Anal., 27 (2009), 265–274. http://dx.doi.org/10.1016/j.acha.2009.04.002 doi: 10.1016/j.acha.2009.04.002
|
| [14] |
M. Fornasier, H. Rauhut, Iterative thresholding algorithms, Appl. Comput. Harmon. Anal., 25 (2008), 187–208. http://dx.doi.org/10.1016/j.acha.2007.10.005 doi: 10.1016/j.acha.2007.10.005
|
| [15] |
S. Foucart, G. Lecue, An IHT algorithm for sparse recovery from subexponential measurements, IEEE Signal Proces. Let., 24 (2017), 1280–1283. http://dx.doi.org/10.1109/LSP.2017.2721500 doi: 10.1109/LSP.2017.2721500
|
| [16] |
J. L. Bouchot, S. Foucart, P. Hitczenki, Hard thresholding pursuit algorithms: Number of iterations, Appl. Comput. Harmon. Anal., 41 (2016), 412–435. http://dx.doi.org/10.1016/j.acha.2016.03.002 doi: 10.1016/j.acha.2016.03.002
|
| [17] |
S. Foucart, Hard thresholding pursuit: An algorithm for compressive sensing, SIAM J. Numer. Anal., 49 (2011), 2543–2563. http://dx.doi.org/10.1137/100806278 doi: 10.1137/100806278
|
| [18] | X. T. Yuan, P. Li, T. Zhang, Gradient hard thresholding pursuit, J. Mach. Learn. Res., 18 (2018), 1–43. |
| [19] |
D. L. Donoho, De-noising by soft-thresholding, IEEE T. Inform. Theory, 41 (1995), 613–627. http://dx.doi.org/10.1109/18.382009 doi: 10.1109/18.382009
|
| [20] |
N. Meng, Y. B. Zhao, Newton-step-based hard thresholding algorithms for sparse signal recovery, IEEE T. Signal Proces., 68 (2020), 6594–6606. http://dx.doi.org/10.1109/TSP.2020.3037996 doi: 10.1109/TSP.2020.3037996
|
| [21] |
Y. B. Zhao, Optimal $k$-thresholding algorithms for sparse optimization problems, SIAM J. Optimiz., 30 (2020), 31–55. https://doi.org/10.1137/18M1219187 doi: 10.1137/18M1219187
|
| [22] |
Y. B. Zhao, Z. Q. Luo, Analysis of optimal thresholding algorithms for compressed sensing, IEEE T. Signal Proces., 187 (2021), 108–148. https://doi.org/10.1016/j.sigpro.2021.108148 doi: 10.1016/j.sigpro.2021.108148
|
| [23] | S. Foucart, H. Rauhut, A Mathematical Introduction to Compressive Sensing, Springer, NY, 2013. https://doi.org/10.1007/978-0-8176-4948-7 |
| [24] | J. L. Shen, S. Mousavi, Exact support and vector recovery of constrained sparse vectors via constrained matching pursuit, arXiv Preprint, 2020. Available from: https://arXiv.org/abs/1903.07236. |
| [25] | Y. B. Zhao, Sparse Optimization Theory and Methods, Boca Raton, FL, CRC Press, 2018. https://doi.org/10.1201/9781315113142 |
| [26] |
Y. B. Zhao, Z. Q. Luo, Constructing new weighted $l_1$ algorithms for the sparsest points of polyhedral sets, Math. Oper. Res., 42 (2016), 57–76. https://doi.org/10.1287/moor.2016.0791 doi: 10.1287/moor.2016.0791
|
| [27] | N. Meng, Y. B. Zhao, M. Kocvara, Partial gradient optimal thresholding algorithms for a class of sparse optimization problems, arXiv Preprint, 2022. https://arXiv.org/abs/2107.04319v2 |
| [28] | Y. B. Zhao, Z. Q. Luo, Improved RIP-based bounds for guaranteed performance of two compressed sensing algorithms, arXiv Preprint, 2020. https://arXiv.org/abs/2007.01451 |
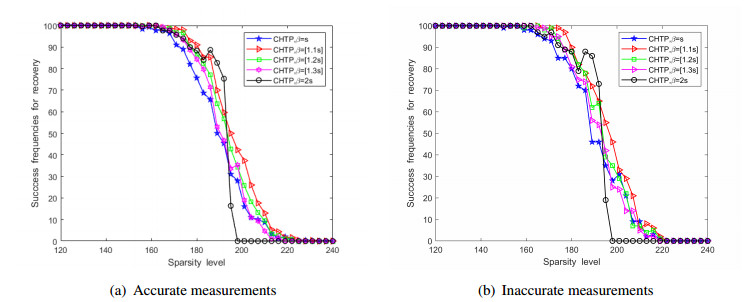

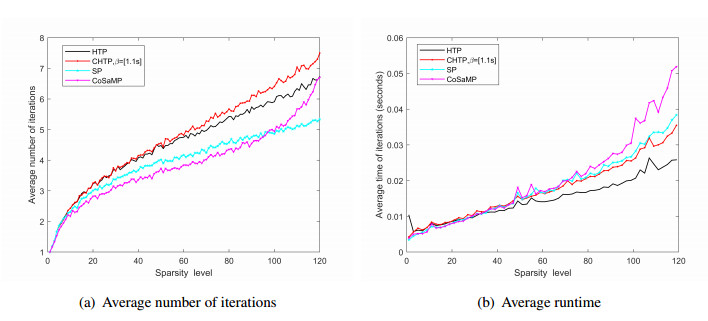
Figures(3)

Liping Geng, Jinchuan Zhou, Zhongfeng Sun, Jingyong Tang. Compressive hard thresholding pursuit algorithm for sparse signal recovery[J]. AIMS Mathematics, 2022, 7(9): 16811-16831. doi: 10.3934/math.2022923







 DownLoad:
DownLoad: