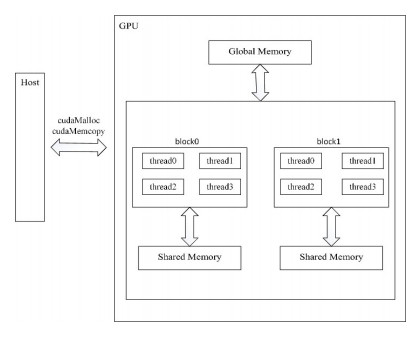
Many systems in real world can be represented as network, and network analysis can help us understand these systems. Node centrality is an important problem and has attracted a lot of attention in the field of network analysis. As the rapid development of information technology, the scale of network data is rapidly increasing. However, node centrality computation in large-scale networks is time consuming. Parallel computing is an alternative to speed up the computation of node centrality. GPU, which has been a core component of modern computer, can make a large number of core tasks work in parallel and has the ability of big data processing, and has been widely used to accelerate computing. Therefore, according to the parallel characteristic of GPU, we design the parallel algorithms to compute three widely used node centralities, i.e., closeness centrality, betweenness centrality and PageRank centrality. Firstly, we classify the three node centralities into two groups according to their definitions; secondly, we design the parallel algorithms by mapping the centrality computation of different nodes into different blocks or threads in GPU; thirdly, we analyze the correlations between different centralities in several networks, benefited from the designed parallel algorithms. Experimental results show that the parallel algorithms designed in this paper can speed up the computation of node centrality in large-scale networks, and the closeness centrality and the betweenness centrality are weakly correlated, although both of them are based on the shortest path.
Citation: Siyuan Yin, Yanmei Hu, Yuchun Ren. The parallel computing of node centrality based on GPU[J]. Mathematical Biosciences and Engineering, 2022, 19(3): 2700-2719. doi: 10.3934/mbe.2022123
Many systems in real world can be represented as network, and network analysis can help us understand these systems. Node centrality is an important problem and has attracted a lot of attention in the field of network analysis. As the rapid development of information technology, the scale of network data is rapidly increasing. However, node centrality computation in large-scale networks is time consuming. Parallel computing is an alternative to speed up the computation of node centrality. GPU, which has been a core component of modern computer, can make a large number of core tasks work in parallel and has the ability of big data processing, and has been widely used to accelerate computing. Therefore, according to the parallel characteristic of GPU, we design the parallel algorithms to compute three widely used node centralities, i.e., closeness centrality, betweenness centrality and PageRank centrality. Firstly, we classify the three node centralities into two groups according to their definitions; secondly, we design the parallel algorithms by mapping the centrality computation of different nodes into different blocks or threads in GPU; thirdly, we analyze the correlations between different centralities in several networks, benefited from the designed parallel algorithms. Experimental results show that the parallel algorithms designed in this paper can speed up the computation of node centrality in large-scale networks, and the closeness centrality and the betweenness centrality are weakly correlated, although both of them are based on the shortest path.

| [1] | N. Safari-Alighiarloo, M. Taghizadeh, M. Rezaei-Tavirani, Protein-protein interaction networks (PPI) and complex diseases, Gastroenterol. Hepatol. Bed. Bench., 7 (2014), 17–31. |
| [2] |
B. Duo, Q. Wu, X. Yuan, Anti-jamming 3D trajectory design for UAV-enabled wireless sensor networks under probabilistic LoS channel, IEEE Trans. Veh. Technol., 69 (2020), 16288–16293. https://doi.org/10.1109/TVT.2020.3040334 doi: 10.1109/TVT.2020.3040334

|
| [3] | R. Zafarani, M. A. Abbasi, H. Liu, Social media mining: an introduction, Cambridge University Press, (2014), 41–49. https://doi.org/10.1017/CBO9781139088510 |
| [4] |
Y. LeCun, Y. Bengio, G. Hinton, Deep learning, Nature, 521 (2015), 436–444. https://doi.org/10.1038/nature14539 doi: 10.1038/nature14539
|
| [5] |
X. Li, M. Yin, Hybrid differential evolution with biogeography-based optimization for design of a reconfigurable antenna array with discrete phase shifters, Int. J. Antennas. Propag., (2011), 685629. https://doi.org/10.1155/2011/685629 doi: 10.1155/2011/685629
|
| [6] | X. Li, M. Yin, Design of a reconfigurable antenna array with discrete phase shifters using differential evolution algorithm, Prog. Electromagn. Res., 31 (2011), 29–43. http://dx.doi.org/10.2528/PIERB11032902 |
| [7] |
X. Li, S. Ma, Multi-objective memetic search algorithm for multi-objective permutation flow shop scheduling problem, IEEE Access, 4 (2016), 2154–2165. https://doi.org/10.1109/ACCESS.2016.2565622 doi: 10.1109/ACCESS.2016.2565622
|
| [8] | R. Cypher, J. Sanz, The SIMD model of parallel computation, Springer, 1994. http://dx.doi.org/10.1007/978-1-4612-2612-3 |
| [9] | D. A. Bader, K. Madduri, Designing multithreaded algorithm for breadth-first search and st-connectivity on the Cray MTA-2, in International Conference on Parallel Processing, IEEE, (2006), 523–530. https://doi.org/10.1109/ICPP.2006.34 |
| [10] | A. Siriam, K. Gautham, K. Kothapalli, Evaluating centrality metrics in real-world networks on GPU, 2009. Available from: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.622.9442 |
| [11] | A. McLaughlin, D. A. Bader, Scalable and high performance betweenness centrality on the GPU, in International Conference for High Performance Computing, Networking, Storage and Analysis, IEEE, (2014), 572–583. https://doi.org/10.1109/SC.2014.52 |
| [12] | Y. Jia, V. Lu, J. Hoberock, et al., Edge v.s node parallelism for graph centrality metrics, in GPU Computing Gems (eds. W. W. Hwu), Elsevier, (2012), 15–28. https://doi.org/10.1016/B978-0-12-385963-1.00002-2 |
| [13] | H. Yin, A. R. Benson, J. Leskovec, The local closure coefficient: a new perspective on network clustering, in Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, ACM, (2019), 303–311. https://doi.org/10.1145/3289600.3290991 |
| [14] |
Y. M. Hu, B. Yang, H. S. Wong, A weighted local view method based on observation over ground truth for community detection, Inform. Sci., 355 (2016), 37–57. https://doi.org/10.1016/j.ins.2016.03.028 doi: 10.1016/j.ins.2016.03.028
|
| [15] |
Y. M. Hu, B. Yang, Enhanced link clustering with observations on ground truth to discover social circles, Knowl-Based. Syst., 73 (2015), 227–235. https://doi.org/10.1016/j.knosys.2014.10.006 doi: 10.1016/j.knosys.2014.10.006
|
| [16] | B. Elbirt, The nature of networks: a structural census of degree centrality across multiple network sizes and edge densities, Ph.D. thesis, State University of New York at BuffaloIn, 2007. |
| [17] |
K. F. Cheung, M. G. H. Bell, J. J. Pan, An eigenvector centrality analysis of world container shipping network connectivity, Transport. Res. E-Log., 140 (2020), 101991. https://doi.org/10.1016/j.tre.2020.101991 doi: 10.1016/j.tre.2020.101991
|
| [18] |
T. Ioanna, B. Y. Ricardo, B. Francesco, Temporal betweenness centrality in dynamic graphs, Int. J. Data Sci. Anal., 9 (2020), 257–272. https://doi.org/10.1007/s41060-019-00189-x doi: 10.1007/s41060-019-00189-x
|
| [19] | I. G. Adebayo, Y. X. Sun, A novel approach of closeness centrality measure for voltage stability analysis in an electric power grid, Int. J. Emerg. Electr. Power Syst. 3 (2020). http://doi.org/10.1515/ijeeps-2020-0013 |
| [20] |
A. Hashemi, M. B. Dowlatshahi, H. Nezamabadi-pour, MGFS: A multi-label graph-based feature selection algorithm via PageRank centrality, Expert Syst. Appl., 142 (2019), 113024. https://doi.org/10.1016/j.eswa.2019.113024 doi: 10.1016/j.eswa.2019.113024
|
| [21] |
U. Brandes, A faster algorithm for betweenness centrality, J. Math. Sociol., 25 (2001), 163–177. https://doi.org/10.1080/0022250X.2001.9990249 doi: 10.1080/0022250X.2001.9990249
|
| [22] |
G. Zhao, P. Jia, A. Zhou, InfGCN: Identifying influential nodes in complex networks with graph convolutional networks, Neurocomputing, 414 (2020), 18–26. https://doi.org/10.1016/j.neucom.2020.07.028 doi: 10.1016/j.neucom.2020.07.028
|
| [23] | S. Buß, H. Molter, R. Niedermeier, Algorithmic aspects of temporal betweenness, in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ACM, (2020), 2084–2092. https://doi.org/10.1145/3394486.3403259 |
| [24] |
E. Y. Yu, Y. P Wang, Y. Fu, Identifying critical nodes in complex networks via graph convolutional networks, Knowl-Based. Syst., 198 (2020), 105893. https://doi.org/10.1016/j.knosys.2020.105893 doi: 10.1016/j.knosys.2020.105893
|
| [25] | S. Ahamed, M. Samad, Information mining for covid-19 research from a large volume of scientific literature, preprint, arXiv: 2004.02085. http://arXiv.org/abs/2004.02085 |
| [26] |
L. E. Suárez, B. A. Richards, G. Lajoie, Learning function from structure in neuromorphic networks, Nat. Mach. Intell., 3 (2021), 771–786. https://doi.org/10.1038/s42256-021-00376-1 doi: 10.1038/s42256-021-00376-1
|
| [27] |
S. Brin, L. Page, The anatomy of a large-scale hypertextual Web search engine, Comput. Support. Coop. Work, 30 (1998), 107–117. https://doi.org/10.1016/S0169-7552(98)00110-X doi: 10.1016/S0169-7552(98)00110-X
|
| [28] |
U. Brandes, C. Pich, Centrality estimation in large networks, Int. J. Bifurcat. Chaos., 17 (2007), 2303–2318. https://doi.org/10.1142/S0218127407018403 doi: 10.1142/S0218127407018403
|
| [29] |
J. Liu, Z. Ren, Q. Guo, Node importance ranking of complex networks, Acta Phys. Sinica., 62 (2013), 178901. https://doi.org/10.7498/aps.62.178901 doi: 10.7498/aps.62.178901
|
| [30] | G. Csárdi, T. Nepusz, The igraph software package for complex network research, Int. J. Complex Syst., 1695 (2006), 1–9. http://igraph.sf.net |






Figures(7) / Tables(3)

Siyuan Yin, Yanmei Hu, Yuchun Ren. The parallel computing of node centrality based on GPU[J]. Mathematical Biosciences and Engineering, 2022, 19(3): 2700-2719. doi: 10.3934/mbe.2022123







 DownLoad:
DownLoad: