Convolution is a very basic and important operation for convolutional neural networks. For neural network training, how to bound the convolutional layers is a currently popular research topic. Each convolutional layer is represented by a tensor, which corresponds to a structured transformation matrix. The objective is to ensure that the singular values of each transformation matrix are bounded around 1 by changing the entries of the tensor. We propose three new regularization terms for a convolutional kernel tensor and derive the gradient descent algorithm for each penalty function. Numerical examples are presented to demonstrate the effectiveness of the algorithms.
Citation: Pei-Chang Guo. New regularization methods for convolutional kernel tensors[J]. AIMS Mathematics, 2023, 8(11): 26188-26198. doi: 10.3934/math.20231335
Convolution is a very basic and important operation for convolutional neural networks. For neural network training, how to bound the convolutional layers is a currently popular research topic. Each convolutional layer is represented by a tensor, which corresponds to a structured transformation matrix. The objective is to ensure that the singular values of each transformation matrix are bounded around 1 by changing the entries of the tensor. We propose three new regularization terms for a convolutional kernel tensor and derive the gradient descent algorithm for each penalty function. Numerical examples are presented to demonstrate the effectiveness of the algorithms.

| [1] | P. L. Bartlett, D. J. Foster, M. Telgarsky, Spectrally-normalized margin bounds for neural networks, Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017, 6241–6250. |
| [2] |
A. Brock, T. Lim, J. M. Ritchie, N. Weston, Neural photo editing with introspective adversarial networks, arXiv, 2017. https://doi.org/10.48550/arXiv.1609.07093 doi: 10.48550/arXiv.1609.07093

|
| [3] | R. H. F. Chan, X. Jin, An introduction to iterative toeplitz solvers, SIAM Press, 2007. |
| [4] | M. Cisse, P. Bojanowski, E. Grave, Y. Dauphin, N. Usunier, Parseval networks: improving robustness to adversarial examples, Proceedings of the 34th International Conference on Machine Learning, 70 (2017), 854–863. |
| [5] | W. Ding, Y. Wei, Theory and computation of tensors: multi-dimensional arrays, Academic Press, 2016. https://doi.org/10.1016/C2014-0-04764-8 |
| [6] |
V. Dumoulin, F. Visin, A guide to convolution arithmetic for deep learning, arXiv, 2018. https://doi.org/10.48550/arXiv.1603.07285 doi: 10.48550/arXiv.1603.07285
|
| [7] | G. H. Golub, C. F. Van Loan, Matrix computations, Johns Hopkins University Press, 2013. https://doi.org/10.56021/9781421407944 |
| [8] | I. J. Goodfellow, Y. Bengio, A. Courville, Deep learning, MIT Press, 2016. |
| [9] |
I. J. Goodfellow, J. Shlens, C. Szegedy, Explaining and harnessing adversarial examples, arXiv, 2015. https://doi.org/10.48550/arXiv.1412.6572 doi: 10.48550/arXiv.1412.6572
|
| [10] |
P. C. Guo, Q. Ye, On the regularization of convolutional kernels in neural networks, Linear Multilinear Algebra, 70 (2022), 2318–2330. https://doi.org/10.1080/03081087.2020.1795058 doi: 10.1080/03081087.2020.1795058
|
| [11] | J. F. Kolen, S. C. Kremer, Gradient flow in recurrent nets: the difficulty of learning long-term dependencies, Wiley-IEEE Press, 2001. https://doi.org/10.1109/9780470544037.ch14 |
| [12] | X. Q. Jin, Developments and applications of block Toeplitz iterative solvers, Springer Science & Business Media, 2003. |
| [13] | J. Kovačević, A. Chebira, An introduction to frames, Now Publishers Inc., 2008. |
| [14] |
P. Li, Y. Lu, C. Xu, J. Ren, Insight into Hopf bifurcation and control methods in fractional order BAM neural networks incorporating symmetric structure and delay, Cognit. Comput., 2023. https://doi.org/10.1007/s12559-023-10155-2 doi: 10.1007/s12559-023-10155-2
|
| [15] |
L. H. Lim, Tensors in computations, Acta Numer., 30 (2021), 555–764. https://doi.org/10.1017/S0962492921000076 doi: 10.1017/S0962492921000076
|
| [16] |
T. Miyato, T. Kataoka, M. Koyama, Y. Yoshida, Spectral normalization for generative adversarial networks, arXiv, 2018. https://doi.org/10.48550/arXiv.1802.05957 doi: 10.48550/arXiv.1802.05957
|
| [17] |
H. Sedghi, V. Gupta, P. M. Long, The singular values of convolutional layers, arXiv, 2018. https://doi.org/10.48550/arXiv.1805.10408 doi: 10.48550/arXiv.1805.10408
|
| [18] | G. W. Stewart. Matrix algorithms, SIAM Publications Library, 2001. https://doi.org/10.1137/1.9780898718058 |
| [19] |
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. J. Goodfellow, et al., Intriguing properties of neural networks, arXiv, 2013. https://doi.org/10.48550/arXiv.1312.6199 doi: 10.48550/arXiv.1312.6199
|
| [20] | Y. Tsuzuku, I. Sato, M. Sugiyama, Lipschitz-Margin training: scalable certification of perturbation invariance for deep neural networks, Adv. Neural Inf. Process., 31 (2018), 6542–6551. |
| [21] |
J. Wang, Y. Chen, R. Chakraborty, S. X. Yu, Orthogonal convolutional neural networks, 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020. https://doi.org/10.1109/CVPR42600.2020.01152 doi: 10.1109/CVPR42600.2020.01152
|
| [22] |
C. Xu, Z. Liu, P. Li, J. Yan, L. Yao, Bifurcation mechanism for fractional-order three-triangle multi-delayed neural networks, Neural Process. Lett., 2022. https://doi.org/10.1007/s11063-022-11130-y doi: 10.1007/s11063-022-11130-y
|
| [23] |
C. Xu, W. Zhang, Z. Liu, L. Yao, Delay-induced periodic oscillation for fractional-order neural networks with mixed delays, Neurocomputing, 488 (2022), 681–693. https://doi.org/10.1016/j.neucom.2021.11.079 doi: 10.1016/j.neucom.2021.11.079
|
| [24] |
Y. Yoshida, T. Miyato, Spectral norm regularization for improving the generalizability of deep learning, arXiv, 2017. https://doi.org/10.48550/arXiv.1705.10941 doi: 10.48550/arXiv.1705.10941
|
| [25] |
C. Zhang, S. Bengio, M. Hardt, B. Recht, O. Vinyals, Understanding deep learning (still) requires rethinking generalization, Commun. ACM, 64 (2021), 107–115. https://doi.org/10.1145/3446776 doi: 10.1145/3446776
|
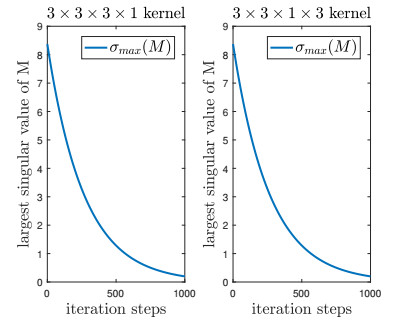


Figures(3)

Pei-Chang Guo. New regularization methods for convolutional kernel tensors[J]. AIMS Mathematics, 2023, 8(11): 26188-26198. doi: 10.3934/math.20231335







 DownLoad:
DownLoad: