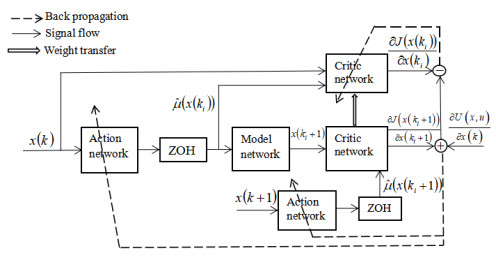
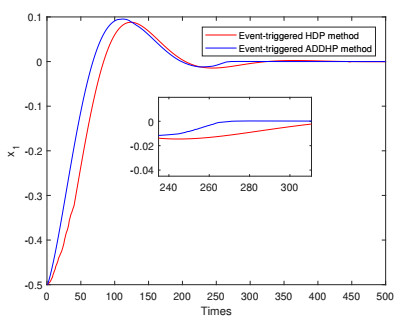
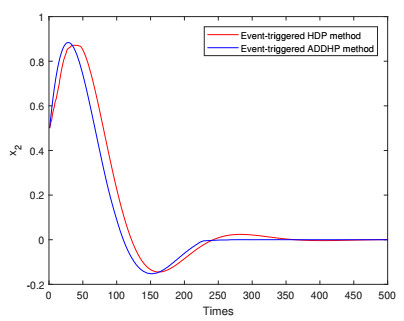
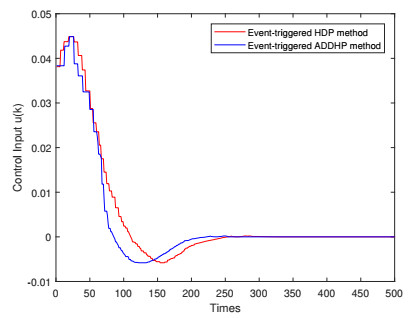
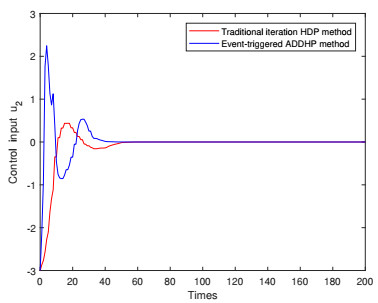
In this paper, a novel event-triggered optimal control method is developed for nonlinear discrete-time systems with constrained inputs. First, a non-quadratic utility function is constructed to overcome the challenge caused by saturating actuators. Second, a novel triggering condition is designed to reduce computational burden. Difference from other triggering conditions, fewer assumptions are required to guarantee asymptotic stability. Then, the optimal cost function and control law are obtained by constructing the action-critic network. Convergence analysis of the system is provided in the consideration of the system state and neural network weight estimation errors. Finally, the effectiveness and correctness of the proposed method are verified by two numerical examples.
Citation: Yuanyuan Cheng, Yuan Li. A novel event-triggered constrained control for nonlinear discrete-time systems[J]. AIMS Mathematics, 2023, 8(9): 20530-20545. doi: 10.3934/math.20231046
In this paper, a novel event-triggered optimal control method is developed for nonlinear discrete-time systems with constrained inputs. First, a non-quadratic utility function is constructed to overcome the challenge caused by saturating actuators. Second, a novel triggering condition is designed to reduce computational burden. Difference from other triggering conditions, fewer assumptions are required to guarantee asymptotic stability. Then, the optimal cost function and control law are obtained by constructing the action-critic network. Convergence analysis of the system is provided in the consideration of the system state and neural network weight estimation errors. Finally, the effectiveness and correctness of the proposed method are verified by two numerical examples.

| [1] |
D. Liu, S. Xue, B. Zhao, B. Luo, Q. Wei, Adaptive dynamic programming for control: a survey and recent advances, IEEE T. Syst. Man Cy., 51 (2021), 142–160. https://doi.org/10.1109/TSMC.2020.3042876 doi: 10.1109/TSMC.2020.3042876

|
| [2] |
Y. Zhang, B. Zhao, D. Liu, Deterministic policy gradient adaptive dynamic programming for model-free optimal control, Neurocomputing, 387 (2020), 40–50. https://doi.org/10.1016/j.neucom.2019.11.032 doi: 10.1016/j.neucom.2019.11.032
|
| [3] | M. Ha, D. Wang, D. Liu, A novel value iteration scheme with adjustable convergence rate, IEEE T. Neur. Net. Lear., in press. https://doi.org/10.1109/TNNLS.2022.3143527 |
| [4] |
C. Mu, D. Wang, H. He, Novel iterative neural dynamic programming for data-based approximate optimal control design, Automatica, 81 (2017), 240–252. https://doi.org/10.1016/j.automatica.2017.03.022 doi: 10.1016/j.automatica.2017.03.022
|
| [5] |
L. Dong, X. Zhong, C. Sun, H. He, Adaptive event-triggered control based on heuristic dynamic programming for nonlinear discrete-time systems, IEEE T. Neur. Net. Lear., 28 (2017), 1594–1605. https://doi.org/10.1109/TNNLS.2016.2541020 doi: 10.1109/TNNLS.2016.2541020
|
| [6] |
T. Li, D. Yang, X. Xie, H. Zhang, Event-triggered control of nonlinear discrete-time system with unknown dynamics based on HDP ($\lambda$), IEEE T. Cybernetics, 52 (2021), 6046–6058. https://doi.org/10.1109/TCYB.2020.3044595 doi: 10.1109/TCYB.2020.3044595
|
| [7] |
J. Lu, Q. Wei, T. Zhou, Z. Wang, F. Wang, Event-triggered near-optimal control for unknown discrete-time nonlinear systems using parallel control, IEEE T. Cybernetics, 53 (2023), 1890–1904. https://doi.org/10.1109/TCYB.2022.3164977 doi: 10.1109/TCYB.2022.3164977
|
| [8] |
J. Wang, Y. Wang, Z. Ji, Model-free event-triggered optimal control with performance guarantees via goal representation heuristic dynamic programming, Nonlinear Dyn., 108 (2022), 3711–3726. https://doi.org/10.1007/s11071-022-07438-y doi: 10.1007/s11071-022-07438-y
|
| [9] | Z. Wang, J. Lee, X. Sun, Y. Chai, Y. Liu, Self-learning optimal control with performance analysis using event-triggered adaptive dynamic programming, Proceedings of 5th International Conference on Crowd Science and Engineering, 2021, 29–34. https://doi.org/10.1145/3503181.3503187 |
| [10] |
S. Xue, B. Luo, D. Liu, Y. Gao, Event-triggered ADP for tracking control of partially unknown constrained uncertain systems, IEEE T. Cybernetics, 52 (2022), 9001–9012. https://doi.org/10.1109/TCYB.2021.3054626 doi: 10.1109/TCYB.2021.3054626
|
| [11] |
D. Wang, M. Zhao, M. Ha, J. Ren, Neural optimal tracking control of constrained nonaffine systems with a wastewater treatment application, Neural Networks, 143 (2021), 121–132. https://doi.org/10.1016/j.neunet.2021.05.027 doi: 10.1016/j.neunet.2021.05.027
|
| [12] |
J. Lu, Q. Wei, Y. Liu, T. Zhou, F. Wang, Event-triggered optimal parallel tracking control for discrete-time nonlinear systems, IEEE T. Syst. Man Cy., 52 (2022), 3772–3784. https://doi.org/10.1109/TSMC.2021.3073429 doi: 10.1109/TSMC.2021.3073429
|
| [13] |
K. Wang, Q. Gu, B. Huang, Q. Wei, T. Zhou, Adaptive event-triggered near-optimal tracking control for unknown continuous-time nonlinear systems, IEEE Access, 10 (2022), 9506–9518. https://doi.org/10.1109/ACCESS.2021.3140076 doi: 10.1109/ACCESS.2021.3140076
|
| [14] |
Q. Wei, J. Lu, T. Zhou, X. Cheng, F. Wang, Event-triggered near-optimal control of discrete-time constrained nonlinear systems with application to a boiler-turbine system, IEEE T. Ind. Inform., 18 (2022), 3926–3935. https://doi.org/10.1109/TII.2021.3116084 doi: 10.1109/TII.2021.3116084
|
| [15] | D. Wang, L. Hu, M. Zhao, J. Qiao, Adaptive critic for event-triggered unknown nonlinear optimal tracking design with wastewater treatment applications, IEEE T. Neur. Net. Lear., in press. https://doi.org/10.1109/TNNLS.2021.3135405 |
| [16] |
B. Sun, E. van Kampen, Event-triggered constrained control using explainable global dual heuristic programming for nonlinear discrete-time systems, Neurocomputing, 468 (2022), 452–463. https://doi.org/10.1016/j.neucom.2021.10.046 doi: 10.1016/j.neucom.2021.10.046
|
| [17] |
S. Xue, B. Luo, D. Liu, Y. Li, Adaptive dynamic programming based event-triggered control for unknown continuous-time nonlinear systems with input constraints, Neurocomputing, 396 (2020), 191–200. https://doi.org/10.1016/j.neucom.2018.09.097 doi: 10.1016/j.neucom.2018.09.097
|
| [18] |
S. Zhang, B. Zhao, Y. Zhang, Event-triggered control for input constrained non-affine nonlinear systems based on neuro-dynamic programming, Neurocomputing, 440 (2021), 175–184. https://doi.org/10.1016/j.neucom.2021.01.116 doi: 10.1016/j.neucom.2021.01.116
|
| [19] |
X. Yang, Q. Wei, Adaptive critic learning for constrained optimal event-triggered control with discounted cost, IEEE T. Neur. Net. Lear., 32 (2021), 91–104. https://doi.org/10.1109/TNNLS.2020.2976787 doi: 10.1109/TNNLS.2020.2976787
|
| [20] |
M. Ha, D. Wang, D. Liu, Event-triggered adaptive critic control design for discrete-time constrained nonlinear systems, IEEE T. Syst. Man Cy., 50 (2020), 3158–3168. https://doi.org/10.1109/TSMC.2018.2868510 doi: 10.1109/TSMC.2018.2868510
|
| [21] | M. Ha, D. Wang, D. Liu, B. Zhao, Adaptive event-based control for discrete-time nonaffine systems with constrained inputs, Proceedings of Eighth International Conference on Information Science and Technology (ICIST), 2018,104–109. https://doi.org/10.1109/ICIST.2018.8426093 |
| [22] |
B. Luo, Y. Yang, D. Liu, H. Wu, Event-triggered optimal control with performance guarantees using adaptive dynamic programming, IEEE T. Neur. Net. Lear., 31 (2020), 76–88. https://doi.org/10.1109/TNNLS.2019.2899594 doi: 10.1109/TNNLS.2019.2899594
|
| [23] |
Z. Wang, Q. Wei, D. Liu, A novel triggering condition of event-triggered control based on heuristic dynamic programming for discrete-time systems, Optim. Contr. Appl. Meth., 39 (2018), 1467–1478. https://doi.org/10.1002/oca.2421 doi: 10.1002/oca.2421
|
| [24] |
C. Mu, K. Liao, K. Wang, Event-triggered design for discrete-time nonlinear systems with control constraints, Nonlinear Dyn., 103 (2021), 2645–2657. https://doi.org/10.1007/s11071-021-06218-4 doi: 10.1007/s11071-021-06218-4
|
| [25] |
M. Ha, D. Wang, D. Liu, Event-triggered constrained control with dhp implementation for nonaffine discrete-time systems, Inform. Sciences, 519 (2020), 110–123. https://doi.org/10.1016/j.ins.2020.01.020 doi: 10.1016/j.ins.2020.01.020
|
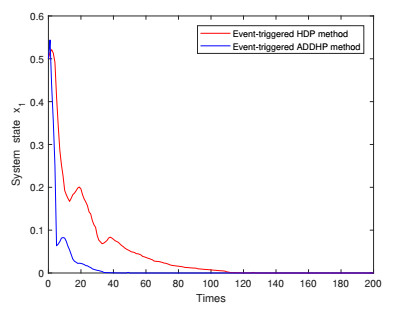
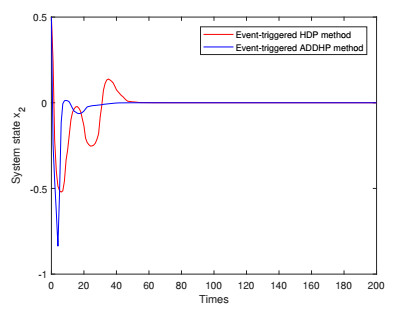
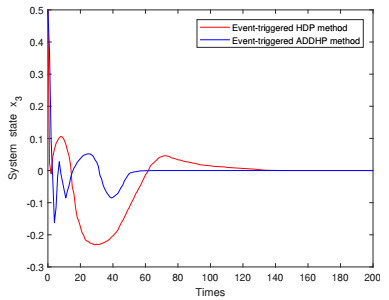
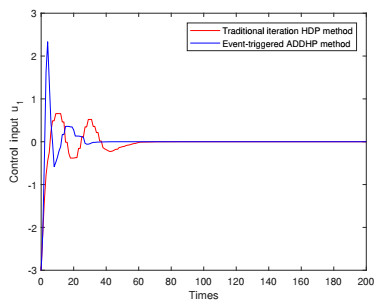
Figures(9)

Yuanyuan Cheng, Yuan Li. A novel event-triggered constrained control for nonlinear discrete-time systems[J]. AIMS Mathematics, 2023, 8(9): 20530-20545. doi: 10.3934/math.20231046







 DownLoad:
DownLoad: