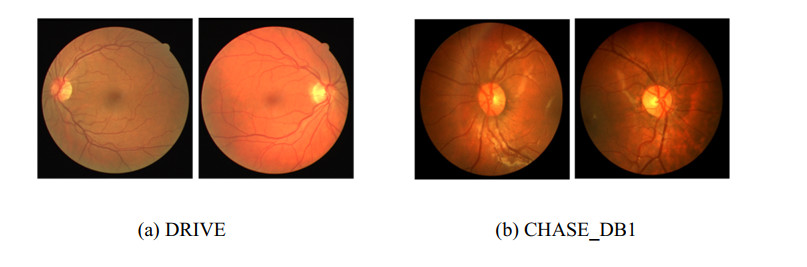
Retinal vessel segmentation is very important for diagnosing and treating certain eye diseases. Recently, many deep learning-based retinal vessel segmentation methods have been proposed; however, there are still many shortcomings (e.g., they cannot obtain satisfactory results when dealing with cross-domain data or segmenting small blood vessels). To alleviate these problems and avoid overly complex models, we propose a novel network based on a multi-scale feature and style transfer (MSFST-NET) for retinal vessel segmentation. Specifically, we first construct a lightweight segmentation module named MSF-Net, which introduces the selective kernel (SK) module to increase the multi-scale feature extraction ability of the model to achieve improved small blood vessel segmentation. Then, to alleviate the problem of model performance degradation when segmenting cross-domain datasets, we propose a style transfer module and a pseudo-label learning strategy. The style transfer module is used to reduce the style difference between the source domain image and the target domain image to improve the segmentation performance for the target domain image. The pseudo-label learning strategy is designed to be combined with the style transfer module to further boost the generalization ability of the model. Moreover, we trained and tested our proposed MSFST-NET in experiments on the DRIVE and CHASE_DB1 datasets. The experimental results demonstrate that MSFST-NET can effectively improve the generalization ability of the model on cross-domain datasets and achieve improved retinal vessel segmentation results than other state-of-the-art methods.
Citation: Caixia Zheng, Huican Li, Yingying Ge, Yanlin He, Yugen Yi, Meili Zhu, Hui Sun, Jun Kong. Retinal vessel segmentation based on multi-scale feature and style transfer[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 49-74. doi: 10.3934/mbe.2024003
Retinal vessel segmentation is very important for diagnosing and treating certain eye diseases. Recently, many deep learning-based retinal vessel segmentation methods have been proposed; however, there are still many shortcomings (e.g., they cannot obtain satisfactory results when dealing with cross-domain data or segmenting small blood vessels). To alleviate these problems and avoid overly complex models, we propose a novel network based on a multi-scale feature and style transfer (MSFST-NET) for retinal vessel segmentation. Specifically, we first construct a lightweight segmentation module named MSF-Net, which introduces the selective kernel (SK) module to increase the multi-scale feature extraction ability of the model to achieve improved small blood vessel segmentation. Then, to alleviate the problem of model performance degradation when segmenting cross-domain datasets, we propose a style transfer module and a pseudo-label learning strategy. The style transfer module is used to reduce the style difference between the source domain image and the target domain image to improve the segmentation performance for the target domain image. The pseudo-label learning strategy is designed to be combined with the style transfer module to further boost the generalization ability of the model. Moreover, we trained and tested our proposed MSFST-NET in experiments on the DRIVE and CHASE_DB1 datasets. The experimental results demonstrate that MSFST-NET can effectively improve the generalization ability of the model on cross-domain datasets and achieve improved retinal vessel segmentation results than other state-of-the-art methods.

| [1] |
B. Swenor, V. Varadaraj, M. J. Lee, H. Whitson, P. Ramulu, World Health Report on vision: Aging implications for global vision and eye health, Innovation Aging, 4 (2020), 807–808. https://doi.org/10.1093/geroni/igaa057.2933 doi: 10.1093/geroni/igaa057.2933

|
| [2] |
T. Li, W. Bo, C. Hu, H. Kang, H. Liu, K. Wang, et al., Applications of deep learning in fundus images: A review, Med. Image Anal., 69 (2021), 101971. https://doi.org/10.1016/j.media.2021.101971 doi: 10.1016/j.media.2021.101971
|
| [3] |
J. Wang, L. Zhou, Z. Yuan, H. Wang, C. Shi, MIC-Net: Multi-scale integrated context network for automatic retinal vessel segmentation in fundus image, Math. Biosci. Eng., 20 (2023), 6912–6931. https://doi.org/10.3934/mbe.2023298 doi: 10.3934/mbe.2023298
|
| [4] |
J. V. Soares, J. J. Leandro, R. M. Cesar, H. F. Jelinek, M. J. Cree, Retinal vessel segmentation using the 2-D Gabor wavelet and supervised classification, IEEE Trans. Med. Imaging, 25 (2006), 1214–1222. https://doi.org/10.1109/TMI.2006.879967 doi: 10.1109/TMI.2006.879967
|
| [5] | J. I. Orlando, M. Blaschko, Learning fully-connected CRFs for blood vessel segmentation in retinal images, in Medical Image Computing and Computer-Assisted Intervention–MICCAI 2014, Springer, (2014), 634–641. |
| [6] |
U. Nguyen, A. Bhuiyan, L. Park, K. Ramamohanarao, An effective retinal blood vessel segmentation method using multi-scale line detection, Pattern Recognit., 46 (2013), 703–715. https://doi.org/10.1016/j.patcog.2012.08.009 doi: 10.1016/j.patcog.2012.08.009
|
| [7] | O. Ronneberger, P. Fischer, T. Brox, U-net: Convolutional networks for biomedical image segmentation, in Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015, Springer, (2015), 234–241. https://doi.org/10.1007/978-3-319-24574-4_28 |
| [8] |
Y. He, H. Sun, Y. Yi, W. Chen, J. Kong, C. Zheng, Curv‐Net: Curvilinear structure segmentation network based on selective kernel and multi‐Bi‐ConvLSTM, Med. Phys., 49 (2022), 3144–3158. https://doi.org/10.1002/mp.15546 doi: 10.1002/mp.15546
|
| [9] | B. Wang, S. Qiu, H. He, Dual encoding u-net for retinal vessel segmentation, in Medical Image Computing and Computer Assisted Intervention–MICCAI 2019, Springer, (2019), 84–92. https://doi.org/10.1007/978-3-030-32239-7_10 |
| [10] | S. Zhang, H. Fu, Y. Yan, Y. Zhang, Q. Wu, M. Yang, et al., Attention guided network for retinal image segmentation, in Medical Image Computing and Computer Assisted Intervention–MICCAI 2019, Springer, (2019), 797–805. https://doi.org/10.1007/978-3-030-32239-7_88 |
| [11] | Y. Wu, Y. Xia, Y. Song, D. Zhang, D. Liu, C. Zhang, et al., Vessel-Net: Retinal vessel segmentation under multi-path supervision, in Medical Image Computing and Computer Assisted Intervention–MICCAI 2019, Springer, (2019), 264–272. https://doi.org/10.1007/978-3-030-32239-7_30 |
| [12] |
M. Shin, Z. Peng, H. J. Kim, S. S. Yoo, K. Yoon, Multivariable-incorporating super-resolution residual network for transcranial focused ultrasound simulation, Comput. Methods Programs Biomed. , 237 (2023), 107591. https://doi.org/10.1016/j.cmpb.2023.107591 doi: 10.1016/j.cmpb.2023.107591
|
| [13] |
S. Suh, S. Cheon, W. Choi, Y. Chung, W. Cho, J. Paik, et al., Supervised segmentation with domain adaptation for small sampled orbital CT images, J. Comput. Des. Eng., 9 (2022), 783–792. https://doi.org/10.1093/jcde/qwac029 doi: 10.1093/jcde/qwac029
|
| [14] | J. Long, E. Shelhamer, T. Darrell, Fully convolutional networks for semantic segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2015), 3431–3440. https://doi.org/10.1109/CVPR.2015.7298965 |
| [15] | O. Oktay, J. Schlemper, L. Le Folgoc, M. Lee, M. Heinrich, K. Misawa, et al., Attention u-net: Learning where to look for the pancreas, arXiv preprint, (2018), arXiv: 1804.03999. https://doi.org/10.48550/arXiv.1804.03999 |
| [16] | Z. Zhou, M. M. Rahman Siddiquee, N. Tajbakhsh, J. Liang, Unet++: A nested u-net architecture for medical image segmentation, in Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Springer, (2018), 3–11. https://doi.org/10.1007/978-3-030-00889-5_1 |
| [17] |
J. Son, S. J. Park, K. H. Jung, Towards accurate segmentation of retinal vessels and the optic disc in fundoscopic images with generative adversarial networks, J. Digital Imaging, 32 (2019), 499–512. https://doi.org/10.1007/s10278-018-0126-3 doi: 10.1007/s10278-018-0126-3
|
| [18] |
H. Zhao, H. Li, S. Maurer-Stroh, Y. Guo, Q. Deng, L. Cheng, Supervised segmentation of un-annotated retinal fundus images by synthesis, IEEE Trans. Med. Imaging, 38 (2018), 46–56. https://doi.org/10.1109/TMI.2018.2854886 doi: 10.1109/TMI.2018.2854886
|
| [19] |
K. B. Park, S. H. Choi, J. Y. Lee, M-GAN: Retinal blood vessel segmentation by balancing losses through stacked deep fully convolutional networks, IEEE Access, 8 (2020), 146308–146322. https://doi.org/10.1109/ACCESS.2020.3015108 doi: 10.1109/ACCESS.2020.3015108
|
| [20] |
C. Yue, M. Ye, P. Wang, D. Huang, X. Lu, SRV-GAN: A generative adversarial network for segmenting retinal vessels, Math. Biosci. Eng., 19 (2022), 9948–9965. https://doi.org/10.3934/mbe.2022464 doi: 10.3934/mbe.2022464
|
| [21] | A. Galdran, A. Anjos, J. Dolz, H. Chakor, H. Lombaert, I. Ben Ayed, The little w-net that could: state-of-the-art retinal vessel segmentation with minimalistic models, arXiv preprint, (2020), arXiv: 2009.01907. https://doi.org/10.48550/arXiv.2009.01907 |
| [22] |
Y. Xia, D. Yang, Z. Yu, F. Liu, J. Cai, L. Yu, et al., Uncertainty-aware multi-view co-training for semi-supervised medical image segmentation and domain adaptation, Med. Image Anal., 65 (2020), 101766. https://doi.org/10.1016/j.media.2020.101766 doi: 10.1016/j.media.2020.101766
|
| [23] | S. Chen, X. Jia, J. He, Y. Shi, J. Liu, Semi-supervised domain adaptation based on dual-level domain mixing for semantic segmentation, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2021), 11018–11027. https://doi.org/10.1109/CVPR46437.2021.01087 |
| [24] | Z. Wang, Y. Wei, R. Feris, J. Xiong, W. Hwu, T. S. Huang, et al., Alleviating semantic-level shift: A semi-supervised domain adaptation method for semantic segmentation, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, (2020), 936–937. https://doi.org/10.1109/CVPRW50498.2020.00476 |
| [25] | X. Liu, F. Xing, N. Shusharina, R. Lim, C. Kuo, G. El Fakhri, et al., Act: Semi-supervised domain-adaptive medical image segmentation with asymmetric co-training, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2022), 66–76. https://doi.org/10.1007/978-3-031-16443-9_7 |
| [26] | Y. Chen, X. Ouyang, K. Zhu, G. Agam, Semi-supervised domain adaptation for semantic segmentation, in 2022 26th International Conference on Pattern Recognition (ICPR), (2022), 230–237. https://doi.org/10.1109/ICPR56361.2022.9956524 |
| [27] | J. Wang, C. Zhong, C. Feng, J. Sun, Y. Yokota, Feature disentanglement for cross-domain retina vessel segmentation, in 2021 IEEE International Conference on Image Processing (ICIP), (2021), 26–30. https://doi.org/10.1109/ICIP42928.2021.9506124 |
| [28] | Y. Zuo, H. Yao, C. Xu, Category-level adversarial self-ensembling for domain adaptation, in 2020 IEEE International Conference on Multimedia and Expo (ICME), (2020), 1–6. https://doi.org/10.1109/ICME46284.2020.9102756 |
| [29] | Y. Xu, B. Du, L. Zhang, Q. Zhang, G. Wang, L. Zhang, Self-ensembling attention networks: Addressing domain shift for semantic segmentation, in Proceedings of the AAAI Conference on Artificial Intelligence, (2019), 5581–5588. https://doi.org/10.1609/aaai.v33i01.33015581 |
| [30] |
H. Lei, W. Liu, H. Xie, B. Zhao, G. Yue, B. Lei, Unsupervised domain adaptation based image synthesis and feature alignment for joint optic disc and cup segmentation, IEEE J. Biomed. Health. Inf., 26 (2021), 90–102. https://doi.org/10.1109/JBHI.2021.3085770 doi: 10.1109/JBHI.2021.3085770
|
| [31] |
S. Wang, L. Yu, X. Yang, C. W. Fu, P. A. Heng, Patch-based output space adversarial learning for joint optic disc and cup segmentation, IEEE Trans. Med. Imaging, 38 (2019), 2485–2495. https://doi.org/10.1109/TMI.2019.2899910 doi: 10.1109/TMI.2019.2899910
|
| [32] | P. Liu, B. Kong, Z. Li, S. Zhang, R. Fang, CFEA: Collaborative feature ensembling adaptation for domain adaptation in unsupervised optic disc and cup segmentation, in Medical Image Computing and Computer Assisted Intervention–MICCAI 2019, Springer, (2019), 521–529. https://doi.org/10.1007/978-3-030-32254-0_58 |
| [33] | J. Y. Zhu, T. Park, P. Isola, A. A. Efros, Unpaired image-to-image translation using cycle-consistent adversarial networks, in Proceedings of the IEEE International Conference on Computer Vision, (2017), 2223–2232. |
| [34] | X. Li, W. Wang, X. Hu, J. Yang, Selective kernel networks, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2019), 510–519. |
| [35] | X. Glorot, A. Bordes, Y. Bengio, Deep sparse rectifier neural networks, in Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, (2011), 315–323. |
| [36] | S. Santurkar, D. Tsipras, A. Ilyas, A. Madry, How does batch normalization help optimization, Adv. Neural Inf. Process. Syst., 31 (2018). |
| [37] | S. Jadon, A survey of loss functions for semantic segmentation, in 2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), (2020), 1–7. https://doi.org/10.1109/CIBCB48159.2020.9277638 |
| [38] |
J. Staal, M. D. Abràmoff, M. Niemeijer, M. A. Viergever, B. Van Ginneken, Ridge-based vessel segmentation in color images of the retina, IEEE Trans. Med. Imaging, 23 (2004), 501–509. https://doi.org/10.1109/TMI.2004.825627 doi: 10.1109/TMI.2004.825627
|
| [39] |
M. M. Fraz, P. Remagnino, A. Hoppe, B. Uyyanonvara, A. R. Rudnicka, C. G. Owen, et al., An ensemble classification-based approach applied to retinal blood vessel segmentation, IEEE Trans. Biomed. Eng., 59 (2012), 2538–2548. https://doi.org/10.1109/TBME.2012.2205687 doi: 10.1109/TBME.2012.2205687
|
| [40] |
J. Wu, Y. Liu, Y. Zhu, Z. Li, Atrous residual convolutional neural network based on U-Net for retinal vessel segmentation, PlOS ONE, 17 (2022), e0273318. https://doi.org/10.1371/journal.pone.0273318 doi: 10.1371/journal.pone.0273318
|
| [41] |
J. Ryu, M. U. Rehman, I. F. Nizami, K. T. Chong, SegR-Net: A deep learning framework with multi-scale feature fusion for robust retinal vessel segmentation, Comput. Biol. Med., 163 (2023), 107132. https://doi.org/10.1016/j.compbiomed.2023.107132 doi: 10.1016/j.compbiomed.2023.107132
|
| [42] |
Z. Yan, X. Yang, K. T. Cheng, Joint segment-level and pixel-wise losses for deep learning based retinal vessel segmentation, IEEE Trans. Biomed. Eng., 65 (2018), 1912–1923. https://doi.org/10.1109/TBME.2018.2828137 doi: 10.1109/TBME.2018.2828137
|
| [43] |
K. Hu, Z. Zhang, X. Niu, Y. Zhang, C. Cao, F. Xiao, et al., Retinal vessel segmentation of color fundus images using multiscale convolutional neural network with an improved cross-entropy loss function, Neurocomputing, 309 (2018), 179–191. https://doi.org/10.1016/j.neucom.2018.05.011 doi: 10.1016/j.neucom.2018.05.011
|
| [44] |
S. Guo, K. Wang, H. Kang, Y. Zhang, Y. Gao, T. Li, BTS-DSN: Deeply supervised neural network with short connections for retinal vessel segmentation, Int. J. Med. Inf., 126 (2019), 105–113. https://doi.org/10.1016/j.ijmedinf.2019.03.015 doi: 10.1016/j.ijmedinf.2019.03.015
|
| [45] |
Z. Gu, J. Cheng, H. Fu, K. Zhou, H. Hao, Y. Zhao, et al., Ce-net: Context encoder network for 2d medical image segmentation, IEEE Trans. Med. Imaging, 38 (2019), 2281–2292. https://doi.org/10.1109/TMI.2019.2903562 doi: 10.1109/TMI.2019.2903562
|
| [46] |
J. Hu, H. Wang, S. Gao, M. Bao, T. Liu, Y. Wang, et al., S-unet: A bridge-style u-net framework with a saliency mechanism for retinal vessel segmentation, IEEE Access, 7 (2019), 174167–174177. https://doi.org/10.1109/ACCESS.2019.2940476 doi: 10.1109/ACCESS.2019.2940476
|
| [47] | L. Li, M. Verma, Y. Nakashima, H. Nagahara, R. Kawasaki, Iternet: Retinal image segmentation utilizing structural redundancy in vessel networks, in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, (2020), 3656–3665. |
| [48] | W. Wang, J. Zhong, H. Wu, Z. Wen, J. Qin, Rvseg-net: An efficient feature pyramid cascade network for retinal vessel segmentation, in Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, (2020), 796–805. https://doi.org/10.1007/978-3-030-59722-1_77 |
| [49] |
Y. Cheng, M. Ma, L. Zhang, C. Jin, L. Ma, Y. Zhou, Retinal blood vessel segmentation based on Densely Connected U-Net, Math. Biosci. Eng., 17 (2020), 3088–3108. https://doi.org/10.3934/mbe.2020175 doi: 10.3934/mbe.2020175
|
| [50] |
X. F. Du, J. S. Wang, W. Sun, UNet retinal blood vessel segmentation algorithm based on improved pyramid pooling method and attention mechanism, Phys. Med. Biol., 66 (2021), 175013. https://doi.org/10.1088/1361-6560/ac1c4c doi: 10.1088/1361-6560/ac1c4c
|
| [51] |
C. Z. Wu, J. Sun, J. Wang, L. F. Xu, S. Zhan, Encoding-decoding network with pyramid self-attention module for retinal vessel segmentation, Int. J. Autom. Comput., 18 (2021), 973–980. https://doi.org/10.1007/s11633-020-1277-0 doi: 10.1007/s11633-020-1277-0
|
| [52] | J. Zhuang, LadderNet: Multi-path networks based on U-Net for medical image segmentation, arXiv preprint, (2018), arXiv: 1810.07810. https://doi.org/10.48550/arXiv.1810.07810 |
| [53] |
X. Lü, F. Shao, Y. Xiong, W. Yang, Retinal vessel segmentation method based on two-stream networks, Acta Opt. Sin., 40 (2020), 0410002. https://doi.org/10.3788/AOS202040.0410002 doi: 10.3788/AOS202040.0410002
|
| [54] |
Q. Fu, S. Li, X. Wang, MSCNN-AM: A multi-scale convolutional neural network with attention mechanisms for retinal vessel segmentation, IEEE Access, 8 (2020), 163926–163936. https://doi.org/10.1109/ACCESS.2020.3022177 doi: 10.1109/ACCESS.2020.3022177
|
| [55] | Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, et al., Domain-adversarial training of neural networks, J. Mach. Learn. Res., 17 (2016), 2096–2030. |
| [56] | M. Ghifary, W. B. Kleijn, M. Zhang, D. Balduzzi, W. Li, Deep reconstruction-classification networks for unsupervised domain adaptation, in Computer Vision–ECCV 2016, Springer, (2016), 597–613. https://doi.org/10.1007/978-3-319-46493-0_36 |
| [57] |
J. Wang, C. Zhong, C. Feng, Y. Zhang, J. Sun, Y. Yokota, Disentangled representation for cross-domain medical image segmentation, IEEE Trans. Instrum. Meas., 72 (2022), 1–15. https://doi.org/10.1109/TIM.2022.3221131 doi: 10.1109/TIM.2022.3221131
|
| [58] | J. Zhuang, Z. Chen, J. Zhang, D. Zhang, Z. Cai, Domain adaptation for retinal vessel segmentation using asymmetrical maximum classifier discrepancy, in Proceedings of the ACM Turing Celebration Conference-China, (2019), 1–6. https://doi.org/10.1145/3321408.3322627 |











Figures(12) / Tables(6)

Caixia Zheng, Huican Li, Yingying Ge, Yanlin He, Yugen Yi, Meili Zhu, Hui Sun, Jun Kong. Retinal vessel segmentation based on multi-scale feature and style transfer[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 49-74. doi: 10.3934/mbe.2024003







 DownLoad:
DownLoad: