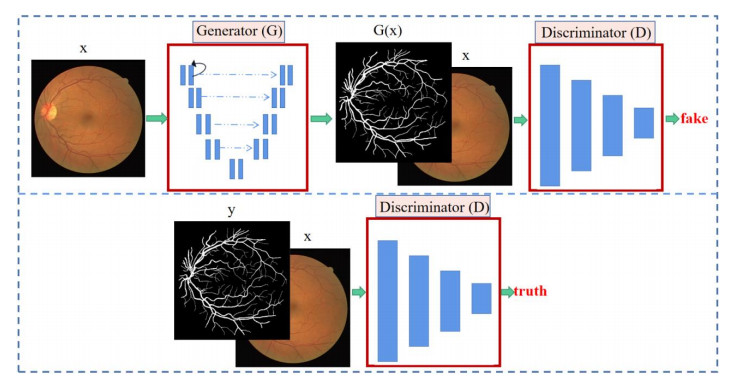
In the field of ophthalmology, retinal diseases are often accompanied by complications, and effective segmentation of retinal blood vessels is an important condition for judging retinal diseases. Therefore, this paper proposes a segmentation model for retinal blood vessel segmentation. Generative adversarial networks (GANs) have been used for image semantic segmentation and show good performance. So, this paper proposes an improved GAN. Based on R2U-Net, the generator adds an attention mechanism, channel and spatial attention, which can reduce the loss of information and extract more effective features. We use dense connection modules in the discriminator. The dense connection module has the characteristics of alleviating gradient disappearance and realizing feature reuse. After a certain amount of iterative training, the generated prediction map and label map can be distinguished. Based on the loss function in the traditional GAN, we introduce the mean squared error. By using this loss, we ensure that the synthetic images contain more realistic blood vessel structures. The values of area under the curve (AUC) in the retinal blood vessel pixel segmentation of the three public data sets DRIVE, CHASE-DB1 and STARE of the proposed method are 0.9869, 0.9894 and 0.9885, respectively. The indicators of this experiment have improved compared to previous methods.
Citation: Chen Yue, Mingquan Ye, Peipei Wang, Daobin Huang, Xiaojie Lu. SRV-GAN: A generative adversarial network for segmenting retinal vessels[J]. Mathematical Biosciences and Engineering, 2022, 19(10): 9948-9965. doi: 10.3934/mbe.2022464
In the field of ophthalmology, retinal diseases are often accompanied by complications, and effective segmentation of retinal blood vessels is an important condition for judging retinal diseases. Therefore, this paper proposes a segmentation model for retinal blood vessel segmentation. Generative adversarial networks (GANs) have been used for image semantic segmentation and show good performance. So, this paper proposes an improved GAN. Based on R2U-Net, the generator adds an attention mechanism, channel and spatial attention, which can reduce the loss of information and extract more effective features. We use dense connection modules in the discriminator. The dense connection module has the characteristics of alleviating gradient disappearance and realizing feature reuse. After a certain amount of iterative training, the generated prediction map and label map can be distinguished. Based on the loss function in the traditional GAN, we introduce the mean squared error. By using this loss, we ensure that the synthetic images contain more realistic blood vessel structures. The values of area under the curve (AUC) in the retinal blood vessel pixel segmentation of the three public data sets DRIVE, CHASE-DB1 and STARE of the proposed method are 0.9869, 0.9894 and 0.9885, respectively. The indicators of this experiment have improved compared to previous methods.

| [1] |
C. Y. Cheung, D. Xu, C. Y. Cheng, C. Sabanayagam, T. Y. Wong, A deep-learning system for the assessment of cardiovascular disease risk via the measurement of retinal-vessel calibre, Nat. Biomed. Eng., 5 (2021), 498–508. https://doi.org/10.1038/s41551-020-00626-4 doi: 10.1038/s41551-020-00626-4

|
| [2] |
A. M. Mendonca, A. Campilho, Segmentation of retinal blood vessels by combining the detection of centerlines and morphological reconstruction, Ieee. T. Med. Imaging., 25 (2006), 1200–1213. https://doi.org/10.1109/tmi.2006.879955 doi: 10.1109/tmi.2006.879955
|
| [3] |
Y. Yin, M. Adel, S. Bourennane, Automatic segmentation and measurement of vasculature in retinal fundus images using probabilistic formulation, Comput. Math. Methods. Med., 2013 (2013), 260410. https://doi.org/10.1155/2013/260410 doi: 10.1155/2013/260410
|
| [4] | D. H. Ye, D. Kwon, I. D. Yun, S. U. Lee, Fast multiscale vessel enhancement filtering, in Proceedings of SPIE - The International Society for Optical Engineering, 6914 (2008), 691423. https://doi.org/10.1117/12.770038 |
| [5] |
I. Lázár, A. Hajdu, Segmentation of retinal vessels by means of directional response vector similarity and region growing, Comput. Biol. Med., 66 (2015), 209–221. https://doi.org/10.1016/j.compbiomed.2015.09.008 doi: 10.1016/j.compbiomed.2015.09.008
|
| [6] |
L. C. Neto, G. Ramalho, J. Neto, R. Veras, F. Medeiros, An unsupervised coarse-to-fine algorithm for blood vessel segmentation in fundus images, Expert. Syst. Appl, 78 (2017), 182–192. https://doi.org/10.1016/j.eswa.2017.02.015 doi: 10.1016/j.eswa.2017.02.015
|
| [7] |
U. Nguyen, A. Bhuiyan, L. Park, K. Ramamohanarao, An effective retinal blood vessel segmentation method using multi-scale line detection, Pattern. Recogn., 46 (2013), 703–715. https://doi.org/10.1016/j.patcog.2012.08.009 doi: 10.1016/j.patcog.2012.08.009
|
| [8] |
J. Staal, M.D. Abramoff, M. Niemeijer, M.A. Viergever, B. van Ginneken, Ridge-based vessel segmentation in color images of the retina, IEEE. T. Med. Imaging., 23 (2004), 501–509. https://doi.org/10.1109/TMI.2004.825627 doi: 10.1109/TMI.2004.825627
|
| [9] |
E. Ricci, R. Perfetti, Retinal blood vessel segmentation using line operators and support vector classification. IEEE. T. Med. Imaging., 26 (2007), 1357–1365. https://doi.org/10.1109/TMI.2007.898551 doi: 10.1109/TMI.2007.898551
|
| [10] |
S. Franklin, S. Rajan, Computerized screening of diabetic retinopathy employing blood vessel segmentation in retinal images, Biocybern. Biomed. Eng., 34 (2014), 117–124. https://doi.org/10.1016/j.bbe.2014.01.004 doi: 10.1016/j.bbe.2014.01.004
|
| [11] |
A. Krizhevsky, I. Sutskever, G. Hinton, ImageNet classification with deep convolutional neural networks, Commun. ACM, 60 (2017), 84–90. https://doi.org/10.1145/3065386 doi: 10.1145/3065386
|
| [12] | K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, Comput. Sci, 2014. https://doi.org/10.48550/arXiv.1409.1556 |
| [13] | C. Szegedy, W. Liu, Y. Jia, P. Sermanet, A. Rabinovich, Going deeper with convolutions, in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2015), 1–9. https://doi.org/10.1109/CVPR.2015.7298594 |
| [14] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2016), 770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [15] | G. Huang, Z. Liu, V. Laurens, K. Weinberger, Densely connected convolutional networks, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 2261–2269. https://doi.org/10.1109/CVPR.2017.243 |
| [16] | O. Ronneberger, P. Fischer, T. Brox, U-Net: Convolutional networks for biomedical image segmentation, in International Conference on Medical image computing and computer-assisted intervention, (2015), 234–241. https://doi.org/10.1007/978-3-319-24574-4_28 |
| [17] | Z. Zhou, M. Siddiquee, N. Tajbakhsh, J. Liang, UNet++: A nested U-Net architecture for medical image segmentation, Lecture Notes in Computer Science, Springer, Cham, 11045 (2018). https://doi.org/10.1007/978-3-030-00889-5_1 |
| [18] |
Q. Jin, Z. Meng, T. Pham, Q. Chen, L. Wei, R. Su, DUNet: A deformable network for retinal vessel segmentation, Know.-Based Syst., 178 (2019), 149–162. https://doi.org/10.1016/j.knosys.2019.04.025 doi: 10.1016/j.knosys.2019.04.025
|
| [19] | O. Oktay, J. Schlemper, L. Folgoc, M. Lee, M. Heinrich, K. Misawa, et al., Attention U-Net: Learning where to look for the pancreas, 2018. https://doi.org/10.48550/arXiv.1804.03999 |
| [20] |
J. Ding, Z. Zhang, J. Tang, F. Guo, A multichannel deep neural network for retina vessel segmentation via a fusion mechanism, Front. Bioeng. Biotechnol., 9 (2021), 663. https://doi.org/10.3389/fbioe.2021.697915 doi: 10.3389/fbioe.2021.697915
|
| [21] | X. Sun, X. Cao, Y. Yang, L. Wang, Y. Xu, Robust retinal vessel segmentation from a data augmentation perspective, Ophthalmic Medical Image Analysis, Lecture Notes in Computer Science, Springer, Cham, 12970 (2021), 189–198. https://doi.org/10.1007/978-3-030-87000-3_20 |
| [22] |
Z. Li, M. Jia, X. Yang, M. Xu, Blood vessel segmentation of retinal image based on Dense-U-Net Network, Micromachines, 12 (2021), 1478. https://doi.org/10.3390/mi12121478 doi: 10.3390/mi12121478
|
| [23] | M. Alom, M. Hasan, C. Yakopcic, T. Taha, V. K. Asari, Recurrent residual convolutional neural network based on U-Net (R2U-Net) for medical image segmentation, preprint, arXiv: 1802.06955. |
| [24] |
W. Liu, Y. Jiang, J. Zhang, Z. Ma, RFARN: Retinal vessel segmentation based on reverse fusion attention residual network, PLoS ONE, 16 (2021). https://doi.org/10.1371/journal.pone.0257256 doi: 10.1371/journal.pone.0257256
|
| [25] | Q. Yang, B. Ma, H. Cui, J. Ma, AMF-NET: Attention-aware multi-scale fusion network for retinal vessel segmentation, in 2021 43rd Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), (2021), 3277–3280. https://doi.org/10.1109/EMBC46164.2021.9630756 |
| [26] | J. Fu, J. Liu, H. Tian, Y. Li, Y. Bao, Z. Fang, et al., Dual attention network for scene segmentation, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, (2019), 3141–3149. https://doi.org/10.1109/CVPR.2019.00326 |
| [27] | I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, et al., Generative adversarial nets, in Proceedings of the 27th International Conference on Neural Information Processing Systems, 27 (2014), 2672–2680. https://doi.org/10.48550/arXiv.1406.2661 |
| [28] | M. Mirza, S. Osindero, Conditional generative adversarial nets, Comput. Therm. Sci., (2014), 2672–2680. https://doi.org/10.48550/arXiv.1411.1784 |
| [29] |
B. Lei, Z. Xia, F. Jiang, X. Jiang, S. Wang, Skin lesion segmentation via generative adversarial networks with dual discriminators, Med. Image. Anal., 64 (2020), 101716, https://doi.org/10.1016/j.media.2020.101716 doi: 10.1016/j.media.2020.101716
|
| [30] | A. Radford, L. Metz, S. Chintala, Unsupervised representation learning with deep convolutional generative adversarial networks, preprint, arXiv: 1511.06434. |
| [31] | P. Isola, JY. Zhu, T. Zhou, AA. Efros, Image-to-Image translation with conditional adversarial networks, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2017), 5967–5976. https://doi.org/10.1109/CVPR.2017.632 |
| [32] |
T. Yang, T. Wu, L. Li, C. Zhu, SUD-GAN: Deep convolution generative adversarial network combined with short connection and dense block for retinal vessel segmentation, J. Digit. Imaging., 33 (2020), 946–957. https://doi.org/10.1007/s10278-020-00339-9. doi: 10.1007/s10278-020-00339-9
|
| [33] |
J. Son, S. Park, K. Jung, Towards accurate segmentation of retinal vessels and the optic disc in fundoscopic images with generative adversarial networks, J. Digit. Imaging., 32 (2019), 499–512. https://doi.org/10.1007/s10278-018-0126-3 doi: 10.1007/s10278-018-0126-3
|
| [34] |
X. Dong, Y. Lei, T. Wang, M. Thomas, L. Tang, W. J. Curran, et al., Automatic multiorgan segmentation in thorax CT images using U-Net-GAN, Med. Phys., 46 (2019), 2157–2168. https://doi.org/10.1002/mp.13458 doi: 10.1002/mp.13458
|
| [35] |
J. Zhang, L. Yu, D. Chen, W. Pan, C. Shi, Y. Niu, et al., Dense GAN and multi-layer attention based lesion segmentation method for COVID-19 CT images, Biomed. Signal. Process. Control., 69 (2021), 102901. https://doi.org/10.1016/j.bspc.2021.102901 doi: 10.1016/j.bspc.2021.102901
|
| [36] |
A. You, J. Kim, I. Ryu, T. Yoo, Application of generative adversarial networks (GAN) for ophthalmology image domains: a survey, Eye. Vis. (Lond), 9 (2022), 1–19, https://doi.org/10.1186/s40662-022-00277-3 doi: 10.1186/s40662-022-00277-3
|
| [37] | V. Bellemo, P. Burlina, Y. Liu, T. Wong, D. Ting, Generative adversarial networks (GANs) for retinal fundus image synthesis, in Computer Vision – ACCV 2018 Workshops, Lecture Notes in Computer Science, Springer, Cham, 11367 (2018), 289–302. https://doi.org/10.1007/978-3-030-21074-8_24 |
| [38] | S. Kamran, K. Hossain, A. Tavakkoli, S. Zuckerbrod, K. Sanders, S. Baker, RV-GAN: Segmenting retinal vascular structure in fundus photographs using a novel multi-scale generative adversarial network, in MICCAI 2021: Medical Image Computing and Computer Assisted Intervention, Lecture Notes in Computer Science, Springer, 12908 (2021), 34–44. https://doi.org/10.1007/978-3-030-87237-3_4 |
| [39] | M. Alom, M. Hasan, C. Yakopcic, T. Taha, Inception recurrent convolutional neural network for object recognition, preprint, arXiv: 1704.07709. |
| [40] | M. Alom, M. Hasan, C. Yakopcic, T. Taha, V. Asari, Improved inception-residual convolutional neural network for object recognition, preprint, arXiv: 1712.09888. |
| [41] |
C. Owen, A. Rudnicka, R. Mullen, S. Barman, D. Monekosso, P. Whincup, et al., Measuring retinal vessel tortuosity in 10-year-old children: validation of the computer-assisted image analysis of the retina (CAIAR) program, Invest. Ophth. Vis. Sci., 50 (2009), 2004–2010. https://doi.org/10.1167/iovs.08-3018 doi: 10.1167/iovs.08-3018
|
| [42] |
A. D. Hoover, V. Kouznetsova, M. Goldbaum, Locating blood vessels in retinal images by piecewise threshold probing of a matched filter response, IEEE. T. Med. Imaging., 19 (2000), 203–210. https://doi.org/10.1109/42.845178 doi: 10.1109/42.845178
|
| [43] | C. Guo, M. Szemenyei, Y. Yi, W. Wang, B. Chen, C. Fan, SA-UNet: Spatial attention U-Net for retinal vessel segmentation, in 2020 25th International Conference on Pattern Recognition (ICPR), (2021), 1236–1242. https://doi.org/10.48550/arXiv.2004.03696 |
| [44] | J. Zhuang, LadderNet: Multi-path networks based on U-Net for medical image segmentation, preprint, arXiv: 1810.07810 |
| [45] | L. Li, M. Verma, Y. Nakashima, H. Nagahara, R. Kawasaki, Iternet: Retinal image segmentation utilizing structural redundancy in vessel networks, in 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), (2020), 3645–3654. https://doi.org/10.1109/WACV45572.2020.9093621 |
| [46] |
H. Ding, X. Cui, L. Chen, K. Zhao, MRU-Net: A U-shaped network for retinal vessel segmentation, Appl. Sci., 10 (2020), 6823. https://doi.org/10.3390/app10196823 doi: 10.3390/app10196823
|
| [47] |
D. Huang, L. Yin, H. Guo, W. Tang, T. Wan, FAU-Net: Fixup initialization channel attention neural network for complex blood vessel segmentation, Appl. Sci., 10 (2020), 6280. https://doi.org/10.3390/app10186280 doi: 10.3390/app10186280
|











Figures(12) / Tables(5)

Chen Yue, Mingquan Ye, Peipei Wang, Daobin Huang, Xiaojie Lu. SRV-GAN: A generative adversarial network for segmenting retinal vessels[J]. Mathematical Biosciences and Engineering, 2022, 19(10): 9948-9965. doi: 10.3934/mbe.2022464







 DownLoad:
DownLoad: