Mycobacterium avium subsp. paratuberculosis (MAP) may play a role in the pathology of human inflammatory bowel disease (IBD). Previously, we found a high frequency (98% in patients with active disease) of MAP DNA detection in the blood of Portuguese Crohn's Disease patients, suggesting this cohort has high exposure to MAP organisms. Water is an important route for MAP dissemination, in this study we therefore aimed to assess MAP contamination within water sources in Porto area (the residential area of our IBD study cohort).
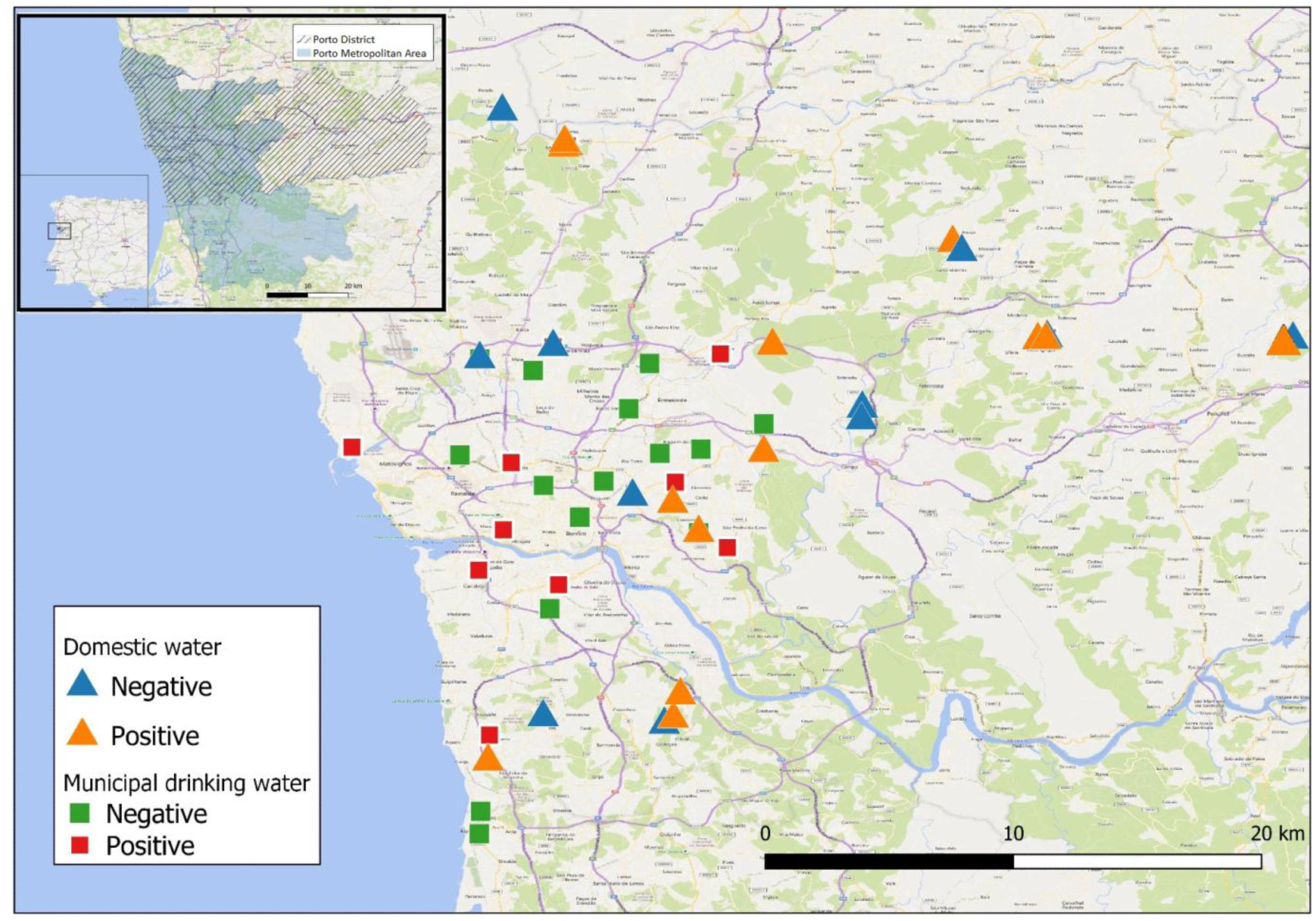
Water and biofilms were collected in a wide variety of locations within the Porto area, including taps connected to domestic water sources and from municipal water distribution systems. Baseline samples were collected in early autumn plus further domestic water samples in early winter, to assess the effect of winter rainfall. DNA was extracted from all 131 samples and IS900-based nested PCR used to assess the frequency of MAP presence.
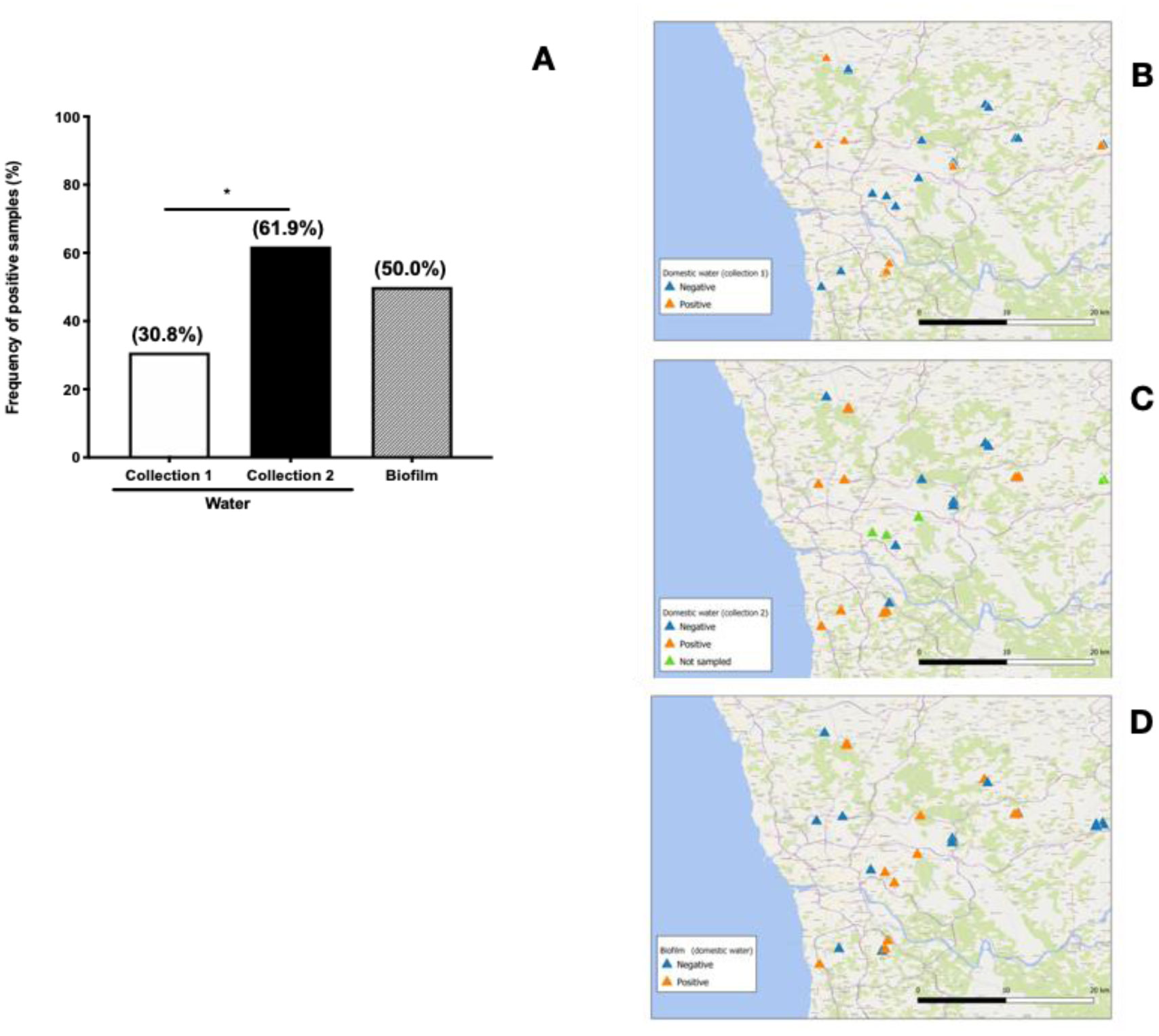
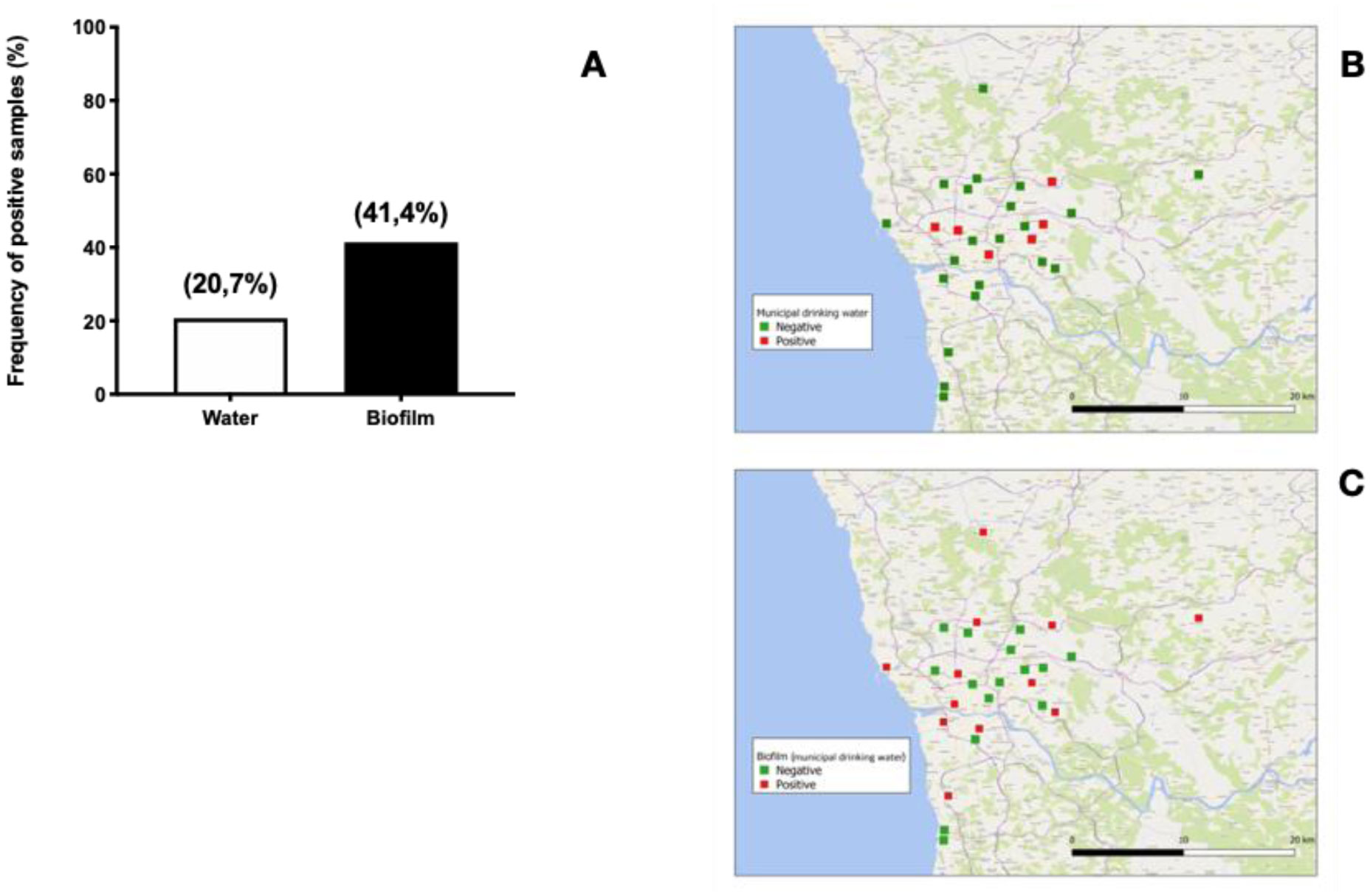
Our results show high MAP positivity in municipal water sources (20.7% of water samples and 41.4% of biofilm samples) and even higher amongst domestic sources (30.8% of water samples and 50% of biofilm samples). MAP positivity in biofilms correlated with positivity in water samples from the same sources. A significantly higher frequency of MAP-positivity was observed during winter rains as compared with samples collected in autumn prior to the winter rainfall period (61.9% versus 30.8%). We conclude that domestic and municipal water sources of Porto region have a high burden of MAP contamination and this prevalence increases with rainfall. We hypothesize that human exposure to MAP from local water supplies is commonplace and represents a major route for MAP transmission and challenge which, if positively linked to disease pathology, may contribute to the observed high prevalence of IBD in Porto district.
Citation: Telma Sousa, Marta Costa, Pedro Sarmento, Maria Conceição Manso, Cristina Abreu, Tim J. Bull, José Cabeda, Amélia Sarmento. DNA-based detection of Mycobacterium avium subsp. paratuberculosis in domestic and municipal water from Porto (Portugal), an area of high IBD prevalence[J]. AIMS Microbiology, 2021, 7(2): 163-174. doi: 10.3934/microbiol.2021011
Mycobacterium avium subsp. paratuberculosis (MAP) may play a role in the pathology of human inflammatory bowel disease (IBD). Previously, we found a high frequency (98% in patients with active disease) of MAP DNA detection in the blood of Portuguese Crohn's Disease patients, suggesting this cohort has high exposure to MAP organisms. Water is an important route for MAP dissemination, in this study we therefore aimed to assess MAP contamination within water sources in Porto area (the residential area of our IBD study cohort).
Water and biofilms were collected in a wide variety of locations within the Porto area, including taps connected to domestic water sources and from municipal water distribution systems. Baseline samples were collected in early autumn plus further domestic water samples in early winter, to assess the effect of winter rainfall. DNA was extracted from all 131 samples and IS900-based nested PCR used to assess the frequency of MAP presence.
Our results show high MAP positivity in municipal water sources (20.7% of water samples and 41.4% of biofilm samples) and even higher amongst domestic sources (30.8% of water samples and 50% of biofilm samples). MAP positivity in biofilms correlated with positivity in water samples from the same sources. A significantly higher frequency of MAP-positivity was observed during winter rains as compared with samples collected in autumn prior to the winter rainfall period (61.9% versus 30.8%). We conclude that domestic and municipal water sources of Porto region have a high burden of MAP contamination and this prevalence increases with rainfall. We hypothesize that human exposure to MAP from local water supplies is commonplace and represents a major route for MAP transmission and challenge which, if positively linked to disease pathology, may contribute to the observed high prevalence of IBD in Porto district.

| [1] |
McClure HM, Chiodini RJ, Anderson DC, et al. (1987) Mycobacterium paratuberculosis infection in a colony of stumptail macaques (Macaca arctoides). The J Infect Dis 155: 1011-1019. doi: 10.1093/infdis/155.5.1011

|
| [2] |
Judge J, Kyriazakis I, Greig A, et al. (2005) Clustering of Mycobacterium avium subsp. paratuberculosis in rabbits and the environment: how hot is a hot spot? Appl Environ Microb 71: 6033-6038. doi: 10.1128/AEM.71.10.6033-6038.2005
|
| [3] |
Good M, Clegg T, Sheridan H, et al. (2009) Prevalence and distribution of paratuberculosis (Johne's disease) in cattle herds in Ireland. Irish Vet J 62: 597-606. doi: 10.1186/2046-0481-62-9-597
|
| [4] |
Nielsen SS, Toft N (2009) A review of prevalences of paratuberculosis in farmed animals in Europe. Prev Vet Med 88: 1-14. doi: 10.1016/j.prevetmed.2008.07.003
|
| [5] |
Manning EJB, Collins MT (2001) Mycobacterium avium subsp. paratuberculosis: pathogen, pathogenesis and diagnosis. Rev Sci Tech Off Int Epiz 20: 133-150. doi: 10.20506/rst.20.1.1275
|
| [6] |
Waddell LA, Rajic A, Stark KDC, et al. (2015) The zoonotic potencial of Mycobacterium avium ssp. paratuberculosis: a systematic review and meta-analysis of the evidence. Epidemiol Infect 143: 3135-3157. doi: 10.1017/S095026881500076X
|
| [7] |
Zamani S, Zali MR, Aghdaei HA, et al. (2016) Mycobacterium avium subsp. paratuberculosis and associated risk factors for inflammatory bowel disease in Iranian patients. Gut Pathog 9: 1-10. doi: 10.1186/s13099-016-0151-z
|
| [8] |
Kuenstner JT, Potula R, Bull TJ, et al. (2020) Presence of infection by Mycobacterium avium subsp. paratuberculosis in the blood of patients with Crohn's disease and control subjects shown by multiple laboratory culture and antibody methods. Microorg 8: 2054. doi: 10.3390/microorganisms8122054
|
| [9] |
Annese V (2020) Genetics and epigenetics of IBD. Pharmacol Res 159: 104892. doi: 10.1016/j.phrs.2020.104892
|
| [10] |
Turpin W, Goethel A, Bedrani L, et al. (2018) Determinants of IBD heritability: genes, bugs, and more. Inflamm Bowel Dis 24: 1133-1148. doi: 10.1093/ibd/izy085
|
| [11] |
Alam MT, Amos GCA, Murphy ARJ, et al. (2020) Microbial imbalance in inflammatory bowel disease patients at different taxonomic levels. Gut Pathog 12: 1-8. doi: 10.1186/s13099-019-0341-6
|
| [12] |
Iacob DG (2019) Infectious threats, the intestinal barrier, and its trojan horse: dysbiosis. Front Microbiol 10: 1676. doi: 10.3389/fmicb.2019.01676
|
| [13] |
Lee A, Griffiths TA, Parab RS, et al. (2011) Association of Mycobacterium avium subspecies paratuberculosis with Crohn disease in pediatric patients. J Pediatr Gastroenterol Nutr 52: 170-174. doi: 10.1097/MPG.0b013e3181ef37ba
|
| [14] | Renouf MJ, Cho YH, McPhee JB (2018) Emergent behavior of IBD-associated Escherichia coli during disease. Inflammatory Bowel Dis 387: 96-12. |
| [15] |
Agrawal G, Clancy A, Huynh R, et al. (2020) Profound remission in Crohn's disease requiring no further treatment for 3–23 years: a case series. Gut Pathog 12: 16. doi: 10.1186/s13099-020-00355-8
|
| [16] |
Waddell L, Rajić A, Stärk K, et al. (2016) Mycobacterium avium ssp. paratuberculosis detection in animals, food, water and other sources or vehicles of human exposure: A scoping review of the existing evidence. Prev Vet Med 132: 32-48. doi: 10.1016/j.prevetmed.2016.08.003
|
| [17] |
Pierce ES (2018) Where are all the Mycobacterium avium subspecies paratuberculosis in patients with Crohn's disease? Plos Pathog 5: e1000234. doi: 10.1371/journal.ppat.1000234
|
| [18] |
Falkinham JO (2003) Mycobacterial aerosols and respiratory disease. Emerg Infect Dis 9: 763-767. doi: 10.3201/eid0907.020415
|
| [19] |
Angenent LT, Kelley ST, Amand ASt, et al. (2005) Molecular identification of potential pathogens in water and air of a hospital therapy pool. P Natl Acad Sci Usa 102: 4860-4865. doi: 10.1073/pnas.0501235102
|
| [20] |
Falkinham J (2018) Mycobacterium avium complex: adherence as a way of life. AIMS Microbiol 4: 428-438. doi: 10.3934/microbiol.2018.3.428
|
| [21] |
Pickup RW, Rhodes G, Bull TJ, et al. (2006) Mycobacterium avium subsp. paratuberculosis in lake catchments, in river water abstracted for domestic use, and in effluent from domestic sewage treatment works: diverse opportunities for environmental cycling and human exposure. Appl Environ Microb 72: 4067-4077. doi: 10.1128/AEM.02490-05
|
| [22] |
Samba-Louaka A, Robino E, Cochard T, et al. (2018) Environmental Mycobacterium avium subsp. paratuberculosis hosted by free-living amoebae. Front Cell Infect Microbiol 8: 28. doi: 10.3389/fcimb.2018.00028
|
| [23] |
Azevedo LF, Magro F, Portela F, et al. (2010) Estimating the prevalence of inflammatory bowel disease in Portugal using a pharmaco-epidemiological approach. Pharmacoepidemiol Drug Saf 19: 499-510. doi: 10.1002/pds.1930
|
| [24] |
Nazareth N, Magro F, Machado E, et al. (2015) Prevalence of Mycobacterium avium subsp. paratuberculosis and Escherichia coli in blood samples from patients with inflammatory bowel disease. Med Microbiol Immunol 204: 681-692. doi: 10.1007/s00430-015-0420-3
|
| [25] |
Pickup RW, Rhodes G, Arnott S, et al. (2005) Mycobacterium avium subsp. paratuberculosis in the catchment area and water of the River Taff in South Wales, United Kingdom, and its potential relationship to clustering of Crohn's disease cases in the city of Cardiff. Appl Environ Microbiol 71: 2130-2139. doi: 10.1128/AEM.71.4.2130-2139.2005
|
| [26] | Rhodes G, Henrys P, Thomson BC, et al. (2013) Mycobacterium avium subspecies paratuberculosis is widely distributed in British soils and waters: implications for animal and human health. Environ Microbiol 15: 2761-2774. |
| [27] |
Cunha MV, Rosalino LM, Leão C, et al. (2020) Ecological drivers of Mycobacterium avium subsp. paratuberculosis detection in mongoose (Herpestes ichneumon) using IS900 as proxy. Sci Rep-uk 10: 860. doi: 10.1038/s41598-020-57679-3
|
| [28] |
Beumer A, King D, Donohue M, et al. (2010) Detection of Mycobacterium avium subsp. paratuberculosis in drinking water and biofilms by quantitative PCR. Appl Environl Microbiol 76: 7367-7370. doi: 10.1128/AEM.00730-10
|
| [29] |
Bull TJ, McMinn EJ, Sidi-Boumedine K, et al. (2003) Detection and verification of Mycobacterium avium subsp. paratuberculosis in fresh ileocolonic mucosal biopsy specimens from individuals with and without Crohn's disease. J Clin Microbiol 41: 2915-2923. doi: 10.1128/JCM.41.7.2915-2923.2003
|
| [30] |
Aboagye G, Rowe MT (2011) Occurrence of Mycobacterium avium subsp. paratuberculosis in raw water and water treatment operations for the production of potable water. Water Res 45: 3271-3278. doi: 10.1016/j.watres.2011.03.029
|
| [31] |
Taylor RH, Falkinham JO, Norton CD, et al. (2000) Chlorine, chloramine, chlorine dioxide, and ozone susceptibility of Mycobacterium avium. Appl Environ Microb 66: 1702-1705. doi: 10.1128/AEM.66.4.1702-1705.2000
|
| [32] |
Esteban J, García-Coca M (2018) Mycobacterium biofilms. Front Microbiol 8: 414-418. doi: 10.3389/fmicb.2017.02651
|
| [33] |
Pistone D, Marone P, Pajoro M, et al. (2012) Mycobacterium avium paratuberculosis in Italy: commensal or emerging human pathogen? Digest Liver Dis 44: 461-465. doi: 10.1016/j.dld.2011.12.022
|
| [34] |
Coelho AC, Pinto ML, Silva S, et al. (2007) Seroprevalence of ovine paratuberculosis infection in the Northeast of Portugal. Small Ruminant Res 71: 298-303. doi: 10.1016/j.smallrumres.2006.07.009
|
| [35] | Leão C, Amaro A, Santos-Sanches I, et al. (2015) Paratuberculosis asymptomatic cattle as plillovers of Mycobacterium avium subsp. paratuberculosis: consequences for disease control. Rev Port Cien Vet 110: 69-73. |
Figures(3)

Telma Sousa, Marta Costa, Pedro Sarmento, Maria Conceição Manso, Cristina Abreu, Tim J. Bull, José Cabeda, Amélia Sarmento. DNA-based detection of Mycobacterium avium subsp. paratuberculosis in domestic and municipal water from Porto (Portugal), an area of high IBD prevalence[J]. AIMS Microbiology, 2021, 7(2): 163-174. doi: 10.3934/microbiol.2021011







 DownLoad:
DownLoad: