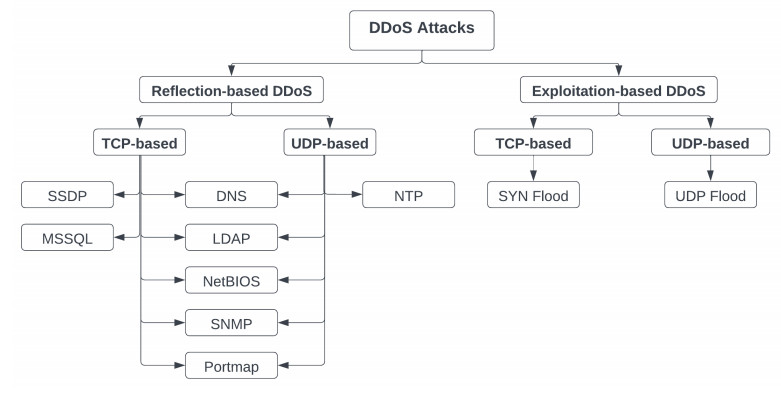
An amplified reflection and exploitation-based distributed denial of service (DDoS) attack allows an attacker to launch a volumetric attack on the target server or network. These attacks exploit network protocols to generate amplified service responses through spoofed requests. Spoofing the source addresses allows attackers to redirect all of the service responses to the victim's device, overwhelming it and rendering it unresponsive to legitimate users. Mitigating amplified reflection and exploitation attacks requires robust defense mechanisms that are capable of promptly identifying and countering the attack traffic while maintaining the availability and integrity of the targeted systems. This paper presents a collaborative prediction approach based on machine learning to mitigate amplified reflection and exploitation attacks. The proposed approach introduces a novel feature selection technique called closeness index of features (CIF) calculation, which filters out less important features and ranks them to identify reduced feature sets. Further, by combining different machine learning classifiers, a voting-based collaborative prediction approach is employed to predict network traffic accurately. To evaluate the proposed technique's effectiveness, experiments were conducted on CICDDoS2019 datasets. The results showed impressive performance, achieving an average accuracy, precision, recall and F1 score of 99.99%, 99.65%, 99.28% and 99.46%, respectively. Furthermore, evaluations were conducted by using AUC-ROC curve analysis and the Matthews correlation coefficient (MCC) statistical rate to analyze the approach's effectiveness on class imbalance datasets. The findings demonstrated that the proposed approach outperforms recent approaches in terms of performance. Overall, the proposed approach presents a robust machine learning-based solution to defend against amplified reflection and exploitation attacks, showcasing significant improvements in prediction accuracy and effectiveness compared to existing approaches.
Citation: Arvind Prasad, Shalini Chandra, Ibrahim Atoum, Naved Ahmad, Yazeed Alqahhas. A collaborative prediction approach to defend against amplified reflection and exploitation attacks[J]. Electronic Research Archive, 2023, 31(10): 6045-6070. doi: 10.3934/era.2023308
An amplified reflection and exploitation-based distributed denial of service (DDoS) attack allows an attacker to launch a volumetric attack on the target server or network. These attacks exploit network protocols to generate amplified service responses through spoofed requests. Spoofing the source addresses allows attackers to redirect all of the service responses to the victim's device, overwhelming it and rendering it unresponsive to legitimate users. Mitigating amplified reflection and exploitation attacks requires robust defense mechanisms that are capable of promptly identifying and countering the attack traffic while maintaining the availability and integrity of the targeted systems. This paper presents a collaborative prediction approach based on machine learning to mitigate amplified reflection and exploitation attacks. The proposed approach introduces a novel feature selection technique called closeness index of features (CIF) calculation, which filters out less important features and ranks them to identify reduced feature sets. Further, by combining different machine learning classifiers, a voting-based collaborative prediction approach is employed to predict network traffic accurately. To evaluate the proposed technique's effectiveness, experiments were conducted on CICDDoS2019 datasets. The results showed impressive performance, achieving an average accuracy, precision, recall and F1 score of 99.99%, 99.65%, 99.28% and 99.46%, respectively. Furthermore, evaluations were conducted by using AUC-ROC curve analysis and the Matthews correlation coefficient (MCC) statistical rate to analyze the approach's effectiveness on class imbalance datasets. The findings demonstrated that the proposed approach outperforms recent approaches in terms of performance. Overall, the proposed approach presents a robust machine learning-based solution to defend against amplified reflection and exploitation attacks, showcasing significant improvements in prediction accuracy and effectiveness compared to existing approaches.

| [1] |
Y. Jia, F. Zhong, A. Alrawais, B. Gong, X. Cheng, FlowGuard: An intelligent edge defense mechanism against IoT DDoS attacks, IEEE Internet Things J., 7 (2020), 9552–9562. https://doi.org/10.1109/JIOT.2020.2993782 doi: 10.1109/JIOT.2020.2993782

|
| [2] |
A. Prasad, S. Chandra, Machine learning to combat cyberattack: a survey of datasets and challenges, J. Def. Model. Simul. Appl. Methodol. Technol., 2022 (2022). https://doi.org/10.1177/15485129221094881 doi: 10.1177/15485129221094881
|
| [3] |
H. Wang, H. He, W. Zhang, W. Liu, P. Liu, A. Javadpour, Using honeypots to model botnet attacks on the internet of medical things, Comput. Electr. Eng., 102 (2022), 108212. https://doi.org/10.1016/j.compeleceng.2022.108212 doi: 10.1016/j.compeleceng.2022.108212
|
| [4] |
Y. Lee, H. Chae, K. Lee, Countermeasures against large-scale reflection DDoS attacks using exploit IoT devices, Automatika, 62 (2021), 127–136. https://doi.org/10.1080/00051144.2021.1885587 doi: 10.1080/00051144.2021.1885587
|
| [5] |
M. Anagnostopoulos, S. Lagos, G. Kambourakis, Large-scale empirical evaluation of DNS and SSDP amplification attacks, J. Inf. Secur. Appl., 66 (2022), 103168. https://doi.org/10.1016/j.jisa.2022.103168 doi: 10.1016/j.jisa.2022.103168
|
| [6] |
K. B. Dasari, N. Devarakonda, Detection of different DDoS attacks using machine learning classification algorithms, Ing. Des Syst. d Inf., 26 (2021), 461–468. https://doi.org/10.18280/isi.260505 doi: 10.18280/isi.260505
|
| [7] | C. Rossow, Amplification hell: Revisiting network protocols for DDoS abuse, inNDSS, (2021), 1–15. |
| [8] | J. D. Case, M. Fedor, M. L. Schoffstall, J. Davin, Simple network management protocol (SNMP), 1989. |
| [9] |
D. Kshirsagar, S. Sawant, A. Rathod, S. Wathore, CPU load analysis & minimization for TCP SYN flood detection, Procedia Comput. Sci., 85 (2016), 626–633. https://doi.org/10.1016/j.procs.2016.05.230 doi: 10.1016/j.procs.2016.05.230
|
| [10] | S. Muthurajkumar, A. Geetha, S. Aravind, H. Barakath Meharajnisa, UDP flooding attack detection using entropy in software-defined networking, in Proceedings of International Conference on Communication and Computational Technologies, Springer, (2023), 549–560. https://doi.org/10.1007/978-981-19-3951-8_42 |
| [11] |
N. N. Mohamed, Y. Mohd Yussoff, M. A. Mat Isa, H. Hashim, Extending hybrid approach to secure Trivial File Transfer Protocol in M2M communication: a comparative analysis, Telecommun. Syst., 70 (2019), 511–523. https://doi.org/10.1007/s11235-018-0522-5 doi: 10.1007/s11235-018-0522-5
|
| [12] |
H. Aydın, Z. Orman, M. A. Aydın, A long short-term memory (LSTM)-based distributed denial of service (DDoS) detection and defense system design in public cloud network environment, Comput. Secur., 118 (2022), 102725. https://doi.org/10.1016/j.cose.2022.102725 doi: 10.1016/j.cose.2022.102725
|
| [13] |
S. Pundir, M. S. Obaidat, M. Wazid, A. K. Das, D. P. Singh, J. Rodrigues, MADP-IIME: malware attack detection protocol in IoT-enabled industrial multimedia environment using machine learning approach, Multimedia Syst., 29 (2023), 1785–1797. https://doi.org/10.1007/s00530-020-00743-9 doi: 10.1007/s00530-020-00743-9
|
| [14] |
M. Gallagher, N. Pitropakis, C. Chrysoulas, P. Papadopoulos, A. Mylonas, S. Katsikas, Investigating machine learning attacks on financial time series models, Comput. Secur., 123 (2022), 102933. https://doi.org/10.1016/j.cose.2022.102933 doi: 10.1016/j.cose.2022.102933
|
| [15] |
A. Prasad, S. Chandra, VMFCVD: An optimized framework to combat volumetric DDoS attacks using machine learning, Arabian J. Sci. Eng., 47 (2022), 9965–9983. https://doi.org/10.1007/s13369-021-06484-9 doi: 10.1007/s13369-021-06484-9
|
| [16] |
C. S. Kalutharage, X. Liu, C. Chrysoulas, N. Pitropakis, P. Papadopoulos, Explainable AI-based DDOS attack identification method for IoT networks, Computers, 12 (2023), 32. https://doi.org/10.3390/computers12020032 doi: 10.3390/computers12020032
|
| [17] |
A. Prasad, S. Chandra, BotDefender: A collaborative defense framework against botnet attacks using network traffic analysis and machine learning, Arabian J. Sci. Eng., (2023). https://doi.org/10.1007/s13369-023-08016-z doi: 10.1007/s13369-023-08016-z
|
| [18] |
M. Bhattacharya, S. Roy, A. K. Das, S. Chattopadhyay, S. Banerjee, A. Mitra, DDoS attack resisting authentication protocol for mobile based online social network applications, J. Inf. Secur. Appl., 65 (2022), 103115. https://doi.org/10.1016/j.jisa.2022.103115 doi: 10.1016/j.jisa.2022.103115
|
| [19] |
O. Thorat, N. Parekh, R. Mangrulkar, TaxoDaCmachine learning: Taxonomy based Divide and Conquer using machine learning approach for DDoS attack classification, Int. J. Inf. Manage. Data Insights, 1 (2021), 100048. https://doi.org/10.1016/j.jjimei.2021.100048 doi: 10.1016/j.jjimei.2021.100048
|
| [20] | M. E. Ahmed, H. Kim, M. Park, Mitigating DNS query-based DDoS attacks with machine learning on software-defined networking, in IEEE Military Communications Conference (MILCOM), (2017), 11–16. https://doi.org/10.1109/MILCOM.2017.8170802 |
| [21] |
I. Sreeram, V. P. K. Vuppala, HTTP flood attack detection in application layer using machine learning metrics and bio inspired bat algorithm, Appl. Comput. Inf., 15 (2019), 59–66. https://doi.org/10.1016/j.aci.2017.10.003 doi: 10.1016/j.aci.2017.10.003
|
| [22] |
O. Salman, I. H. Elhajj, A. Chehab, A. Kayssi, A machine learning based framework for IoT device identification and abnormal traffic detection, Trans. Emerging Telecommun. Technol., 33 (2022). https://doi.org/10.1002/ett.3743 doi: 10.1002/ett.3743
|
| [23] |
X. Liu, L. Zheng, S. Helal, W. Zhang, C. Jia, J. Zhou, A broad learning-based comprehensive defence against SSDP reflection attacks in IoTs, Digital Commun. Networks, 2022 (2022). https://doi.org/10.1016/j.dcan.2022.02.008 doi: 10.1016/j.dcan.2022.02.008
|
| [24] |
S. Ismail, Z. El Mrabet, H. Reza, An ensemble-based machine learning approach for cyber-attacks detection in wireless sensor networks, Appl. Sci., 13 (2022), 30. https://doi.org/10.3390/app13010030 doi: 10.3390/app13010030
|
| [25] |
D. Kshirsagar, S. Kumar, A feature reduction based reflected and exploited DDoS attacks detection system, J. Ambient Intell. Hum. Comput., 13 (2022), 393–405. https://doi.org/10.1007/s12652-021-02907-5 doi: 10.1007/s12652-021-02907-5
|
| [26] |
A. Mishra, N. Gupta, B. B. Gupta, Defensive mechanism against DDoS attack based on feature selection and multi-classifier algorithms, Telecommun. Syst., 82 (2023), 229–244. https://doi.org/10.1007/s11235-022-00981-4 doi: 10.1007/s11235-022-00981-4
|
| [27] | I. Sharafaldin, A. H. Lashkari, S. Hakak, A. A. Ghorbani, Developing realistic Distributed Denial of Service (DDoS) attack dataset and taxonomy, in International Carnahan Conference on Security Technology (ICCST), (2019), 1–8. https://doi.org/10.1109/CCST.2019.8888419 |
| [28] | A. Prasad, S. Chandra, Defending ARP spoofing-based MitM attack using machine learning and device profiling, in 2019 International Carnahan Conference on Security Technology (ICCST), (2022), 978–982. https://doi.org/10.1109/ICCCIS56430.2022.10037723 |
| [29] |
D. Tang, L. Tang, R. Dai, J. Chen, X. Li, J. Rodrigues, MF-Adaboost: LDoS attack detection based on multi-features and improved Adaboost, Future Gener. Comput. Syst., 106 (2020), 347–359. https://doi.org/10.1016/j.future.2019.12.034 doi: 10.1016/j.future.2019.12.034
|
| [30] | B. Sabir, M. A. Babar, R. Gaire, A. Abuadbba, Reliability and robustness analysis of machine learning based phishing URL detectors, arXiv preprint, (2022), arXiv: 2005.08454. https://doi.org/10.48550/arXiv.2005.08454 |
| [31] |
S. A. Khanday, H. Fatima, N. Rakesh, Implementation of intrusion detection model for DDoS attacks in Lightweight IoT Networks, Expert Syst. Appl., 215 (2023), 119330. https://doi.org/10.1016/j.eswa.2022.119330 doi: 10.1016/j.eswa.2022.119330
|
| [32] |
M. M. Alani, E. Damiani, XRecon: An explainbale IoT reconnaissance attack detection system based on ensemble learning, Sensors, 23 (2023), 5298. https://doi.org/10.3390/s23115298 doi: 10.3390/s23115298
|
| [33] |
R. Verma, S. Chandra, RepuTE: A soft voting ensemble learning framework for reputation-based attack detection in fog-IoT milieu, Eng. Appl. Artif. Intell., 118 (2023), 105670. https://doi.org/10.1016/j.engappai.2022.105670 doi: 10.1016/j.engappai.2022.105670
|
| [34] | S. Pokhrel, R. Abbas, B. Aryal, IoT security: botnet detection in IoT using machine learning, arXiv preprint, (2021), arXiv: 2104.02231. https://doi.org/10.48550/arXiv.2104.02231 |
| [35] |
A. P. Bradley, The use of the area under the ROC curve in the evaluation of machine learning algorithms, Pattern Recognit., 30 (1997), 1145–1159. https://doi.org/10.1016/S0031-3203(96)00142-2 doi: 10.1016/S0031-3203(96)00142-2
|
| [36] |
D. Chicco, G. Jurman, The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation, BMC Genomics, 21 (2020), 6. https://doi.org/10.1186/s12864-019-6413-7 doi: 10.1186/s12864-019-6413-7
|
| [37] | Md. M. Rashid, J. Kamruzzaman, M. Ahmed, N. Islam, S. Wibowo, S. Gordon, Performance enhancement of intrusion detection system using bagging ensemble technique with feature selection, in 2020 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), (2020), 1–5. https://doi.org/10.1109/CSDE50874.2020.9411608 |
| [38] | Md. Raihan-Al-Masud, H. A. Mustafa, Network intrusion detection system using voting ensemble machine learning, in 2019 IEEE International Conference on Telecommunications and Photonics (ICTP), (2019), 1–4. https://doi.org/10.1109/ICTP48844.2019.9041736 |
| [39] |
S. V. J. Rani, I. Ioannou, P. Nagaradjane, C. Christophorou, V. Vassiliou, S. Charan, et al., Detection of DDoS attacks in D2D communications using machine learning approach, Comput. Commun., 198 (2023), 32–51. https://doi.org/10.1016/j.comcom.2022.11.013 doi: 10.1016/j.comcom.2022.11.013
|
| [40] |
S. ur Rehman, M. Khaliq, S. I. Imtiaz, A. Rasool, M. Shafiq, A. R. Javed, et al., DIDDOS: An approach for detection and identification of Distributed Denial of Service (DDoS) cyberattacks using Gated Recurrent Units (GRU), Future Gener. Comput. Syst., 118 (2021), 453–466. https://doi.org/10.1016/j.future.2021.01.022 doi: 10.1016/j.future.2021.01.022
|
| [41] |
R. J. Alzahrani, A. Alzahrani, Security analysis of DDoS attacks using machine learning algorithms in networks traffic, Electronics, 10 (2021), 2919. https://doi.org/10.3390/electronics10232919 doi: 10.3390/electronics10232919
|
| [42] |
S. Sindian, S. Sindian, An enhanced deep autoencoder-based approach for DDoS attack detection, Wseas Trans. Syst. Control, 15 (2020), 716–724. https://doi.org/10.37394/23203.2020.15.72 doi: 10.37394/23203.2020.15.72
|
| [43] |
I. Ortet Lopes, D. Zou, F. A. Ruambo, S. Akbar, B. Yuan, Towards effective detection of recent DDoS attacks: A deep learning approach, Secur. Commun. Netw., 2021 (2021), 1–14. https://doi.org/10.1155/2021/5710028 doi: 10.1155/2021/5710028
|
| [44] |
D. Javeed, T. Gao, M. T. Khan, SDN-enabled hybrid DL-driven framework for the detection of emerging cyber threats in IoT, Electronics, 10 (2021), 918. https://doi.org/10.3390/electronics10080918 doi: 10.3390/electronics10080918
|










Figures(11) / Tables(7)
Arvind Prasad, Shalini Chandra, Ibrahim Atoum, Naved Ahmad, Yazeed Alqahhas. A collaborative prediction approach to defend against amplified reflection and exploitation attacks[J]. Electronic Research Archive, 2023, 31(10): 6045-6070. doi: 10.3934/era.2023308







 DownLoad:
DownLoad: